Scrapy框架采集微信公众号数据,机智操作绕过反爬验证码
前情提要此代码使用scrapy框架爬取特定“关键词”下的搜狗常规搜索结果 , 保存到同级目录下csv文件 。 并非爬取微信公众号文章 , 但是绕过验证码的原理相同 。 如有错误 , 希望大家指正 。
【Scrapy框架采集微信公众号数据,机智操作绕过反爬验证码】私信小编01即可获取大量Python学习资料
URL结构{关键词} --tt-darkmode-color: #979797;">开始爬取scrapy常规操作就不唠叨了 , 上代码
class SougouSearchSpider(scrapy.Spider):name = 'sogou_search'allowed_domains = ['www.sogou.com']start_urls = ['python --tt-darkmode-color: #999999;">一顿操作后 , 发现刚爬了3页 , 就停止了 。 报错如下
2020-06-11 16:05:15 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to 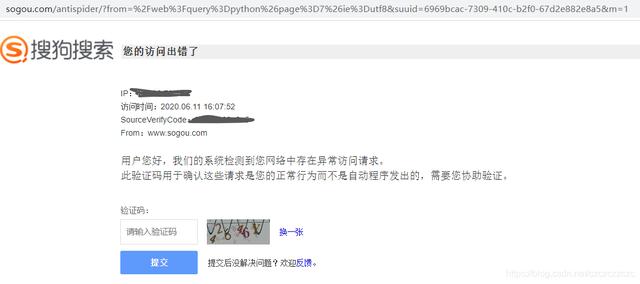 文章插图
文章插图
看到这里 , 我们采取一下常规措施:1.更换动态IP2.伪装header3.硬刚破解验证码
一步一步来 , 我们先更换IP 。 这里我使用的是使用Redis的免费代理IP池:ProxyPool , Github地址 。 非常nice , 代码十分简练 。
import requestsproxypool_url = ''def get_random_proxy():response = requests.get(proxypool_url)try:if response.status_code == 200:return response.text.strip()except ConnectionError:return None遗憾的是 , 只换IP不太行 , 还是会被302到antispider页面 。 接下来 , 我们伪装一下header , 先看一下request.header 。 手动搜索 , 然后F12查看 。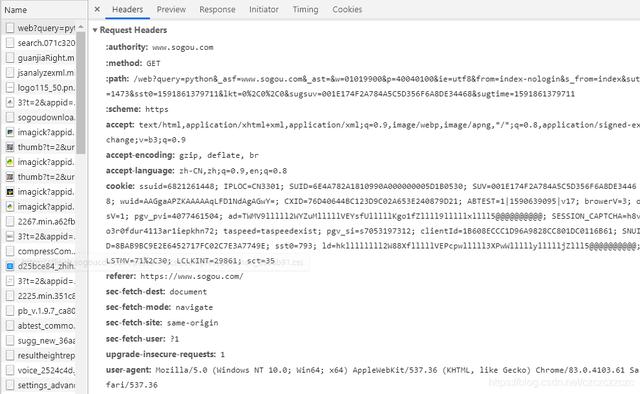 文章插图
文章插图
user-agent可以由fake_useragent随机生成 , Github地址 。 难的是cookies 。
ssuid=6821261448; IPLOC=CN3301; SUID=6E4A782A1810990A000000005D1B0530; SUV=001E174F2A784A5C5D356F6A8DE34468; wuid=AAGgaAPZKAAAAAqLFD1NdAgAGwY=; CXID=76D40644BC123D9C02A653E240879D21; ABTEST=1|1590639095|v17; browerV=3; osV=1; pgv_pvi=4077461504; ad=TWMV9lllll2WYZuMlllllVEYsfUlllllKgo1fZllll9lllllxllll5@@@@@@@@@@; pgv_si=s7053197312; clientId=1B608ECCC1D96A9828CC801DC0116B61; SNUID=8BAB9BC9E2E6452717FC02C7E3A7749E; ld=VZllllllll2W88XflllllVEPcwylllll3XPwWlllllUllllljZlll5@@@@@@@@@@; sst0=711; LSTMV=190%2C728; LCLKINT=2808800; sct=36多访问几个网页 , 查看参数变化 。 然后发现重要的参数只有两个
SUV=001E174F2A784A5C5D356F6A8DE34468;SNUID=8BAB9BC9E2E6452717FC02C7E3A7749E;然后我就带着这两个参数的cookies去访问了 , 虽然多爬了2页 , 但是很快遇到了antispider 。
然后我就想我每访问一页 , 换一组cookies , 行不行?
机智操作登场突然想到 , 搜狗是一个大家族 , 我访问其他搜狗页面 , 比如搜狗视频 , 应该也能拿到cookies 。
def get_new_cookies(): # 搜狗视频urlurl = ';query= --tt-darkmode-color: #999999;">果不其然 , 得到了想要的cookies:
{'IPLOC': 'CN3301', 'SNUID': '13320250797FDDB3968937127A18F658', 'SUV': '00390FEA2A7848695EE1EE6630A8C887', 'JSESSIONID': 'aaakft_AlKG3p7g_ZIIkx'}多打印了几次 , 每次的cookies值都不一样 。 这就OK了 , 马上放进scrapy 。
大功告成我尝试了每3秒爬一个网页 , 运行两小时 , 没触发antispider!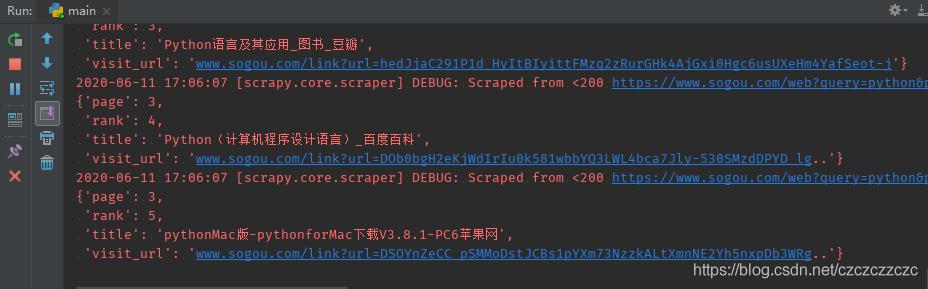 文章插图
文章插图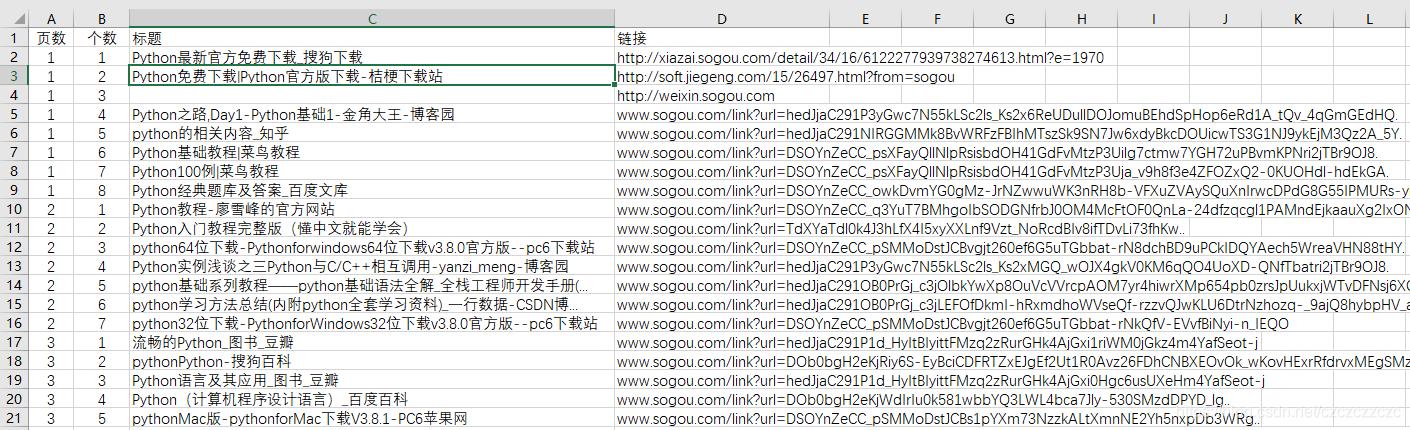 文章插图
文章插图
这样就满足我的需求了 , 就没有硬刚破解验证码 。 当然对接第三方打码平台很容易 , 就不多说了 。 如果你嫌弃慢的话 , 可以缩短时间间隔 。
完整代码如下sougou_search.py
# coding=utf-8from sougou_search_spider.items import SougouSearchSpiderItemfrom IP.free_ip import get_random_proxyfrom IP.get_cookies import get_new_cookies,get_new_headersimport scrapyimport timeimport randomclass SougouSearchSpider(scrapy.Spider):name = 'sogou_search'allowed_domains = ['www.sogou.com']start_urls = ['python']def start_requests(self):headers = get_new_headers()for url in self.start_urls:# 获取代理IPproxy = 'http://' + str(get_random_proxy())yield scrapy.Request(url=url,callback=self.parse,headers=headers,meta={'http_proxy': proxy})def parse(self, response):headers_new = get_new_headers()cookies_new = get_new_cookies()# 获取当前页码current_page = int(response.xpath('//div[@id="pagebar_container"]/span/text()').extract_first())# 解析当前页面for i, a in enumerate(response.xpath('//div[contains(@class,"vrwrap")]/h3[@class="vrTitle"]/a')):# 获取标题 , 去除空格和换行符title = ''.join(a.xpath('./em/text() | ./text()').extract()).replace(' ', '').replace('\n', '')if title:item = SougouSearchSpiderItem()# 获取访问链接(①非跳转链接②跳转链接)、页码、行数、标题if a.xpath('@href').extract_first().startswith('/link'):item['visit_url'] = 'www.sogou.com' + a.xpath('@href').extract_first()# 提取链接else:item['visit_url'] = a.xpath('@href').extract_first()item['page'] = current_pageitem['rank'] = i + 1item['title'] = titleyield item# 控制爬取频率time.sleep(random.randint(8, 10))# 获取“下一页”的链接p = response.xpath('//div[@id="pagebar_container"]/a[@id="sogou_next"]')if p:p_url = '' + str(p.xpath('@href').extract_first())proxy = 'http://' + str(get_random_proxy())yield scrapy.Request(url=p_url,callback=self.parse,headers=headers_new,cookies=cookies_new,meta={'http_proxy': proxy})
- 框架|三种数据分析思维框架的构建方法
- Python爬虫采集网易云音乐热评实战
- 整理:常见的Java开发框架有哪些,看过,就赶紧收藏吧
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 在Linux系统中安装深度学习框架Pytorch
- 案例:如何使用接口测试框架Karate创建一个API测试?
- 常用的NIO框架-Netty
- SpreadJS 表格控件应用:MHT-CP数据填报采集平台
- Python|TensorFlow 、Caffe等9大主流人工智能框架优劣势分析
- 商园|如何批量采集网商园多个商品主图素材