为什么指针被誉为 C 语言灵魂?( 四 )
只能存放 int* 型变量的地址 。
对于二级指针甚至多级指针 , 我们都可以把它拆成两部分 。
首先不管是多少级的指针变量 , 它首先是一个指针变量 , 指针变量就是一个* , 其余的*表示的是这个指针变量只能存放什么类型变量的地址 。
比如int****a表示指针变量 a 只能存放int*** 型变量的地址 。 文章插图
文章插图
指针与数组5.1 一维数组数组是 C 自带的基本数据结构 , 彻底理解数组及其用法是开发高效应用程序的基础 。
数组和指针表示法紧密关联 , 在合适的上下文中可以互换 。
如下:
1int array[10] = {10, 9, 8, 7};
2printf("%d\n", *array); // 输出 10
3printf("%d\n", array[0]); // 输出 10
4
5printf("%d\n", array[1]); // 输出 9
6printf("%d\n", *(array+1)); // 输出 9
7
8int *pa = array;
9printf("%d\n", *pa); // 输出 10
10printf("%d\n", pa[0]); // 输出 10
11
12printf("%d\n", pa[1]); // 输出 9
13printf("%d\n", *(pa+1)); // 输出 9
在内存中 , 数组是一块连续的内存空间: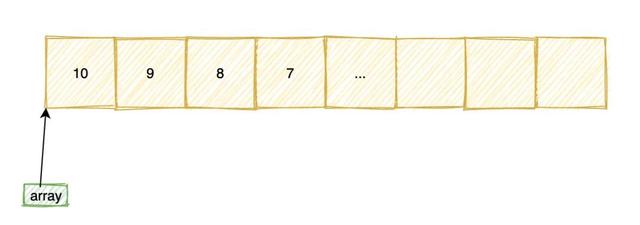 文章插图
文章插图
第 0 个元素的地址称为数组的首地址 , 数组名实际就是指向数组首地址 , 当我们通过array[1]或者*(array + 1) 去访问数组元素的时候 。
实际上可以看做 address[offset] , address 为起始地址 , offset 为偏移量 , 但是注意这里的偏移量offset 不是直接和 address相加 , 而是要乘以数组类型所占字节数 , 也就是:address + sizeof(int) * offset 。
学过汇编的同学 , 一定对这种方式不陌生 , 这是汇编中寻址方式的一种:基址变址寻址 。
看完上面的代码 , 很多同学可能会认为指针和数组完全一致 , 可以互换 , 这是完全错误的 。
尽管数组名字有时候可以当做指针来用 , 但数组的名字不是指针 。
最典型的地方就是在 sizeof:
1printf("%u", sizeof(array));2printf("%u", sizeof(pa));
第一个将会输出 40 , 因为 array包含有 10 个int类型的元素 , 而第二个在 32 位机器上将会输出 4 , 也就是指针的长度 。
为什么会这样呢?
站在编译器的角度讲 , 变量名、数组名都是一种符号 , 它们都是有类型的 , 它们最终都要和数据绑定起来 。
变量名用来指代一份数据 , 数组名用来指代一组数据(数据集合) , 它们都是有类型的 , 以便推断出所指代的数据的长度 。
对 , 数组也有类型 , 我们可以将 int、float、char 等理解为基本类型 , 将数组理解为由基本类型派生得到的稍微复杂一些的类型 ,
数组的类型由元素的类型和数组的长度共同构成 。 而 sizeof 就是根据变量的类型来计算长度的 , 并且计算的过程是在编译期 , 而不会在程序运行时 。
编译器在编译过程中会创建一张专门的表格用来保存变量名及其对应的数据类型、地址、作用域等信息 。
sizeof 是一个操作符 , 不是函数 , 使用 sizeof 时可以从这张表格中查询到符号的长度 。
所以 , 这里对数组名使用sizeof可以查询到数组实际的长度 。
pa 仅仅是一个指向 int 类型的指针 , 编译器根本不知道它指向的是一个整数 , 还是一堆整数 。
虽然在这里它指向的是一个数组 , 但数组也只是一块连续的内存 , 没有开始和结束标志 , 也没有额外的信息来记录数组到底多长 。
所以对 pa 使用 sizeof 只能求得的是指针变量本身的长度 。
也就是说 , 编译器并没有把 pa 和数组关联起来 , pa 仅仅是一个指针变量 , 不管它指向哪里 , sizeof求得的永远是它本身所占用的字节数 。
5.2 二维数组大家不要认为二维数组在内存中就是按行、列这样二维存储的 , 实际上 , 不管二维、三维数组... 都是编译器的语法糖 。
存储上和一维数组没有本质区别 , 举个例子:
1int array[3][3] = {{1, 2 , 3}, {4, 5 , 6} , {7, 8, 9}};2array[1][1] = 5;
或许你以为在内存中 array 数组会像一个二维矩阵:
11 2 3
24 5 6
37 8 9
可实际上它是这样的:
11 2 3 4 5 6 7 8 9
和一维数组没有什么区别 , 都是一维线性排列 。
当我们像 array[1][1]这样去访问的时候 , 编译器会怎么去计算我们真正所访问元素的地址呢?
为了更加通用化 , 假设数组定义是这样的:
int array[n][m]
访问: array[a][b]
那么被访问元素地址的计算方式就是: array + (m * a + b)
这个就是二维数组在内存中的本质 , 其实和一维数组是一样的 , 只是语法糖包装成一个二维的样子 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?
- 团队|为什么项目管理非常重要?
- 猫腻|为什么拼多多上商品价格那么便宜还包邮?有什么猫腻?看完明白了
- 刷机|前几年满大街的“刷机”服务去哪里了,为什么大家都不爱刷机了?
- 手机|便宜没好货!为什么二手iPhone很便宜,这些手机都来自哪儿?
- 中国|相对论Vol.48丨一个“歪果仁”,为什么要在海外电商平台直播带中国货