词嵌入教程( 二 )
# Keras的标识器from keras.preprocessing.text import Tokenizertk = Tokenizer(num_words = vocab_size)tk.fit_on_texts(X_train)X_train = tk.texts_to_sequences(X_train)X_test = tk.texts_to_sequences(X_test)# 用0填充所有from keras.preprocessing.sequence import pad_sequencesX_train_seq = pad_sequences(X_train, maxlen = sequence_length, padding = 'post')X_test_seq = pad_sequences(X_test, maxlen = sequence_length, padding = 'post')3) 训练嵌入层最后 , 在这一部分中 , 我们将构建和训练我们的模型 , 它由两个主要层组成 , 一个嵌入层将学习上面准备的训练文档 , 以及一个密集的输出层来实现分类任务 。
嵌入层将学习单词的表示 , 同时训练神经网络 , 需要大量的文本数据来提供准确的预测 。 在我们的例子中 , 45000个训练观察值足以有效地学习语料库并对问题的质量进行分类 。 我们将从指标中看到 。
# 训练嵌入层和神经网络from keras.models import Sequentialfrom keras.layers import Embedding, Dense, Flattenmodel = Sequential()model.add(Embedding(input_dim = vocab_size, output_dim = 5, input_length = sequence_length))model.add(Flatten())model.add(Dense(units = 3, activation = 'softmax'))model.compile(loss = 'categorical_crossentropy',optimizer = 'rmsprop',metrics = ['accuracy'])model.summary()history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)# 完成训练后保存模型#model.save("model.h5")4) 评估和度量图剩下的就是评估我们的模型的性能 , 并绘制图来查看模型的准确性和损失指标是如何随时间变化的 。
我们模型的性能指标显示在下面的屏幕截图中 。 文章插图
文章插图
代码与下面显示的代码相同 。
# 在测试集上评估模型的性能loss, accuracy = model.evaluate(X_test_seq, y_test, verbose = 1)print("\nAccuracy: {}\nLoss: {}".format(accuracy, loss))# 画出准确度和损失sb.set_style('darkgrid')# 1) 准确度plt.plot(history.history['accuracy'], label = 'training', color = '#003399')plt.legend(shadow = True, loc = 'lower right')plt.title('Accuracy Plot over Epochs')plt.show()# 2) 损失plt.plot(history.history['loss'], label = 'training loss', color = '#FF0033')plt.legend(shadow = True, loc = 'upper right')plt.title('Loss Plot over Epochs')plt.show()以下是训练中准确度的提高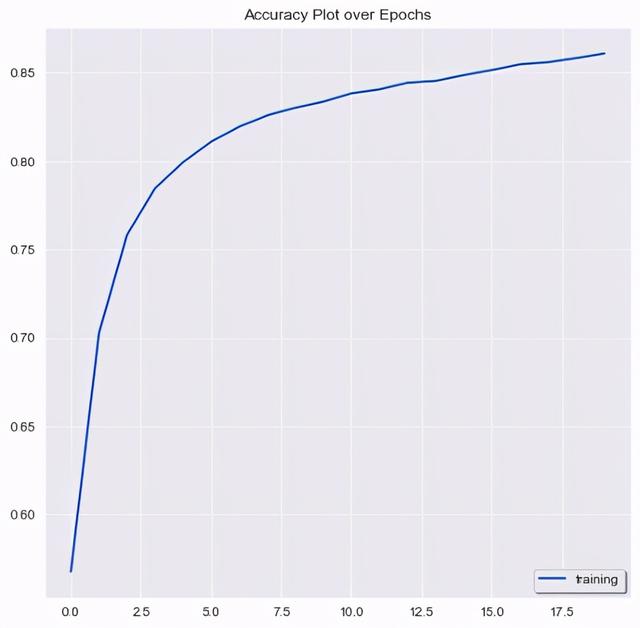 文章插图
文章插图
20个epoch的损失图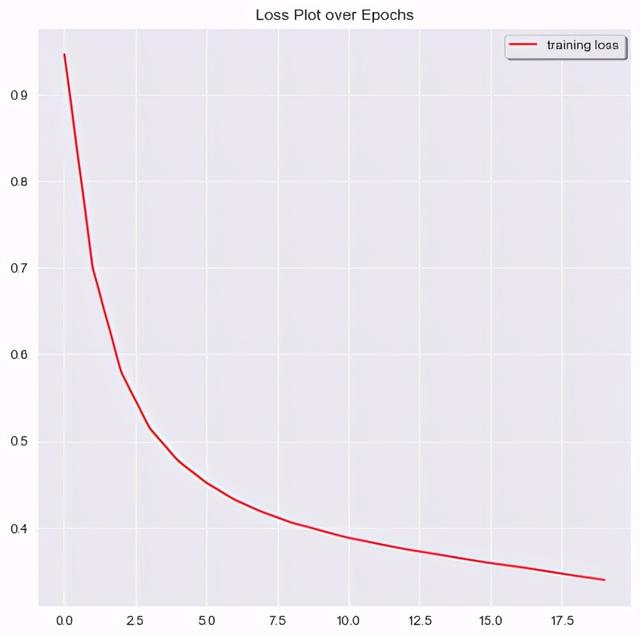 文章插图
文章插图
2.预训练的GloVe词嵌入如果你只想运行模型 , 这里有完整的代码:
代替训练你自己的嵌入 , 另一个选择是使用预训练好的词嵌入 , 比如GloVe或Word2Vec 。 在这一部分中 , 我们将使用在Wikipedia+gigaword5上训练的GloVe词嵌入;从这里下载:
i) 选择一个预训练的词嵌入 , 如果你的数据集是由更“通用”的语言组成的 , 一般来说你没有那么大的数据集 。
由于这些嵌入已经根据来自不同来源的大量单词进行了训练 , 如果你的数据也是通用的 , 那么预训练的模型可能会做得很好 。
此外 , 通过预训练的嵌入 , 你可以节省时间和计算资源 。
ii)选择训练你自己的嵌入 , 如果你的数据(和项目)是基于一个利基行业 , 如医药、金融或任何其他非通用和高度特定的领域 。
在这种情况下 , 一般的词嵌入表示法可能不适合你 , 并且一些单词可能不在词汇表中 。
需要大量的领域数据来确保所学的词嵌入能够正确地表示不同的单词以及它们之间的语义关系
此外 , 它需要大量的计算资源来浏览你的语料库和建立词嵌入 。
最终 , 是根据已有的数据训练你自己的嵌入 , 还是使用预训练好的嵌入 , 将取决于你的项目 。
显然 , 你仍然可以试验这两种模型 , 并选择一种精度更高的模型 , 但上面的教程只是一个简化的教程 , 可以帮助你做出决策 。
过程前面的部分已经采取了所需的大部分步骤 , 只需进行一些调整 。
我们只需要构建一个单词及其向量的嵌入矩阵 , 然后用它来设置嵌入层的权重 。
所以 , 保持预处理、标识化和填充步骤不变 。
一旦我们导入了原始数据集并运行了前面的文本清理步骤 , 我们将运行下面的代码来构建嵌入矩阵 。
以下决定要嵌入多少个维度(50、100、200) , 并将其名称包含在下面的路径变量中 。
# # 导入嵌入path = 'Full path to your glove file (with the dimensions)'embeddings = dict()with open(path, 'r', encoding = 'utf-8') as f:for line in f:# 文件中的每一行都是一个单词外加50个数(表示这个单词的向量)values = line.split()# 每一行的第一个元素是一个单词 , 其余的50个是它的向量embeddings[values[0]] = np.array(values[1:], 'float32')# 设置一些参数vocab_size = 2100glove_dim = 50sequence_length = 200# 从语料库中的单词构建嵌入矩阵embedding_matrix = np.zeros((vocab_size, glove_dim))for word, index in word_index.items():if index
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- 首创|网易有道词典笔3发布:首创毫秒级超快点查、识别率超98%
- 直播从业者|高三老师监考时开直播,面对质疑还振振有词,怕困没有打扰学生
- 云图|不会制作词云图?我来教你
- 范文|“2020年十大网络热词” 新鲜出炉(附高分范文)
- 快点|有道词典笔3上市,推出超快点查、互动点读两项新功能
- 有道词典笔3正式上市:推出超快点查、互动点读两大创新功能
- 互动|有道词典笔3正式上市:推出超快点查、互动点读两大创新功能
- 搜违禁词将出现公益宣导页 看“绿网计划”如何打造安全网
- 有道再推词典笔,硬件成在线教育流量入口?