每个数据科学家都需要的3种简单的异常检测算法( 三 )
Boxplots如何工作本质上 , 箱形图通过将数据集分为5部分来工作: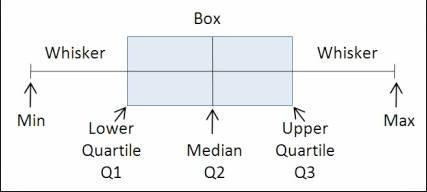 文章插图
文章插图
> Photo from StackOverflow
· 最小值:分布中的最低数据点 , 不包括任何异常值 。
· 最大值:分布中的最高数据点 , 不包括任何异常值 。
· 中位数(Q2 / 50%):数据集的中间值 。
· 第一个四分位数(Q1 / 25个百分点):是数据集下半部分的中位数 。
· 第三四分位数(Q3 /第75个百分位数):是数据集上半部分的中位数 。
四分位间距(IQR)很重要 , 因为它定义了异常值 。本质上 , 它是以下内容:
IQR = Q3 - Q1
Q3: third quartile
Q1: first quartile
在箱图中 , 测得的距离为1.5 * IQR , 并包含数据集的较高观测点 。类似地 , 在数据集的较低观察点上测得的距离为1.5 * IQR 。这些距离之外的任何值都是异常值 。进一步来说:
· 如果观测点低于(Q1-1.5 * IQR)或箱线图下部晶须 , 则将其视为异常值 。
· 同样 , 如果观测点高于(Q3 + 1.5 * IQR)或箱线图上晶须 , 则它们也被视为离群值 。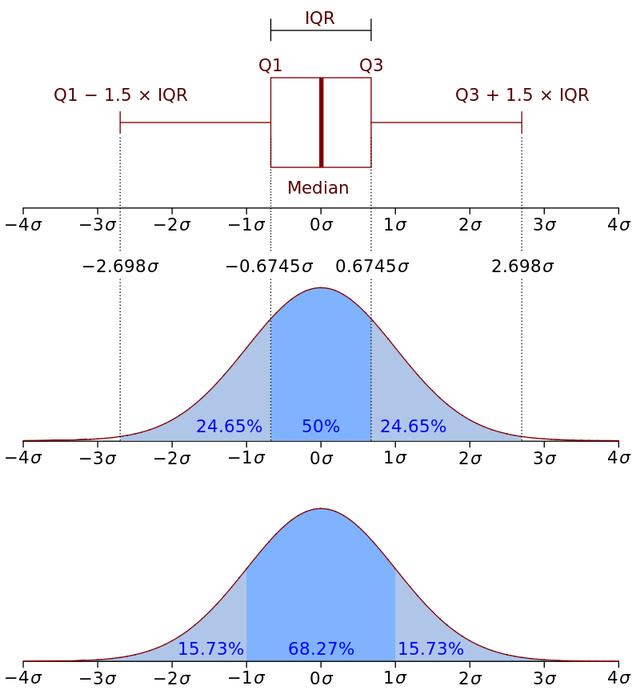 文章插图
文章插图
> Photo By Wikipedia
箱线图在行动让我们看看如何在Python中使用Boxplots检测离群值!
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
X = np.array([45,56,78,34,1,2,67,68,87,203,-200,-150])
y = np.array([1,1,0,0,1,0,1,1,0,0,1,1])
让我们绘制数据的箱线图:
sns.boxplot(X)
plt.show()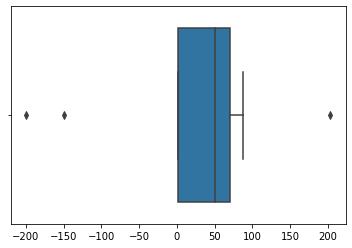 文章插图
文章插图
> Photo By Author
因此 , 根据箱线图 , 我们看到我们的数据中位数为50和3个离群值 。让我们摆脱这些要点:
X = X[(X < 150) & (X > -50)]
sns.boxplot(X)
plt.show()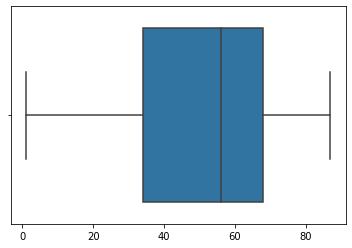 文章插图
文章插图
> Photo By Author
在这里 , 我基本上设置了一个阈值 , 以便将所有小于-50和大于150的点都排除在外 。结果 分布均匀!
Tukey方法离群值检测曲棍球方法离群值检测实际上是箱形图的非可视方法; 除了没有可视化之外 , 方法是相同的 。
我有时喜欢这种方法而不是箱线图的原因是因为有时看一下可视化并粗略估计应将阈值设置为什么 , 实际上并没有效果 。
相反 , 我们可以编写一种算法 , 该算法实际上可以返回它定义为异常值的实例 。
该实现的代码如下:
import numpy as np
from collections import Counter
def detect_outliers(df, n, features):
# list to store outlier indices
outlier_indices = []
# iterate over features(columns)
for col in features:
# Get the 1st quartile (25%)
Q1 = np.percentile(df[col], 25)
# Get the 3rd quartile (75%)
Q3 = np.percentile(df[col], 75)
# Get the Interquartile range (IQR)
IQR = Q3 - Q1
# Define our outlier step
outlier_step = 1.5 * IQR
# Determine a list of indices of outliers
outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step)].index
# append outlier indices for column to the list of outlier indices
outlier_indices.extend(outlier_list_col)
# select observations containing more than 2 outliers
outlier_indices = Counter(outlier_indices)
multiple_outliers = list(k for k, v in outlier_indices.items() if v > n)
return multiple_outliers
# detect outliers from list of features
list_of_features = ['x1', 'x2']
# params dataset, number of outliers for rejection, list of features
Outliers_to_drop = detect_outliers(dataset, 2, list_of_features)
基本上 , 此代码执行以下操作:
· 对于每个功能 , 它都会获得:
· 第一四分位数
· 第三四分位数
· IQR
2.接下来 , 它定义离群值步骤 , 就像在箱图中一样 , 为1.5 * IQR
3.通过以下方式检测异常值:
· 查看观察点是否
4.然后检查选择的观察值具有k个异常值(在这种情况下 , k = 2)
结论总而言之 , 存在许多离群值检测算法 , 但是我们经历了3种最常见的算法:DBSCAN , IsolationForest和Boxplots 。我鼓励您:
· 在"泰坦尼克号"数据集上尝试这些方法 。哪一个最能检测到异常值?
· 寻找其他异常检测方法 , 看看它们的性能比最初尝试得更好还是更差 。
我真的很感谢我的追随者 , 并希望不断写信并给予大家深思熟虑的食物 。但是 , 现在 , 我必须说再见;} 文章插图
文章插图
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 月入|一上网,感觉网上每个人都是月入过万,到底是错觉还是你out了?
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元