每个数据科学家都需要的3种简单的异常检测算法( 二 )
dbscan.labels_
OUT:array([ 0, 2, -1, -1, 1, 0, 0, 0, ..., 3, 2, 3, 3, 4, 2, 6, 3])
请注意一些标签的值如何等于-1:这些是离群值 。
DBSCAN没有预测方法 , 只有fit_predict方法 , 这意味着它无法对新实例进行聚类 。相反 , 我们可以使用其他分类器进行训练和预测 。在此示例中 , 我们使用KNN:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])
X_new = np.array([[-0.5, 0], [0, 0.5], [1, -0.1], [2, 1]])
knn.predict(X_new)
OUT:array([1, 0, 1, 0])
在这里 , 我们将KNN分类器适合核心样本及其各自的邻居 。
但是 , 我们遇到了一个问题 。我们提供的KNN数据没有任何异常值 。这是有问题的 , 因为它将迫使KNN为新实例选择群集 , 即使新实例确实是异常值 。
为了解决这个问题 , 我们利用了KNN分类器的kneighbors方法 , 该方法在给定一组实例的情况下 , 返回训练集的k个最近邻居的距离和索引 。然后 , 我们可以设置最大距离 , 如果实例超过该距离 , 我们会将其限定为离群值:
y_dist, y_pred_idx = knn.kneighbors(X_new, n_neighbors=1)
y_pred = dbscan.labels_[dbscan.core_sample_indices_][y_pred_idx]
y_pred[y_dist > 0.2] = -1y_pred.ravel()
OUT:array([-1, 0, 1, -1])
在这里 , 我们已经讨论并实现了用于异常检测的DBSCAN 。DBSCAN很棒 , 因为它速度快 , 只有两个超参数并且对异常值具有鲁棒性 。
解决方案2:IsolationForest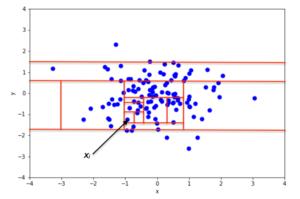 文章插图
文章插图
> Photo By Author
IsolationForest是一种集成学习异常检测算法 , 在检测高维数据集中的异常值时特别有用 。该算法基本上执行以下操作:
· 它创建了一个随机森林 , 其中决策树是随机增长的:在每个节点上 , 特征都是随机选择的 , 并且它选择一个随机阈值将数据集一分为二 。
· 它会继续砍掉数据集 , 直到所有实例最终相互隔离 。
· 异常通常与其他实例相距甚远 , 因此 , 平均而言(在所有决策树中) , 与正常实例相比 , 异常隔离的步骤更少 。
行动中的森林同样 , 借助Scikit-Learn直观的API , 我们可以轻松实现IsolationForest类 。让我们看一个实际的算法示例:
from sklearn.ensemble import IsolationForest
from sklearn.metrics import mean_absolute_error
import pandas as pd
我们还将导入mean_absolute_error来衡量我们的错误 。对于数据 , 我们将使用可从Jason Brownlee的GitHub获得的数据集:
url=''
df = pd.read_csv(url, header=None)
data = http://kandian.youth.cn/index/df.values
# split into input and output elements
X, y = data[:, :-1], data[:, -1]
在拟合隔离森林之前 , 让我们尝试在数据上拟合香草线性回归模型并获得MAE:
from sklearn.linear_model import LinearRegression
lr =LinearRegression()
lr.fit(X,y)
mean_absolute_error(lr.predict(X),y)
OUT:3.2708628109003177
分数比较好 。现在 , 让我们看看隔离林是否可以通过消除异常来提高得分!
首先 , 我们将实例化IsolationForest:
iso = IsolationForest(contamination='auto',random_state=42)
该算法中最重要的超参数可能是污染参数 , 该污染参数用于帮助估计数据集中的异常值 。这是介于0.0和0.5之间的值 , 默认情况下设置为0.1
但是 , 它本质上是随机的随机森林 , 因此随机森林的所有超参数也可以在算法中使用 。
接下来 , 我们将数据拟合到算法中:
y_pred = iso.fit_predict(X,y)
mask = y_pred != -1
请注意 , 我们如何也过滤掉预测值= -1 , 就像在DBSCAN中一样 , 这些被认为是离群值 。
现在 , 我们将使用异常值过滤后的数据重新分配X和Y:
X,y = X[mask,:],y[mask]
现在 , 让我们尝试将线性回归模型拟合到数据中并测量MAE:
lr.fit(X,y)
mean_absolute_error(lr.predict(X),y)
OUT:2.643367450077622
哇 , 成本大大降低了 。这清楚地展示了隔离林的力量 。
解决方案3:Boxplots + Tuckey方法虽然Boxplots是识别异常值的一种常见方法 , 但我确实发现 , 后者可能是识别异常值的最被低估的方法 。但是在我们进入" Tuckey方法"之前 , 让我们先谈一下Boxplots:
箱线图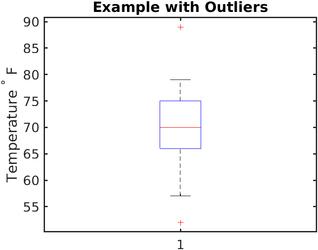 文章插图
文章插图
> Photo By Wikipedia
箱线图实质上提供了一种通过分位数显示数值数据的图形方式 , 这是一种非常简单但有效的可视化异常值的方式 。
上下晶须显示了分布的边界 , 任何高于或低于此的值都被认为是异常值 。在上图中 , 高于?80和低于?62的任何值都被认为是异常值 。
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 月入|一上网,感觉网上每个人都是月入过万,到底是错觉还是你out了?
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元