每个数据科学家都需要的3种简单的异常检测算法
深入了解离群值检测以及如何在Python中实现3个简单 , 直观且功能强大的离群值检测算法 文章插图
文章插图
> Photo By Scott.T on Flickr
我确定您遇到以下几种情况:
· 您的模型表现不理想 。
· 您不禁会注意到有些地方似乎与其他地方有很大的不同 。
恭喜 , 因为您的数据中可能包含异常值!
什么是离群值?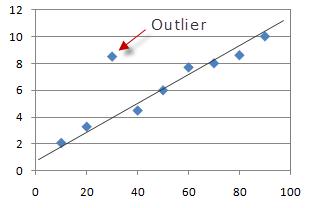 文章插图
文章插图
> Photo can be found in StackExchange
在统计中 , 离群点是与其他观察值有显着差异的数据点 。从上图可以清楚地看到 , 尽管大多数点都位于线性超平面内或周围 , 但可以看到单个点与其余超散点不同 。这是一个离群值 。
例如 , 查看下面的列表:
[1,35,20,32,40,46,45,4500]
在这里 , 很容易看出1和4500在数据集中是异常值 。
为什么我的数据中有异常值?通常 , 异常可能发生在以下情况之一:
· 有时可能由于测量错误而偶然发生 。
· 有时它们可能会出现在数据中 , 因为在没有异常值的情况下 , 数据很少是100%干净的 。
为什么离群值有问题?原因如下:
· 线性模型
假设您有一些数据 , 并且想使用线性回归从中预测房价 。可能的假设如下所示: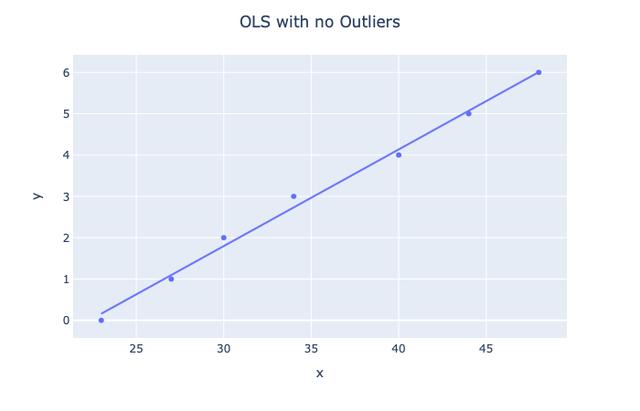 文章插图
文章插图
> Source: http> Photo By Authors://arxiv.org/pdf/1811.06965.pdf
在这种情况下 , 我们实际上将数据拟合得太好(过度拟合) 。但是 , 请注意所有点的位置大致在同一范围内 。
现在 , 让我们看看添加异常值时会发生什么 。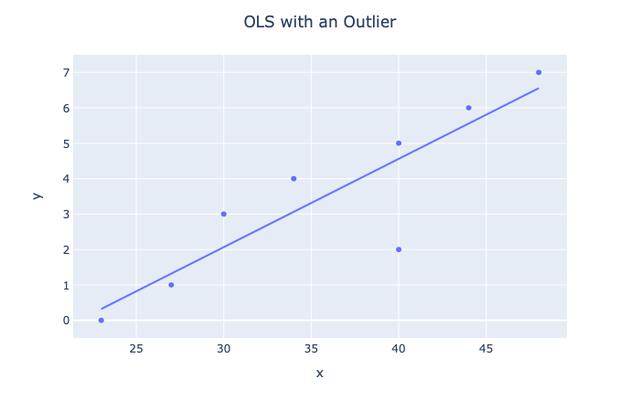 文章插图
文章插图
> Photo By Author
显然 , 我们看到了假设的变化 , 因此 , 如果没有异常值 , 推断将变得更加糟糕 。线性模型包括:
· 感知器
· 线性+ Logistic回归
· 神经网络
· 知识网络
2.数据插补 文章插图
文章插图
> Photo by Ehimetalor Akhere Unuabona on Unsplash
常见的情况是缺少数据 , 可以采用以下两种方法之一:
· 删除缺少行的实例
· 使用统计方法估算数据
如果我们选择第二种方法 , 我们可能会得出有问题的推论 , 因为离群值会极大地改变统计方法的值 。例如 , 回到没有异常值的虚构数据:
# Data with no outliers
np.array([35,20,32,40,46,45]).mean() = 36.333333333333336
# Data with 2 outliers
np.array([1,35,20,32,40,46,45,4500]).mean() = 589.875
显然 , 这种类比是极端的 , 但是想法仍然相同 。我们数据中的异常值通常是一个问题 , 因为异常值会在统计分析和建模中引起严重的问题 。但是 , 在本文中 , 我们将探讨几种检测和打击它们的方法 。
解决方案1:DBSCAN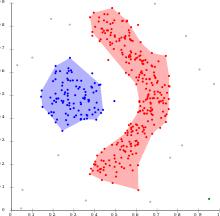 文章插图
文章插图
> Photo By Wikipedia
像KMeans一样 , 带有噪声(或更简单地说是DBSCAN)的应用程序的基于密度的空间聚类实际上是一种无监督的聚类算法 。但是 , 其用途之一还在于能够检测数据中的异常值 。
DBSCAN之所以受欢迎 , 是因为它可以找到非线性可分离的簇 , 而KMeans和高斯混合无法做到这一点 。当簇足够密集且被低密度区域隔开时 , 它会很好地工作 。
DBSCAN工作原理的高级概述该算法将群集定义为高密度的连续区域 。该算法非常简单:
· 对于每个实例 , 它计算在距它的小距离ε(ε)内有多少个实例 。该区域称为实例的ε社区 。
· 如果该实例在其ε邻域中有多个min_samples个实例 , 则将其视为核心实例 。这意味着实例位于高密度区域(内部有很多实例的区域) 。
· 核心实例的ε邻域内的所有实例都分配给同一群集 。这可能包括其他核心实例 , 因此相邻核心实例的单个长序列形成单个群集 。
· 不是核心实例或不在任何核心实例的ε邻居中的任何实例都是异常值 。
DBSCAN实战借助Scikit-Learn直观的API , DBSCAN算法非常易于使用 。让我们看一个实际的算法示例:
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05)
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan.fit(X)
在这里 , 我们将实例化一个具有ε邻域长度为0.05的DBSCAN , 并将5设为实例被视为核心实例所需的最小样本数
请记住 , 我们不传递标签 , 因为它是无监督的算法 。我们可以使用以下命令查看标签 , 即算法生成的标签:
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 月入|一上网,感觉网上每个人都是月入过万,到底是错觉还是你out了?
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元