图文并茂:HashMap经典详解( 二 )
bucketIndex = indexFor(hash, table.length);//indexFor的代码也很简单 , 就是把散列值和数组长度做一个"与"操作 , static int indexFor(int h, int length) {return h }顺便说一下 , 这也正好解释了为什么 HashMap 的数组长度要取 2 的整次幂 。 因为这样(数组长度?1)正好相当于一个 “低位掩码” 。 “与” 操作的结果就是散列值的高位全部归零 , 只保留低位值 , 用来做数组下标访问 。 以初始长度 16 为例 , 16?1=15 。 2 进制表示是 00000000 0000000000001111 。 和某散列值做 “与” 操作如下 , 结果就是截取了最低的四位值 。
10100101 11000100 00100101 --tt-darkmode-color: #50616D;">但这时候问题就来了 , 这样就算我的散列值分布再松散 , 要是只取最后几位的话 , 碰撞也会很严重 。 更要命的是如果散列本身做得不好 , 分布上成等差数列的漏洞 , 恰好使最后几个低位呈现规律性重复 , 就无比蛋疼 。 这时候 “扰动函数” 的价值就出来了 , 说到这大家应该都明白了 , 看下图 。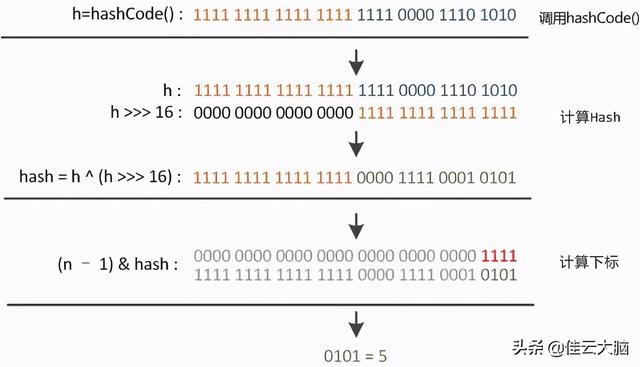 文章插图
文章插图
右位移 16 位 , 正好是 32bit 的一半 , 自己的高半区和低半区做异或 , 就是为了混合原始哈希码的高位和低位 , 以此来加大低位的随机性 。 而且混合后的低位掺杂了高位的部分特征 , 这样高位的信息也被变相保留下来 。
putVal 方法HashMap 的 put 方法执行过程可以通过下图来理解 , 自己有兴趣可以去对比源码更清楚地研究学习 。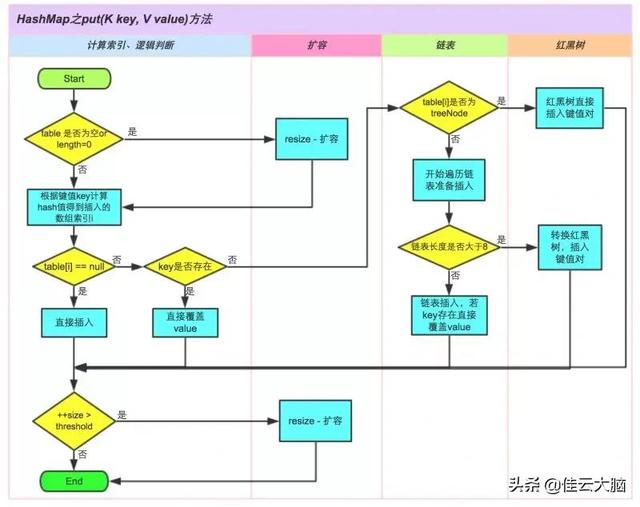 文章插图
文章插图
源码以及解释如下:
// 真正的put操作final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node扩容机制
HashMap 的扩容机制用的很巧妙 , 以最小的性能来完成扩容 。 扩容后的容量就变成了变成了之前容量的 2 倍 , 初始容量为 16 , 所以经过 rehash 之后 , 元素的位置要么是在原位置 , 要么是在原位置再向高下标移动上次容量次数的位置 , 也就是说如果上次容量是 16 , 下次扩容后容量变成了 16+16 , 如果一个元素在下标为 7 的位置 , 下次扩容时 , 要不还在 7 的位置 , 要不在 7+16 的位置 。
我们下面来解释一下 Java8 的扩容机制是怎么做到的?n 为 table 的长度 , 图(a)表示扩容前的 key1 和 key2 两种 key 确定索引位置的示例 , 图(b)表示扩容后 key1 和 key2 两种 key 确定索引位置的示例 , 其中 hash1 是 key1 对应的哈希与高位运算结果 。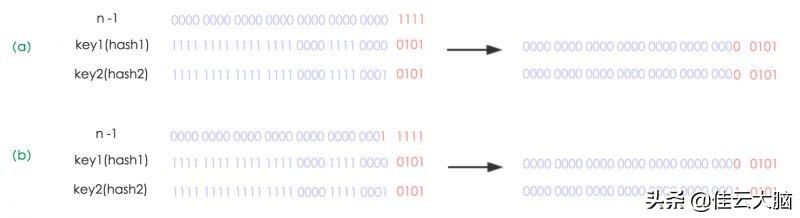 文章插图
文章插图
元素在重新计算 hash 之后 , 因为 n 变为 2 倍 , 那么 n-1 的 mask 范围在高位多 1bit(红色) , 因此新的 index 就会发生这样的变化: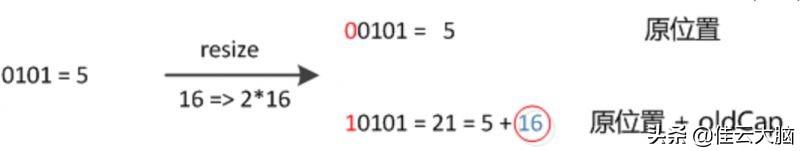 文章插图
文章插图
因此 , 我们在扩充 HashMap 的时候 , 不需要像 JDK1.7 的实现那样重新计算 hash , 只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了 , 是 0 的话索引没变 , 是 1 的话索引变成 “原索引 + oldCap” , 可以看看下图为 16 扩充为 32 的 resize 示意图:
- 品牌|回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 摩托罗拉|回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 并发容器ConcurrentHashMap
- 回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 极致速度美学!iQOO 5 Pro鉴赏:当经典碰到时尚
- 干货:阿里巴巴提升组织能力的5大经典管理工具
- 经典终于升级,创新Aurvana Live!SE耳机
- JDK1.8中HashMap的源码分析
- 沿袭小方块复古风,黑科技加持,Amazfit Neo重塑经典
- countif函数的四种另类经典用法,我不说没人告诉你