并发容器ConcurrentHashMap
突击并发编程JUC系列演示代码地址:
作者:故人
出处:
本节让我们一起研究一下该容器是如何在保证线程安全的同时又能保证高效的操作 。ConcurrentHashMap 是线程安全且高效的 HashMap。
为什么要使用ConcurrentHashMap在并发编程中使用 HashMap 可能导致程序死循环 。 而使用线程安全的 HashTable 效率又非常低下 , 基于以上两个原因 , 便有了 ConcurrentHashMap 的登场机会 。
线程不安全的HashMap在多线程环境下 , 使用 HashMap 进行put操作会引起死循环 , 导致CPU利用率接近100% , 所以在并发情况下不能使用 HashMap。 例如 , 执行以下代码会引起死循环 。
public class HashMapExample {// 请求总数public static int clientTotal = 5000;// 同时并发执行的线程数public static int threadTotal = 200;private static MapHashMap 在并发执行put操作时会引起死循环 , 是因为多线程会导致 HashMap 的 Entry 链表形成环形数据结构 , 一旦形成环形数据结构 , Entry 的 next 节点永远不为空 , 就会产生死循环获取 Entry 。
效率低下的HashTableHashTable 容器使用 synchronized 来保证线程安全 , 但在线程竞争激烈的情况下 HashTable 的效率非常低下 。 因为当一个线程访问 HashTable 的同步方法 , 其他线程也访问 HashTable 的同步方法时 , 会进入阻塞或轮询状态 。 如线程 1 使用 put 进行元素添加 , 线程2不但不能使用put方法添加元素 , 也不能使用 get 方法来获取元素 , 所以竞争越激烈效率越低 。
ConcurrentHashMap 的锁分段技术可有效提升并发访问率HashTable 容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问 HashTable 的线程都必须竞争同一把锁 , 假如容器里有多把锁 , 每一把锁用于锁容器其中一部分数据 , 那么当多线程访问容器里不同数据段的数据时 , 线程间就不会存在锁竞争 , 从而可以有效提高并发访问效率 , 这就是 ConcurrentHashMap 所使用的锁分段技术 。 首先将数据分成一段一段地存储 , 然后给每一段数据配一把锁 , 当一个线程占用锁访问其中一个段数据的时候 , 其他段的数据也能被其他线程访问 。
ConcurrentHashMapExample 示例public class ConcurrentHashMapExample {// 请求总数public static int clientTotal = 5000;// 同时并发执行的线程数public static int threadTotal = 200;private static MapConcurrentHashMap JDK 1.7/JDK 1.8
- JDK 1.7 中使用分段锁(ReentrantLock + Segment + HashEntry) , 相当于把一个 HashMap 分成多个段 , 每段分配一把锁 , 这样支持多线程访问 。 锁粒度:基于 Segment , 包含多个 HashEntry 。
- JDK 1.8 中使用 CAS + synchronized + Node + 红黑树 。 锁粒度:Node(首结点)(实现 Map.Entry) 。 锁粒度降低了 。
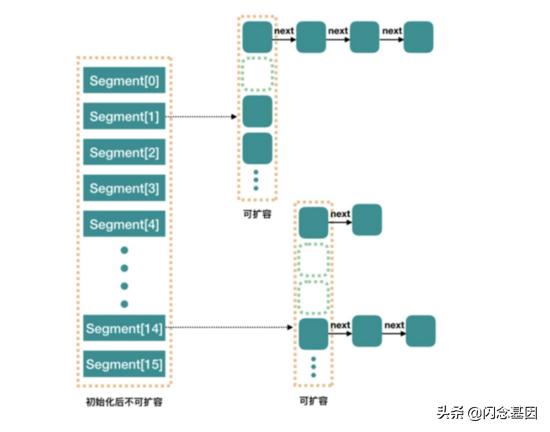 文章插图
文章插图JDK 1.7 中的 ConcurrentHashMap 内部进行了 Segment 分段 ,Segment 继承了 ReentrantLock, 可以理解为一把锁 , 各个 Segment 之间都是相互独立上锁的 , 互不影响 。
相比于之前的 Hashtable 每次操作都需要把整个对象锁住而言 , 大大提高了并发效率 。 因为它的锁与锁之间是独立的 , 而不是整个对象只有一把锁 。
每个 Segment 的底层数据结构与 HashMap 类似 , 仍然是数组和链表组成的拉链法结构 。 默认有 0~15 共 16 个 Segment, 所以最多可以同时支持 16 个线程并发操作(操作分别分布在不同的 Segment 上) 。 16 这个默认值可以在初始化的时候设置为其他值 , 但是一旦确认初始化以后 , 是不可以扩容的 。
- Store|苹果将在韩国开设第二家Apple Store直营店 并发布纪念壁
- Linux(服务器编程):百万并发服务器系统参数调优
- 3D打印高性能可拉伸微型超级电容器
- 为什么 Redis 单线程能支撑高并发?
- IT工程师都需要掌握的容器技术之Docker容器管理
- 除非有理由使用其他容器,优先使用STL vector
- 分布式锁结合SpringCache
- 苹果将在韩国开设第二家Apple Store直营店 并发布纪念壁纸
- Redis集群做法的难点,百万并发客户端「实战」
- 高并发的可见性搞不明白,就不用再研发了