图文并茂:HashMap经典详解
代码中的注解多看几遍 , 其中HashMap的扩容机制是要必懂知识!结合图片一起理解!
什么是 HashMap?HashMap 是基于哈希表的 Map 接口的非同步实现 。 此实现提供所有可选的映射操作 , 并允许使用 null 值和 null 键 。 此类不保证映射的顺序 , 特别是它不保证该顺序恒久不变 。
HashMap 的数据结构 在 Java 编程语言中 , 最基本的结构就是两种 , 一个是数组 , 另外一个是模拟指针(引用) , 所有的数据结构都可以用这两个基本结构来构造的 , HashMap 也不例外 。 HashMap 实际上是一个 “链表散列” 的数据结构 , 即数组和链表的结合体 。
文字描述永远要配上图才能更好的讲解数据结构 , HashMap 的结构图如下 。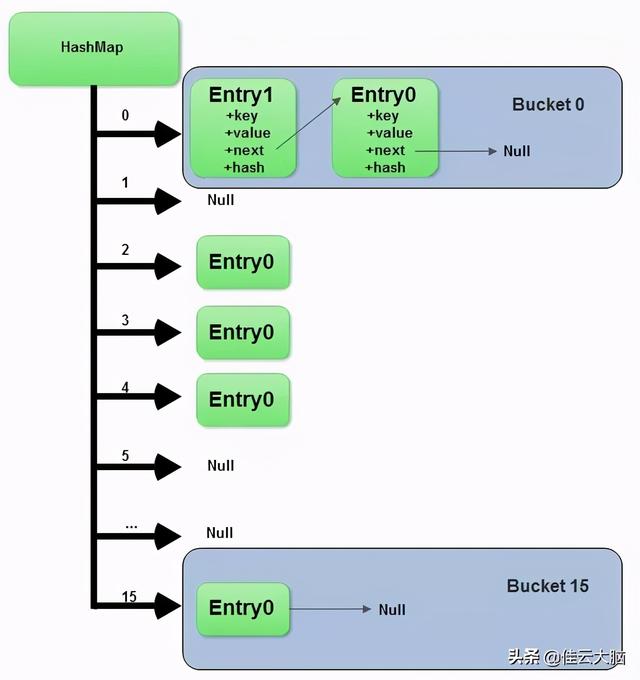 文章插图
文章插图
从上图中可以看出 , HashMap 底层就是一个数组结构 , 数组中的每一项又是一个链表或者红黑树 。 当新建一个 HashMap 的时候 , 就会初始化一个数组 。
下面先通过大概看下 HashMap 的核心成员 。
public class HashMapHashMap 的初始化public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // 其他值都是默认值}通过源码可以看出初始化时并没有初始化数组 table , 那只能在 put 操作时放入了 , 为什么要这样做?估计是避免初始化了 HashMap 之后不使用反而占用内存吧 , 哈哈哈 。
HashMap 的存储操作public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}下面我们详细讲一下 HashMap 是如何确定数组索引的位置、进行 put 操作的详细过程以及扩容机制 (resize)
hash 计算 , 确定数组索引位置不管增加、删除、查找键值对 , 定位到哈希桶数组的位置都是很关键的第一步 。 前面说过 HashMap 的数据结构是数组和链表的结合 , 所以我们当然希望这个 HashMap 里面的元素位置尽量分布均匀些 , 尽量使得每个位置上的元素数量只有一个 , 那么当我们用 hash 算法求得这个位置的时候 , 马上就可以知道对应位置的元素就是我们要的 , 不用遍历链表 , 大大优化了查询的效率 。 HashMap 定位数组索引位置 , 直接决定了 hash 方法的离散性能 。
看下源码的实现:
static final int hash(Object key) { //jdk1.8int h;// h = key.hashCode() 为第一步 取hashCode值// h ^ (h >>> 16) 为第二步 高位参与运算return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}通过 hashCode() 的高 16 位异或低 16 位实现的:(h = k.hashCode()) ^ (h >>> 16) , 主要是从速度、功效、质量来考虑的 , 这么做可以在数组 table 的 length 比较小的时候 , 也能保证考虑到高低 Bit 都参与到 Hash 的计算中 , 同时不会有太大的开销 。
大家都知道上面代码里的 key.hashCode() 函数调用的是 key 键值类型自带的哈希函数 , 返回 int 型散列值 。 理论上散列值是一个 int 型 , 如果直接拿散列值作为下标访问 HashMap 主数组的话 , 考虑到 2 进制 32 位带符号的 int 表值范围从?2147483648 到 2147483648 。 前后加起来大概 40 亿的映射空间 。
只要哈希函数映射得比较均匀松散 , 一般应用是很难出现碰撞的 。 但问题是一个 40 亿长度的数组 , 内存是放不下的 。 你想 , HashMap 扩容之前的数组初始大小才 16 。 所以这个散列值是不能直接拿来用的 。 用之前还要先做对数组的长度取模运算 , 得到的余数才能用来访问数组下标 。 源码中模运算是在这个 indexFor( ) 函数里完成 。
- 品牌|回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 摩托罗拉|回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 并发容器ConcurrentHashMap
- 回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 极致速度美学!iQOO 5 Pro鉴赏:当经典碰到时尚
- 干货:阿里巴巴提升组织能力的5大经典管理工具
- 经典终于升级,创新Aurvana Live!SE耳机
- JDK1.8中HashMap的源码分析
- 沿袭小方块复古风,黑科技加持,Amazfit Neo重塑经典
- countif函数的四种另类经典用法,我不说没人告诉你