「专利解密」知存科技 数模混合存算一体芯片
【嘉德点评】知存科技发明的用于AI运算的数模混合存算一体芯片 , 可以有效降低设计复杂度和制造成本 , 有利于大规模产业化 , 同时也增加了设计的灵活性 。
集微网消息 , 近日 , 知存科技完成了A+轮的投资 , 据悉 , 该投资将会支持知存科技在人工智能端侧芯片领域加大研发力度和拓展业务能力 , 这也是国投在人工智能芯片前沿领域的又一重要战略投资 。
知存科技创立于2017年10月 , 总部位于北京市海淀区 , 其创始人团队在国际上最早开始利用Flash构建基于存算一体架构的深度学习神经网络 , 并完成了全球第一款“存算一体”深度学习芯片 。
近年来 , 存算一体芯片架构得到人们的广泛关注与研究 。 这种芯片是把传统以计算为中心的架构转变为以数据为中心的架构 , 利用存储器进行直接数据处理 , 从而把数据存储与计算融合在同一个芯片中 。 通过模拟方式有效的完成卷积运算 , 突破传统的冯诺依曼架构 , 因此在功耗、算力上相比传统芯片都有数量级的提升 。
传统存算一体芯片架构的基本思想是通过在存储器中内置逻辑计算单元 , 从而把一些简单但数据量又很大的逻辑计算功能放在存储器中完成 , 以减少存储器与处理器之间的数据传输量以及传输距离 。 但是 , 在存储器中内置逻辑计算单元的设计复杂度和制造成本都非常高 , 很难大规模产业化 。
为此 , 知存科技在18年11月28日申请了一项名为“一种数模混合存算一体芯片以及运算装置”的发明专利(申请号:201811436971.5) , 申请人为北京知存科技有限公司 。
根据目前该专利公开的资料 , 让我们一起来看看这项数模混合存算一体芯片吧 。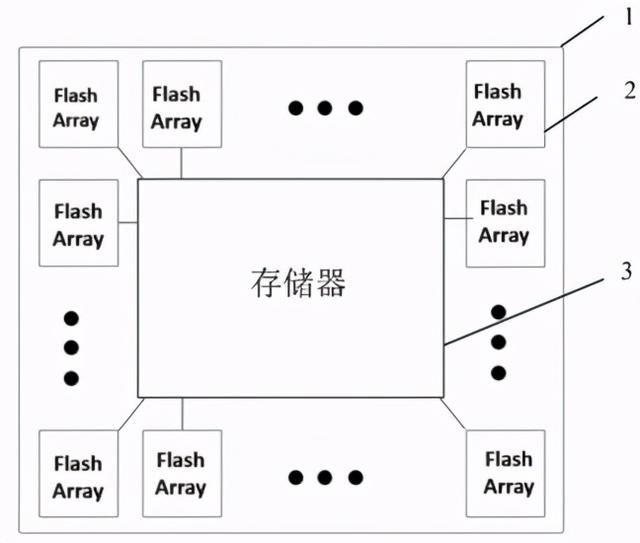 文章插图
文章插图
如上图 , 为这种数模混合存算一体芯片的整体架构图 , 其中包括多个闪存处理器阵列以及连接这些阵列的片上存储器 。 每个闪存处理阵列读取片上存储器中的数据 , 并对数据进行运算处理 , 得到运算结构后将结果传输到片上存储器 , 最后片上存储器则会将处理结果存储起来 。
虽然该架构中包含多个闪存处理阵列 , 但是在进行数据处理时并不是一次性应用全部的处理阵列 , 而是可以实现动态的按需分配 , 这样不仅可以做到处理阵列利用最大化 , 同时也可以显著降低整个系统的功耗 。
此外 , 该专利提供的数模混合运算一体芯片可以集成在一个片上存储器上 , 实现数模混合存算一体的功能 , 并能有效降低设计复杂度和制造成本 , 有利于大规模产业化 。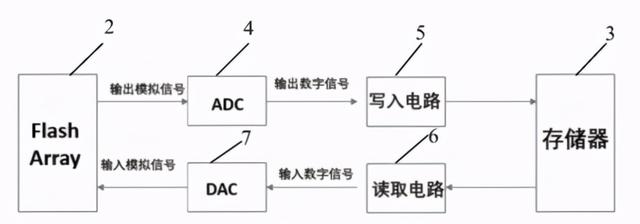 文章插图
文章插图
我们接着来看看这种数模混合存算一体芯片的局部电路结构图 , 如上图 , 在数模混合存算一体芯片的基础上 , 该结构还包括:写入电路5、读取电路6以及DAC7、ADC4 。
闪存处理阵列的输出端依次连接ADC4、写入电路5、片上存储器3 , 因为闪存处理阵列输出的运算结果为模拟数据 。 所以在闪存处理阵列的输出端连接ADC4 , 以将该模拟运算结果转换为片上存储器能够存储的数字信号 , 该数字信号通过写入电路写入片上存储器的预定地址 , 从而实现利用数字存储器存储模拟数据 。
值得一提的是 , 该数模混合存算一体芯片中的多个闪存处理阵列共用一套ADC、DAC、写入电路和读取电路来与片上存储器交互 。 因为片上存储器是分时复用的 , 所以多个闪存处理阵列共用一套ADC、DAC、写入电路和读取电路不会影响芯片功能 , 还能够简化芯片结构、减少芯片面积 , 降低芯片成本 。
那么我们来结合实际应用中的神经网络算法 , 来看看这种数模混合存算一体芯片是如何来实现具体的神经网络算法的吧 。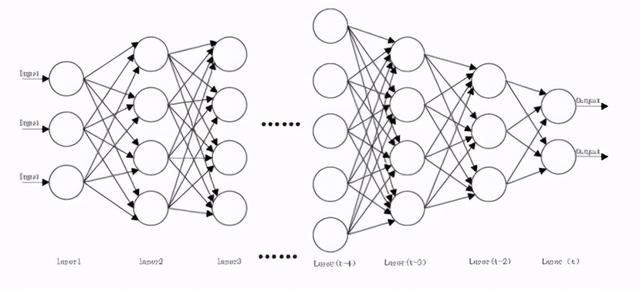 文章插图
文章插图
如上图 , 是目前主流的深度学习神经网络结构图 , 该深度神经网络包括t层 , 即Layer1~Layer(t) , 每层中包括多个神经元 , 每个神经元接收上一层中多个神经元的输出作为输入 , 对接收的数据进行一定的运算 , 得到该神经元的输出 , 输至下一层中的多个神经元 , 作为下一层中对应神经元的输入 , 通过多层之间逐步递进的学习 , 实现复杂的运算识别等功能 。
【「专利解密」知存科技 数模混合存算一体芯片】其中 , Layer1作为输入层来输入待处理的数据;Layer(t)作为输出层来输出运算结果 , Layer2~Layer(t-1)是神经网络中的隐藏层 , 具体的运算处理过程就是在这些层中实现的 。
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 摄像头|摄像头造型别出心裁 realme全新手机设计专利曝光
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- mini|电影、mini 与「当日完稿」工作流
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 公司|英联股份:“一种全自动易开盖冲压卷边注胶生产线”获发明专利证书
- P50|全新液体镜头专利:华为P50系列首发人眼级对焦速度
- iPhone12|iPhone12「超大杯」拍照解禁:与Pro拉不开差距
- 供应链|一座快手「重镇」的货端升级