关联规则|都2020年了,还在迷信啤酒与尿布!数据分析的真相是……
一提人工智能大数据,必有人提啤酒与尿布,有意思的是,都2020年了,还有人信这个老掉牙的都市传说。今天我们系统讲解一下。
1
站在背后的关联规则
支持啤酒与尿布故事的,是关联规则算法。注意:关联规则算法本身没啥问题,这是一种发现关联关系(注意:不是因果关系哦)的手段,并且它的算法原理非常简单,需要的数据也非常少,因此适用范围非常广。
假设有6种产品,ABCDEF,一个客人买了AB去结账,收银员打出一张小票,上边有AB产品的名称、价格,我们可以用、1代表是否有该商品,简单把小票表示成:
类似地,如果有5张订单,可以表示成:
注意,即使没有计算,用肉眼也能看到,似乎ABC三个产品在订单里同时出现的几率很高,这就是关联规则的基本思路:找到同时出现频率高的组合。只不过,我们需要用一些指标来衡量:到底什么算高。
因为有六个商品,所以同时出现的组合有很多种:A+B,A+B+C等,我们从最简单的两两组合开始计算,再算三三、四四……计算组合的时候,我们希望组合出现的频率越高越好,因此有了支持度概念: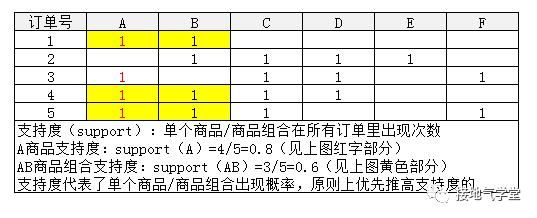
文章插图
两个商品的购买可能有先后顺序,比如先A后B,这时候可以算购买A的情况下,用户购买B的概率,从而决定在用户购买A以后推B产品,或者是C、D产品。因此引入置信度概念: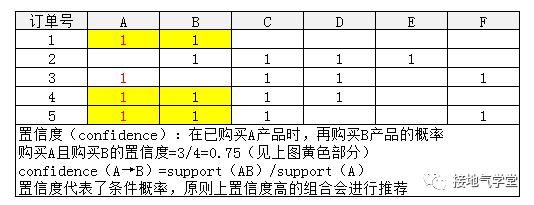
文章插图
注意,虽然算出来购买A以后有75%概率购买B,但是不一定非等到用户买A再推荐B。如这个小例子里,直接推B也有80%购买率,显然非等到买了A再推B会很不划算,购买率还跌了,因此引入提升度概念: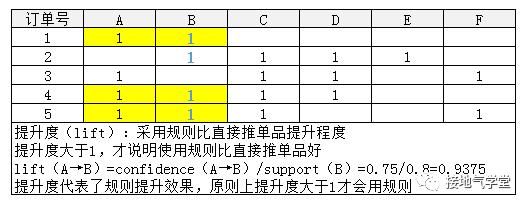
文章插图
支持度、置信度、提升度的计算都很简单,理论上,只需要设定支持度与置信度的要求,之后按一定顺序遍历所有组合(比如Apriori算法),即能找出所有符合条件的组合。这种方法最大的优势就是简单,计算方法、计算逻辑都简单,且需要的数据很少,只要有订单数据即可,数据采集永远是算法的头号大敌,一个需要数据少的方法,自然会被极其广泛的运用。特别是应用于购物篮分析。
然而,运用归运用,你真在哪个超市见过啤酒与尿布堆在一起的吗。很快讲故事的人便发现了这个bug,于是改口说:国外的超市……欺负大家出国少呀。那事实的真相到底是啥呢?
2
为啥现实中不存在
很遗憾,啤酒与尿布在现实中不存在。首先因为啤酒与尿布是teradata公司的销售编出来的故事。它完美符合了卖科技产品需要“意料之外,情理之中”的讲故事原则,因此才流传广泛。在实际运用的时候,无论是技术上还是业务上,类似“啤酒与尿布”的完美案例都不存在。
从技术上看,关联规则作为一种无监督找规律方法,更适合做探索性分析,不太适合直接指向一个可落地的SKU组合。注意,上边的例子是高度浓缩的,所以看起来简单可行。比如啤酒,实际上还包含了品牌、包装、价格、是否促销、是否临近保质期等众多因素。实际上SKU极其庞大,且单个SKU的数据非常零散。
如果只笼统地用“啤酒”这个大品类做关联,得出的数据几乎没啥指导意义。如果细到某一个具体价位具体保质期的SKU,比如“Corona/科罗娜啤酒330ml*24瓶178元非折扣非临期”与“宝适绿帮纸尿裤S164新生婴儿超薄透气干爽款155元”单个具体SKU之间的支持度和置信度都非常低,很难达到落地的程度。
这是导致啤酒与尿布不会出现在超市里根本原因。随便一个3米5门头的小超市尿布至少几十款,啤酒至少几十款,到底哪个该摆在一起!还要考虑啤酒的冷藏问题,总不能在冰柜里放尿布吧。至于几百上千平米大超市,啤酒SKU数几千款,尿布几千款,货架长达数十米,只能分开放在酒水饮料区和母婴用品区。这俩摆在一起,肯定被商场主管活活殴打致死。
从业务上讲,关联规则同所有数学、统计学模型一样,只能说明两个数字之间有关联关系,无法论证任何实际意义上逻辑关系。“妈妈们买尿布的时候会顺便给爸爸买啤酒”的解释,完全就是为了圆故事而圆故事。如果真站在买尿布的妈妈的角度,她有100个理由去买更更值得买的东西,比如干纸巾和湿纸巾。给BB换过尿布的人都知道,那纸巾用起来简直像泼水一样快。有更直接、更明确的驱动力存在,为啥要舍近求远。
3
【 关联规则|都2020年了,还在迷信啤酒与尿布!数据分析的真相是……
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 看过明年的iPhone之后,现在下手的都哭了
- 减重|快看!奇瑞蚂蚁都减重了 那你还焦虑什么?
- 巨头|“社区薇娅”都不够用了 一线互联网巨头全员下场卖菜
- 月入|一上网,感觉网上每个人都是月入过万,到底是错觉还是你out了?
- 社区团购|你在买菜APP上薅的每一根羊毛,都将加倍奉还!
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 换头像|从不换“头像”的人,多半都是这几张原因,你是哪一种?
- 落地|“电竞之都”争夺战中,城市们该怎样实现产业落地?