新闻个性化推荐系统源代码系列之推荐流程设计
推荐系统主要解决的是信息过载的问题 , 目标是从海量物品筛选出不同用户各自喜欢的物品 , 从而为每个用户提供个性化的推荐 。 推荐系统往往架设在大规模的业务系统之上 , 面临着用户的不断增长 , 物品的不断变化 , 并且有着全面的推荐评价指标和严格的性能要求(Netflix 的请求时间在 250 ms 以内 , 今日头条的请求时间在 200ms 以内) , 所以推荐系统很难一次性地快速计算出用户所喜好的物品 , 并且同时满足准确度、多样性等评价指标 。 为了解决如上这些问题 , 推荐系统通常被设计为三个阶段:召回、排序和调整 , 如下图所示: 文章插图
文章插图
推荐系统设计流程
在召回阶段 , 首先筛选出和用户直接相关或间接相关的物品 , 将原始数据从万、百万、亿级别缩小到万、千级别;在排序阶段 , 通常使用二分类算法来预测用户对物品的喜好程度(或者是点击率) , 然后将物品按照喜好程序从大到小依次排列 , 筛选出用户最有可能喜欢的物品 , 这里又将召回数据从万、千级别缩小到千、百级别;最后在调整阶段 , 需要过滤掉重复推荐的、已经购买或阅读的、已经下线的物品 , 当召回和排序结果不足时 , 需要使用热门物品进行补充 , 最后合并物品基础信息 , 将包含完整信息的物品推荐列表返回给客户端 。
这里以文章推荐系统为例 , 讲述一下推荐系统的完整流程 , 如下图所示: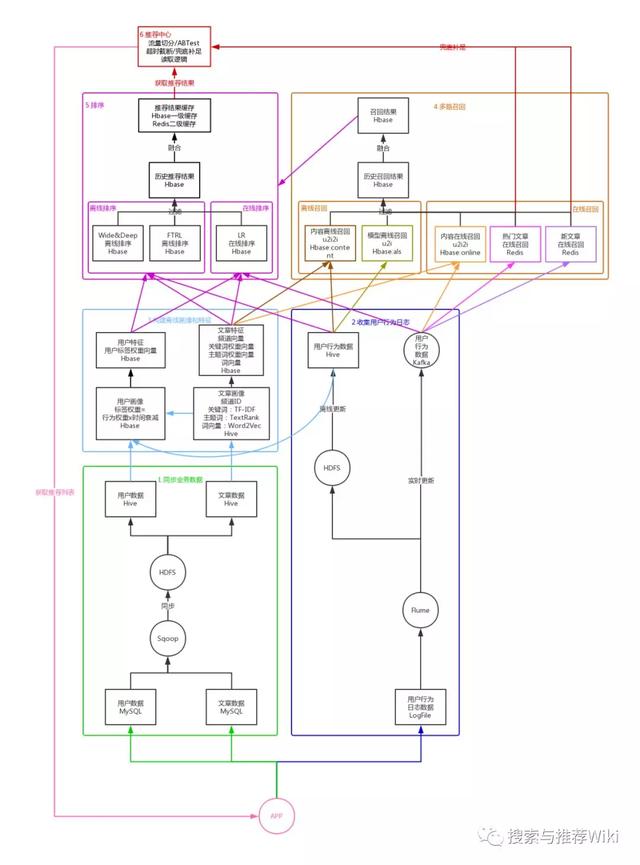 文章插图
文章插图
1. 同步业务数据
为了避免推荐系统的数据读写、计算等对应用产生影响 , 我们首先要将业务数据从应用数据库 MySQL 同步到推荐系统数据库 Hive 中 , 这里利用 Sqoop 先将 MySQL 中的业务数据同步到推荐系统的 HDFS 中 , 再关联到指定的 Hive 表中 , 这样就可以在推荐系统数据库 Hive 中使用用户数据和文章数据了 , 并且不会对应用产生任何影响 。
2. 收集用户行为数据
除了用户数据和文章数据 , 我们还需要得到用户对文章的行为数据 , 比如曝光、点击、阅读、点赞、收藏、分享、评论等 。 我们的用户行为数据是记录在应用服务器的日志文件中的 , 所以可以利用 Flume 对应用服务器的日志文件进行监听 , 一方面将收集到的用户行为数据同步到 HDFS 中 , 并关联到 Hive 的用户行为表 , 每天更新一次 , 以供离线计算使用 。 另一方面将 Flume 收集到的用户行为数据同步到 Kafka , 实时更新 , 以供在线计算使用 。
3. 构建离线画像和特征
文章画像由关键词和主题词组成 , 我们首先读取 Hive 中的文章数据 , 将文章内容进行分词 , 根据 TF-IDF 模型计算每个词的权重 , 将 TF-IDF 权重最高的 K 个词作为关键词 , 再根据 TextRank 模型计算每个词的权重 , 将 TextRank 权重最高的 K 个词与 TF-IDF 权重最高的 K 个词的共现词作为主题词 , 将关键词和主题词存储到 Hive 的文章画像表中 。 接下来 , 利用 Word2Vec 模型 , 计算得到所有关键词的平均向量 , 作为文章的词向量 , 存储到 Hive 的文章向量表中 , 并利用 BucketedRandomProjectionLSH 模型计算得到文章的相似度 , 将每篇文章相似度最高的 K 篇文章 , 存储到 Hbase 的文章相似表中 。 这样我们就得到了每篇文章的画像、词向量以及相似文章列表 。
构建离线用户画像 我们可以将用户喜欢的文章的主题词作为用户标签 , 以便后面根据用户标签来推荐符合其偏好的文章 。 首先读取用户行为数据和文章画像数据 , 计算在用户产生过行为的所有文章中 , 每个主题词的权重 , 不同的行为 , 权重不同 , 计算公式为:用户标签权重 =(用户行为分值之和)x 时间衰减 , 这样就计算得到了用户的标签及标签权重 , 接着读取用户数据 , 得到用户基础信息 , 将用户标签、标签权重及用户基础信息一并存储到 Hbase 的用户画像表中 。 到这里我们已经通过机器学习算法 , 基于用户和文章的业务数据得到了用户和文章的画像 , 但为了后面可以更方便地将数据提供给深度学习模型进行训练 , 我们还需要将画像数据进一步抽象为特征数据 。
构建离线文章特征 由于已经有了画像信息 , 特征构造就变得简单了 。 读取文章画像数据 , 将文章权重最高的 K 个关键词的权重作为文章关键词权重向量 , 将频道 ID、关键词权重向量、词向量作为文章特征存储到 Hbase 的文章特征表 。
构建离线用户特征 读取用户画像数据 , 将权重最高的 K 个标签的权重作为用户标签权重向量 , 将用户标签权重向量作为用户特征存储到 Hbase 的用户特征表 。
- 智能手机|斗球新闻:Reliance Jio与Vivo合作在印度推出Jio独家智能手机
- 美国|知名科技博主:“想法采用曲线”与新闻媒体的未来
- 新闻记者|媒体融合背景下新闻记者如何转型
- 短板|年底换机好推荐,真无短板机称号iQOO 5拿下了
- 最新|2020年12月最新购机推荐,这六款各有优点,实用党首选
- 持续|十一月推荐手机系列,iQOO今年多款机型热度持续
- 极客|极具黑科技含量的AI录音笔推荐:搜狗AI录音笔S1,极客最爱
- 算法|为什么长视频没有强算法推荐的产品
- 效果|这个让你相见恨晚的技巧,能让PPT排版更加有设计感,推荐学习
- 于无声处听好声,三款颈挂式降噪蓝牙耳机推荐