按关键词阅读:
 文章插图
文章插图
 文章插图
文章插图
本文转自AI新媒体量子位(公众号 ID: QbitAI)
搞AI , 谁又没有“GPU之惑”?
张量核心、显存带宽、16位能力……各种纷繁复杂的GPU参数让人眼花缭乱 , 到底怎么选?
从不到1000元1050 Ti到近30000元的Titan V , GPU价格的跨度这么大 , 该从何价位下手?谁才是性价比之王?
让GPU执行不同的任务 , 最佳选择也随之变化 , 用于计算机视觉和做NLP就不太一样 。
而且 , 用云端TPU、GPU行不行?和本地GPU在处理任务时应该如何分配 , 才能更省钱?
最合适的AI加速装备 , 究竟什么样?
现在 , 为了帮你找到最适合的装备 , 华盛顿大学的博士生Tim Dettmers将对比凝练成实用攻略 , 最新的模型和硬件也考虑在内 。
到底谁能在众多GPU中脱颖而出?测评后马上揭晓 。
文末还附有一份特别精简的GPU选购建议 , 欢迎对号入座 。
 文章插图
文章插图
最重要的参数针对不同深度学习架构 , GPU参数的选择优先级是不一样的 , 总体来说分两条路线:
卷积网络和Transformer:张量核心>FLOPs(每秒浮点运算次数)>显存带宽>16位浮点计算能力
循环神经网络:显存带宽>16位浮点计算能力>张量核心>FLOPs
这个排序背后有一套逻辑 , 下面将详细解释一下 。
在说清楚哪个GPU参数对速度尤为重要之前 , 先看看两个最重要的张量运算:矩阵乘法和卷积 。
举个栗子 , 以运算矩阵乘法A×B=C为例 , 将A、B复制到显存上比直接计算A×B更耗费资源 。 也就是说 , 如果你想用LSTM等处理大量小型矩阵乘法的循环神经网络 , 显存带宽是GPU最重要的属性 。
矩阵乘法越小 , 内存带宽就越重要 。
相反 , 卷积运算受计算速度的约束比较大 。 因此 , 要衡量GPU运行ResNets等卷积架构的性能 , 最佳指标就是FLOPs 。 张量核心可以明显增加FLOPs 。
Transformer中用到的大型矩阵乘法介于卷积运算和RNN的小型矩阵乘法之间 , 16位存储、张量核心和TFLOPs都对大型矩阵乘法有好处 , 但它仍需要较大的显存带宽 。
需要特别注意 , 如果想借助张量核心的优势 , 一定要用16位的数据和权重 , 避免使用RTX显卡进行32位运算!
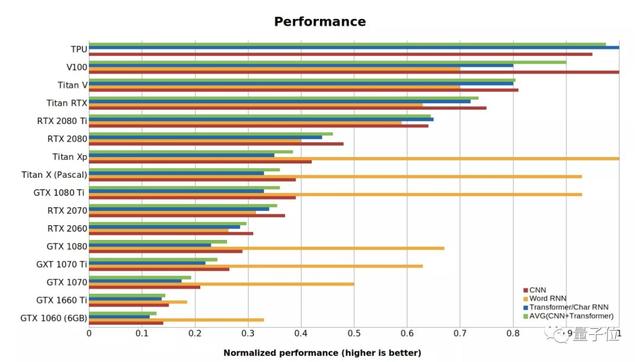
下面Tim总结了一张GPU和TPU的标准性能数据 , 值越高代表性能越好 。 RTX系列假定用了16位计算 , Word RNN数值是指长度<100的段序列的biLSTM性能 。
这项基准测试是用PyTorch 1.0.1和CUDA 10完成的 。
 文章插图
文章插图
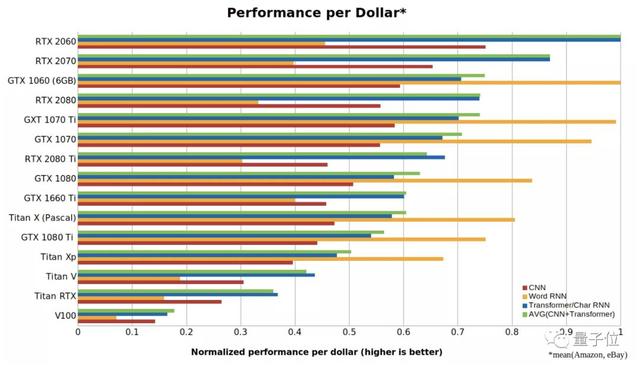
△GPU和TPU的性能数据性价比分析【深度学习GPU最全对比,到底谁才是性价比之王?】性价比可能是选择一张GPU最重要的考虑指标 。 在攻略中 , 小哥进行了如下运算测试各显卡的性能:
- 用语言模型Transformer-XL和BERT进行Transformer性能的基准测试 。
- 用最先进的biLSTM进行了单词和字符级RNN的基准测试 。
- 上述两种测试是针对Titan Xp、Titan RTX和RTX 2080 Ti进行的 , 对于其他GPU则线性缩放了性能差异 。
- 借用了现有的CNN基准测试 。
- 用了亚马逊和eBay上显卡的平均售价作为GPU的参考成本 。
 文章插图
文章插图△CNN、RNN和Transformer的每美元性能在上面这张图中 , 数字越大代表每一美元能买到的性能越强 。 可以看出 ,RTX 2060比RTX 2070 , RTX 2080或RTX 2080 Ti更具成本效益 , 甚至是Tesla V100性价比的5倍以上 。
所以此轮的性价比之王已经确定 , 是RTX 2060无疑了 。
不过 , 这种考量方式更偏向于小型GPU , 且因为游戏玩家不喜欢RTX系列显卡 , 导致GTX 10xx系列的显卡售价虚高 。 此外 , 还存在一定的单GPU偏差 , 一台有4个RTX 2080 Ti的计算机比两台带8个RTX 2060的计算机性价比更高 。
所需显存与16位训练GPU的显存对某些应用至关重要 , 比如常见的计算机视觉、机器翻译和一部分NLP应用 。 可能你认为RTX 2070具有成本效益 , 但需要注意其显存很小 , 只有8 GB 。
不过 , 也有一些补救办法 。
通过16位训练 , 你可以拥有几乎16位的显存 , 相当于将显存翻了一倍 , 这个方法对RTX 2080和RTX 2080 Ti同样适用 。
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111T320342020.html
标题:深度学习GPU最全对比,到底谁才是性价比之王?