按关键词阅读:
编者按:EMNLP 是自然语言处理领域的顶级会议之一 , 2020年的 EMNLP 会议将于11月16日至20日召开 。 微软亚洲研究院精选了5篇录取的论文为大家进行介绍 。
多样、可控且关键短语感知:一个新闻多标题生成的语料库与方法
Diverse, Controllable, and Keyphrase-Aware: A Corpus and Method for News Multi-Headline Generation
论文链接:
新闻标题生成是文本摘要领域的一个子任务 。 文本摘要往往包含多个上下文相关的句子来涵盖文档的主要思想 , 而新闻标题则要用一个简短的句子来吸引用户阅读新闻 。 由于一篇新闻文章通常可以有多种合理的新闻标题 , 并且包含多个不同用户感兴趣的关键短语或主题 。 因此 , 同一篇新闻可以围绕不同用户感兴趣的不同关键短语 , 生成多个新闻标题并根据用户的兴趣推荐具有不同新闻标题的新闻 。 同时 , 新闻多标题的生成也可以为新闻编辑提供辅助信息 。
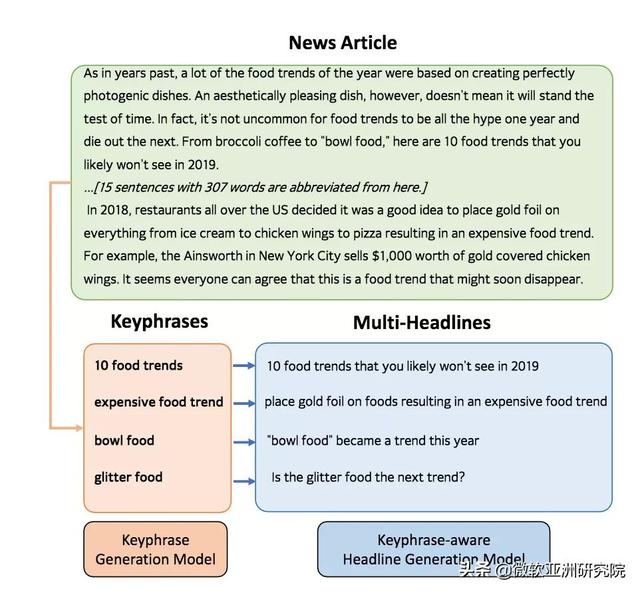
传统的新闻标题方法往往将新闻标题生成过程看作为是一对一的映射 , 即通过序列到序列模型 , 将输入的新闻文章映射到输出的新闻标题 。 由于一篇新闻有多种合理的标题 , 所以在训练阶段让模型生成单个的 ground-truth 会缺乏进一步的指导信息 。 而且在测试阶段 , 单个的 ground-truth 也难以进行合理的自动评价 。 为了缓解这个问题 , 本文额外引入了关键短语输入作为指导信息 , 将一对一的映射转换为二对一的映射 。 文章提出了一个关键短语敏感的新闻多标题生成方法 , 该方法包含两个模块 , 关键短语生成模型和关键短语敏感的新闻标题生成模型 。 整体结构如图1所示 。
 文章插图
文章插图
图1:关键短语敏感的新闻多标题生成
研究员们基于必应新闻(Bing News)搜索引擎 , 利用用户查询、引擎返回的新闻标题和文章以及用户基于查询点击新闻的次数 , 去挖掘新闻中用户感兴趣的关键短语 , 并构造了 KeyAware News 数据集 。 该数据集包含18万对齐的<用户感兴趣的关键短语 , 新闻标题 , 新闻文章>三元组数据 。
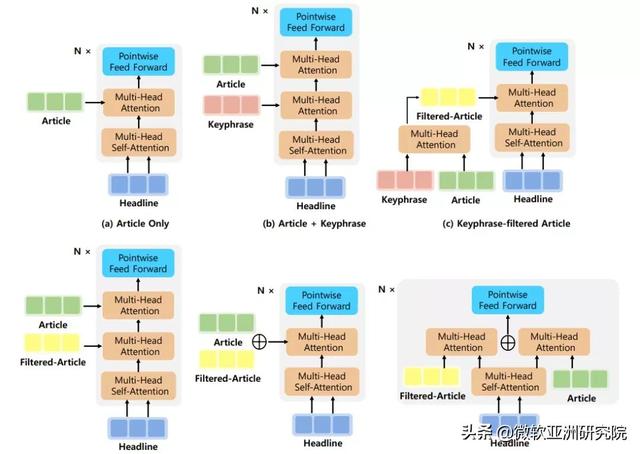
对于关键短语敏感的新闻标题生成模型 , 基于 BERT 作为编码器 , Transformer 作为解码器并带有 copy 机制的新闻标题生成 BASE 模型 , 研究员们进一步探索了几种在解码器处引入关键短语信息的模型结构 , 如图2所示 。
 文章插图
文章插图
图2:关键短语敏感的新闻标题生成模型解码器及其变体
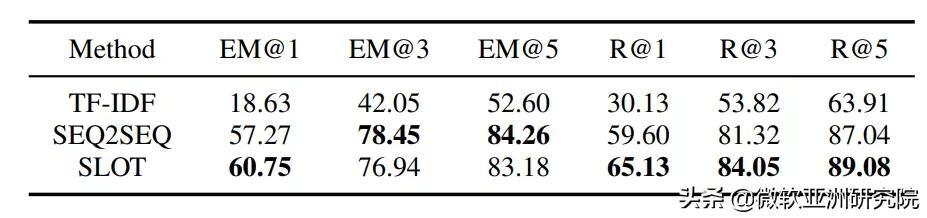
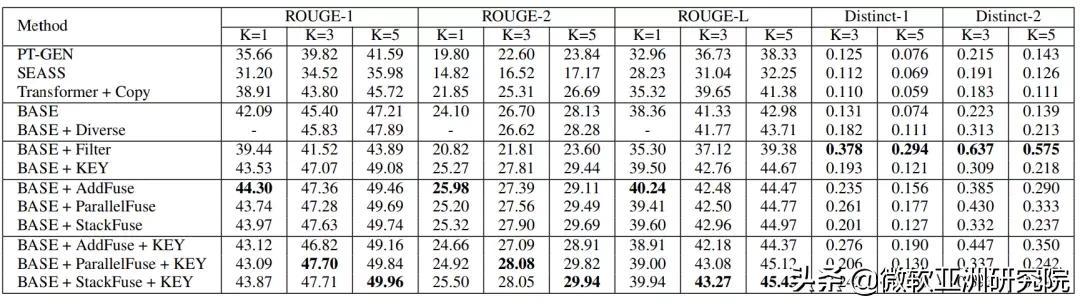
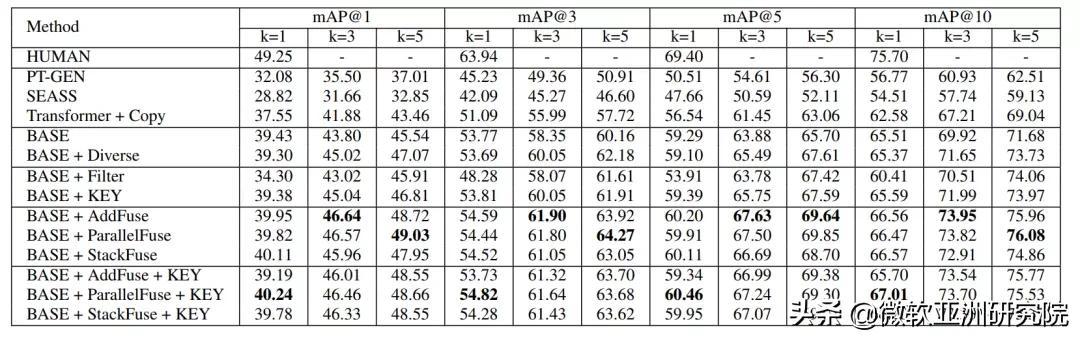
对于新闻文章的关键短语生成 , 研究员们尝试了 TF-IDF、Seq2seq 和 POS Tagging 等方法 。 他们通过实验对比了关键短语生成的效果(表1) , 以及和多种基准方法与模型变体在生成标题的质量和多样性上进行了人工评价和自动评价(表2) 。 并且通过一个基于检索的实验(表3) , 将生成的新闻标题作为新闻的搜索键值 , 通过对应的用户查询去检索新闻 , 来进一步测试生成新闻的质量和多样性 。 大量的实验结果证明了本文提出方法的有效性 。
 文章插图
文章插图
表1:关键短语生成方法结果对比
 文章插图
文章插图
表2:多标题生成结果对比
 文章插图
文章插图
表3:新闻检索实验结果对比
用语义分割的思路解决不完整话语重写任务:一种全新的观点
Incomplete Utterance Rewriting as Semantic Segmentation
论文链接:
代码链接:
近些年单轮对话的理解已经取得了较大的进展 , 但多轮对话仍是学术界的一个难题 。 多轮对话的一大挑战就在于用户会抛出语义不完整的问题 , 如省略实体或者通过代词指代到对话历史中的实体 。 这样的挑战推动了上下文理解方向的研究工作 , 包括早期端到端的上下文建模方法 , 和近期研究者们所关注的不完整话语重写(Incomplete Utterance Rewriting) 。
不完整话语重写旨在将对话中语义不完整的句子重写为一个语义完整的、可脱离上下文理解的句子 , 以恢复所有指代和省略的信息 。 由于该任务的输出严重依赖于输入 , 已有工作绝大部分都是在复制网络的基础上进行改进 。 而微软亚洲研究院的研究员们另辟蹊径地将该任务视为一个面向对话编辑的任务 , 并据此提出了一个全新的、使用语义分割思路来解决不完整话语重写的模型 。
在本篇论文中 , 研究员们提出了一个使用语义分割思路来预测编辑过程的模型 RUN (Rewriting U-shaped Network) 。 与传统基于复制网络的生成模型不同 , RUN 将不完整话语重写视为面向对话编辑的任务: 对话中的语句片段可以插入到某个位置 , 或替换某个片段 。 图3中展示了 A 和 B 之间的一个对话 , 其中最后一句“为什么总是这样”是一个语义不完整的语句 , 其重写后的语句是“北京为什么总是阴天” 。 这个示例中的重写可以通过两个简单的编辑操作来刻画 , 分别是把“北京”插入到“为”前 , 和用“阴天”替换“这样” 。 实际上 , 由于该任务本身的性质 , 绝大多数重写句都只需要用到原对话中的词 , 这在一定程度上说明了面向对话编辑的合理性和普适性 。![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111T314412020.html
标题:EMNLP 2020 | 微软亚洲研究院精选论文解读