按关键词阅读:
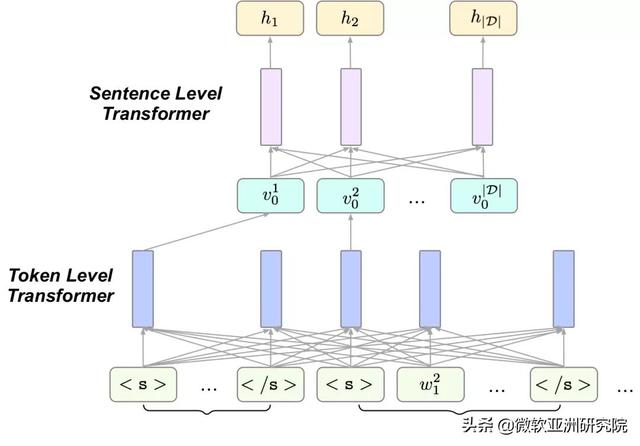
本文利用 Transformer 中的注意力机制对句子进行排序 。 为了学习句子层面的注意力系数 , 研究采用了分层的结构 。
 文章插图
文章插图
图10:编码器的分层结构
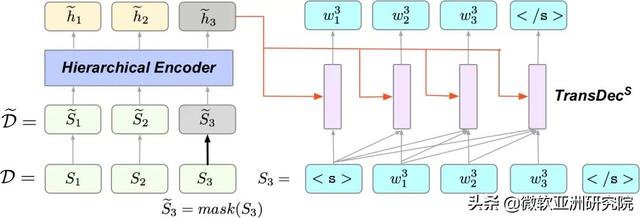
研究员们采用了两种预训练方法来训练该模型 , Masked Sentences Prediction (MSP) 将文章中的某些句子掩盖住 , 然后利用上下文恢复出被掩盖的句子 。
 文章插图
文章插图
图11:MSP 示意图
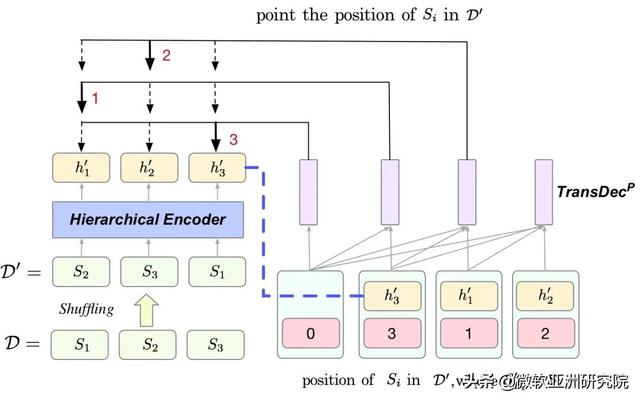
另一方面 , 为了减弱模型对于句子位置的依赖 , 研究员们提出了另一种预训练方式 Sentence Shuffling (SS) 。 SS先将文章中的句子打乱 , 然后依次找出原文中的句子打乱后所在的位置 。
 文章插图
文章插图
图12:SS 示意图 , 经过打乱后原文第1句话到了第3个位置 , 模型第1个预测结果应该是3 , 第2个预测结果应该是1
经过以上两种预训练 , 在对句子排序时 , 研究员们将文章中的句子逐个掩盖 , 然后利用其他句子恢复被掩盖的句子(过程像 MSP 一样) 。 之后利用恢复情况对当前被掩盖的句子评分 , 同时用注意力系数评价其他句子在恢复当前句子的贡献 。 最后 , 通过最终评分对句子进行排序 , 得分最高的三个句子被选作摘要 。
【EMNLP 2020 | 微软亚洲研究院精选论文解读】该方法在 CNN/DM 数据集和 NYT 数据集上都取得了非常不错的效果 。 并且经过验证 , 这个方法可以更少地依赖于句子的位置 。
![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111T314412020.html
标题:EMNLP 2020 | 微软亚洲研究院精选论文解读( 四 )