按关键词阅读:
 文章插图
文章插图
 文章插图
文章插图
编译 | AI科技大本营(ID:rgznai100)
许多组织都在尝试收集和利用尽可能多的数据 , 以改善其经营方式 , 增加收入和提升影响力 。 因此 , 数据科学家面对50GB甚至500GB大小的数据集情况变得越来越普遍 。
不过 , 这类数据集使用起来不太容易 。 它们足够小 , 可以装入日常笔记本电脑的硬盘驱动器中 , 但同时大到无法装入RAM , 导致它们已经很难打开和检查 , 更不用说探索或分析了 。
处理此类数据集时 , 通常采用3种策略 。
第一种是对数据进行二次采样 , 但缺点很明显:你可能因为忽视相关部分数据而错过关键洞察 , 甚至更糟的是 , 这会误解了数据所阐释的含义 。
第二种策略是使用分布式计算 。 在某些情况下这是一种有效的方法 , 但它需要管理和维护集群的大量开销 。
又或者 , 你可以租用一个强大的云实例 , 该实例具有处理相关数据所需的内存 。 例如 , AWS提供具有TB级RAM的实例 。 在这种情况下 , 你仍然必须管理云数据存储区 , 每次实例启动时 , 都需要等待数据从存储空间传输到实例 , 同时 , 还要考虑将数据存储在云上的合规性问题 , 以及在远程计算机上工作带来的不便 。 更不别说成本 , 尽管一开始成本很低 , 但后续往往会增加 。
Vaex是解决这个问题的新方法 。 它是一种几乎可以对任意大小的数据进行数据科学研究的更快、更安全、更方便的方法 , 只要数据集可以安装在你的笔记本电脑 , 台式机或服务器硬盘上 。
什么是Vaex?
Vaex 是一个开源的 DataFrame 库(类似于Pandas) , 对和你硬盘空间一样大小的表格数据集 , 它可以有效进行可视化、探索、分析甚至进行实践机器学习 。
 文章插图
文章插图
它可以在N维网格上计算每秒超过十亿(10^9)个对象/行的统计信息 , 例如均值、总和、计数、标准差等。 使用直方图、密度图和三维体绘制完成可视化 , 从而可以交互式探索大数据 。 Vaex使用内存映射、零内存复制策略获得最佳性能(不浪费内存) 。
为实现这些功能 , Vaex 采用内存映射、高效的核外算法和延迟计算等概念 。 所有这些都封装为类 Pandas 的 API , 因此 , 任何人都能快速上手 。
十亿级计程车的数据分析
为了说明这一概念 , 让我们对一个数据集进行简单的探索性数据分析 , 该数据集并不适合典型笔记本电脑的RAM 。
本文中将使用纽约市(NYC)出租车数据集 , 其中包含标志性的黄色出租车在2009年至2015年之间进行的超过10亿次出行的信息 。 数据可以从网站()下载 , 并且为CSV格式 。 完整的分析可以在此Jupyter笔记本中单独查看() 。
为什么要选择vaex
- 性能:处理海量表格数据 , 每秒处理超过十亿行
- 虚拟列:动态计算 , 不浪费内存
- 高效的内存在执行过滤/选择/子集时没有内存副本 。
- 【爱了爱了!0.052秒打开100GB数据,这个Python开源库火爆了】可视化:直接支持 , 单线通常就足够了 。
- 用户友好的API:只需处理一个数据集对象 , 制表符补全和docstring可以帮助你:ds.mean , 类似于Pandas 。
- 精益:分成多个包
- Jupyter集成:vaex-jupyter将在Jupyter笔记本和Jupyter实验室中提供交互式可视化和选择 。
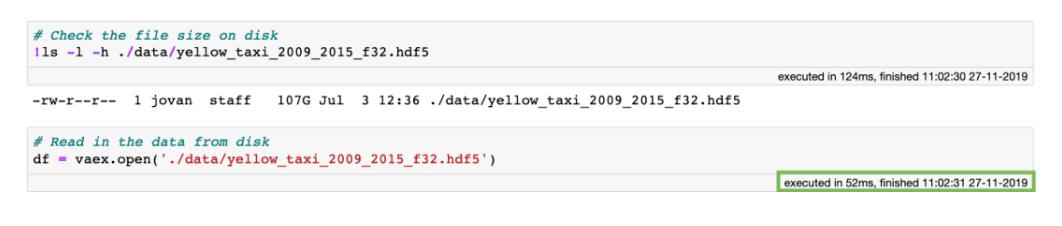
第一步是将数据转换为内存可映射文件格式 , 例如Apache Arrow , Apache Parquet或HDF5 。 在此处也可以找到如何将CSV数据转换为HDF5的示例 。 数据变为内存可映射格式后 , 即使在磁盘上的大小超过100GB , 也可以使用Vaex即时打开(只需0.052秒!):
 文章插图
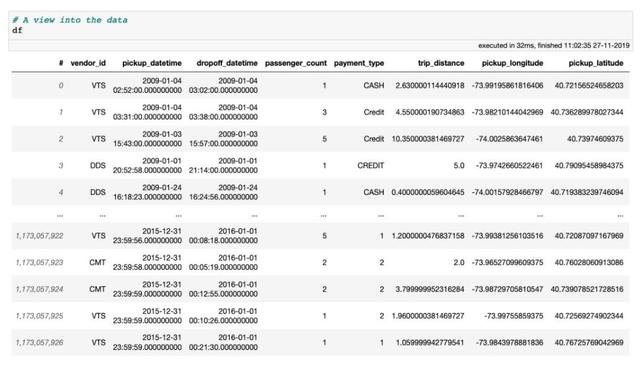
文章插图为什么这么快?当使用Vaex打开内存映射文件时 , 实际上没有进行任何数据读取 。 Vaex仅读取文件的元数据 , 例如磁盘上数据的位置 , 数据结构(行数、列数、列名和类型) , 文件说明等 。 那么 , 如果我们要检查数据或与数据交互怎么办?打开数据集会生成一个标准的DataFrame并对其进行快速检查:
 文章插图
文章插图注意 , 单元执行时间太短了 。 这是因为显示Vaex DataFrame或列仅需要从磁盘读取前后5行数据 。 这将我们引向另一个重点:Vaex只会在需要时遍历整个数据集 , 并且会尝试通过尽可能少的数据传递来做到这一点 。
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2J592020.html
标题:爱了爱了!0.052秒打开100GB数据,这个Python开源库火爆了