按关键词阅读:
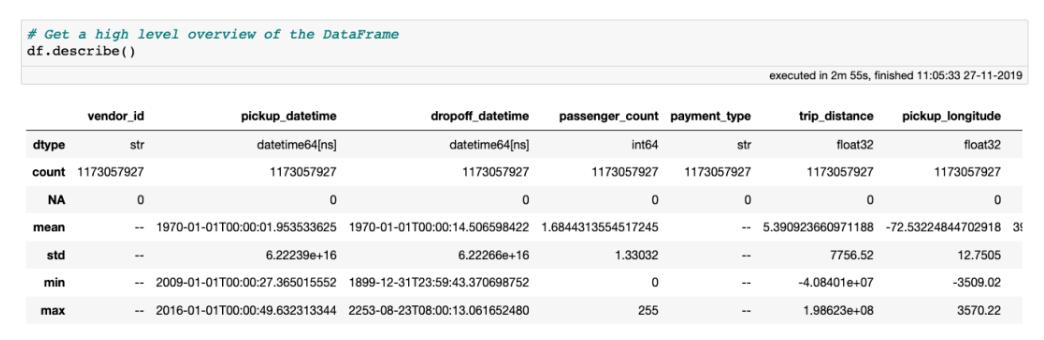
无论如何 , 让我们从极端异常值或错误数据输入值开始清除此数据集 。 一个很好的方法是使用describe方法对数据进行高级概述 , 其中显示了样本数、缺失值数和每一列的数据类型 。 如果列的数据类型为数字 , 则还将显示平均值、标准偏差以及最小值和最大值 。 所有这些统计信息都是通过对数据的一次传递来计算的 。
 文章插图
文章插图
使用describe方法获得 DataFrame 的高级概览 , 注意这个 DataFrame 包含 18 列数据 , 不过截图只展示了前 7 列 。
该describe方法很好地体现了Vaex的功能和效率:所有这些统计数据都是在我的MacBook Pro(2018款15英寸 , 2.6GHz Intel Core i7 , 32GB RAM)上用不到3分钟的时间计算出来的 。 其他库或方法都需要分布式计算或拥有超过100GB的云实例来执行相同的计算 。 而使用Vaex , 你所需要的只是数据 , 以及只有几GB RAM的笔记本电脑 。
查看describe的输出 , 很容易注意到数据包含一些严重的异常值 。
首先开始检查上车地点 。 消除异常值的最简单方法是简单地绘制上下车地点的位置 , 并直观地定义我们要集中分析的NYC区域 。 由于我们正在使用如此大的数据集 , 因此直方图是最有效的可视化效果 。 使用Vaex创建和显示直方图和热力图的速度很快 , 而且图表可以交互!
 文章插图
文章插图
一旦我们通过交互决定要关注的NYC区域 , 就可以简单地创建一个筛选后的DataFrame:
 文章插图
文章插图
关于上面的代码 , 最酷的事情是它需要执行的内存量可以忽略不计!在筛选Vaex DataFrame时不会复制数据 , 而是仅创建对原始对象的引用 , 在该引用上应用二进制掩码 。 用掩码选择要显示的行 , 并将其用于将来的计算 。 这将为我们节省100GB的RAM , 而像今天许多标准数据科学工具却要复制数据 。
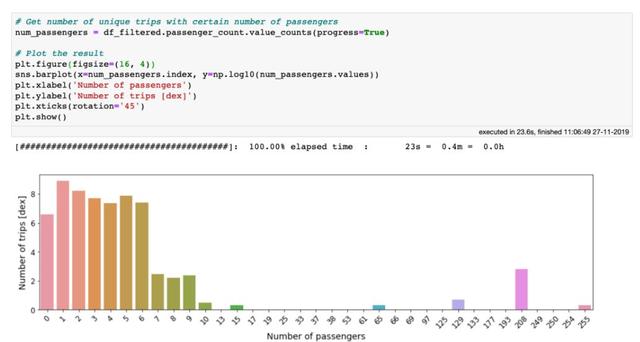
现在 , 检查一下该passenger_count列 。 单次出租车行程记录的最大乘客数为255 , 这似乎有些夸张 。 计算每次行程的乘客人数 , 使用以下value_counts方法很容易做到这一点:
 文章插图
文章插图
在 10 亿行数据上使用 value_counts 方法只需要 20 秒
从上图可以看出 , 载客超过6人的行程可能是罕见的异常值 , 或者仅仅是错误的数据输入 , 还有大量的0位乘客的行程 。 由于目前我们尚不了解这些行程是否合法 , 因此我们也将其过滤掉 。
 文章插图
文章插图
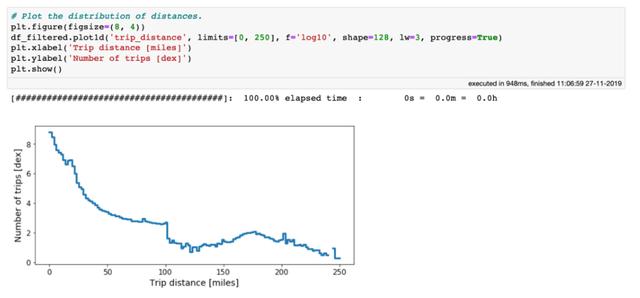
让我们对行程距离进行类似的练习 。 由于这是一个连续变量 , 因此我们可以绘制行程距离的分布图 。 让我们绘制一个更合理范围的直方图 。
 文章插图
文章插图
纽约出租车数据行程距离直方图
从上图可以看出 , 出行次数随着距离的增加而减少 。 在距离约100英里处 , 分布有明显下降 。 目前 , 我们将以此为起点 , 根据行程距离消除极端离群值:
 文章插图
文章插图
出行距离一列中存在极端异常值 , 这也是研究出行时间和出租车平均速度的动机 。 这些功能在数据集中尚不可用 , 但计算起来很简单:
 文章插图
文章插图
上面的代码块无需内存 , 无需花费时间即可执行!这是因为代码只会创建虚拟列 。 这些列仅包含数学表达式 , 并且仅在需要时才进行评估 。 此外 , 虚拟列的行为与任何其他常规列都相同 。 注意 , 其他标准库将需要10 GB的RAM才能进行相同的操作 。
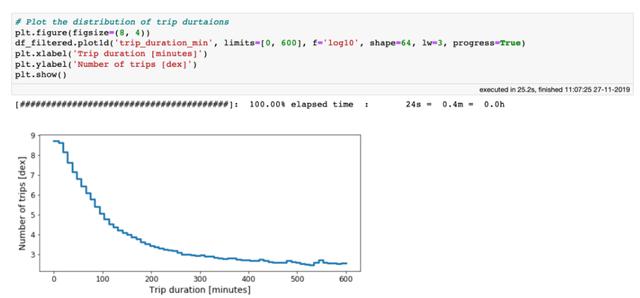
好了 , 让我们来绘制行程耗费时间的分布:
 文章插图
文章插图
纽约超过 10 亿次出租车行程耗费时间的直方图
从上面的图中可以看出 , 尽管有一些行程可能需要花费4至5个小时 , 但95%的出租车花费不到30分钟即可到达目的地 。 你能想象在纽约市被困出租车中超过3个小时吗?无论如何 , 我们要保持开放的态度 , 并考虑所有花费时间少于3小时的行程:
 文章插图
文章插图
现在 , 让我们研究出租车的平均速度 , 同时选择一个合理的数据范围:![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2J592020.html
标题:爱了爱了!0.052秒打开100GB数据,这个Python开源库火爆了( 二 )