2万字长文:Kubernetes云原生开源分布式存储( 六 )
一个Volume对应一个Target Pod , 这完全遵循了CAS的设计理念 。
4 让分布式存储简化管理的Rook4.1 Rook简介Rook [9] 也是目前开源中比较流行的云原生存储编排系统 , 它和之前介绍的LongHorn和OpenEBS不一样 , 它的目标并不是重新造轮子实现一个全新的存储系统 , 最开始Rook项目仅仅专注于如何实现把Ceph运行在Kubernetes平台上 。
随着项目的发展 , 格局也慢慢变大 , 仅仅把Ceph搞定是不够的 , 项目当前的目标是将外部已有的分布式存储系统在云原生平台托管运行起来 , 借助云原生平台具有的自动化调度、故障恢复、弹性扩展等能力实现外部存储系统的自动管理、自动弹性扩展以及自动故障修复 。
按照官方的说法 , Rook要把原来需要对分布式存储系统手动做的一些运维工作借助云原生平台能力(如Kubernetes)实现自动化 , 这些运维工作包括部署、初始化、配置、扩展、升级、迁移、灾难恢复、监控以及资源管理等 , 这种自动化甚至不需要人去手动触发 , 而是云原生平台自动触发的 , 因此叫做self-managing , 真正实现NoOpts 。
比如集群增加一块磁盘 , Rook能自动初始化为一个OSD , 并自动加入到合适的故障域中 , 这个OSD在Kubernetes中是以Pod的形式运行的 。
目前除了能支持编排管理Ceph集群 , 还支持:
- EdgeFS
- CockroachDB
- Cassandra
- NFS
- Yugabyte DB
4.2 Rook部署安装部署Rook非常简单 , 以Ceph为例 , 只需要安装对应的Operator即可:
git clone --single-branch --branch release-1.3 \cd rook/cluster/examples/kubernetes/cephkubectl create -f common.yamlkubectl create -f operator.yamlkubectl create -f cluster.yaml通过Rook管理Ceph , 理论上不需要直接通过Ceph Client命令行接口与Ceph集群直接交互 。 不过如果有需要 , 可以通过如下方式进行简单配置:kubectl create -f toolbox.yaml # 安装Ceph client工具export CEPH_TOOL_POD=$(kubectl -n rook-ceph \get pod -l "app=rook-ceph-tools" \-o jsonpath='{.items[0].metadata.name}')alias ceph="kubectl -n rook-ceph exec -it $CEPH_TOOL_POD -- ceph"alias rbd="kubectl -n rook-ceph exec -it $CEPH_TOOL_POD -- rbd"使用 ceph 命令查看集群状态:# ceph osd dfID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUSTOTAL0 B0 B0 B0 B0 B0 B0MIN/MAX VAR: -/-STDDEV: 0我们发现Ceph集群是空的 , 没有任何OSD , 这是因为我的机器没有裸磁盘(即没有安装任何文件系统的分区) 。DeamonSet rook-discover 会定时监视Node节点是否有新的磁盘 , 一旦有新的磁盘 , 就会自动启动一个Job进行OSD初始化 。 如下是Node节点增加磁盘的结果:
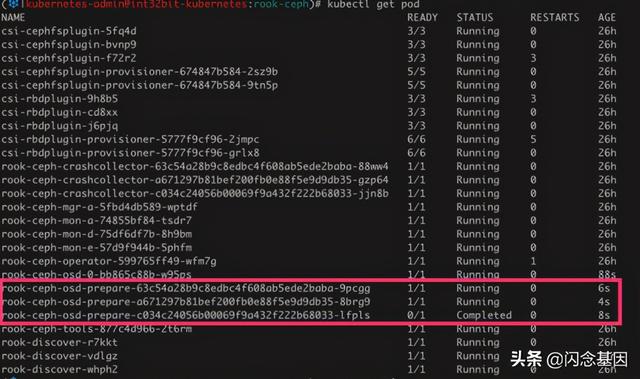 文章插图
文章插图ceph osd prepare
如果运行在公有云上 , rook还会根据节点的Region以及AZ自动放到不同的故障域 , 不需要手动调整crushmap:
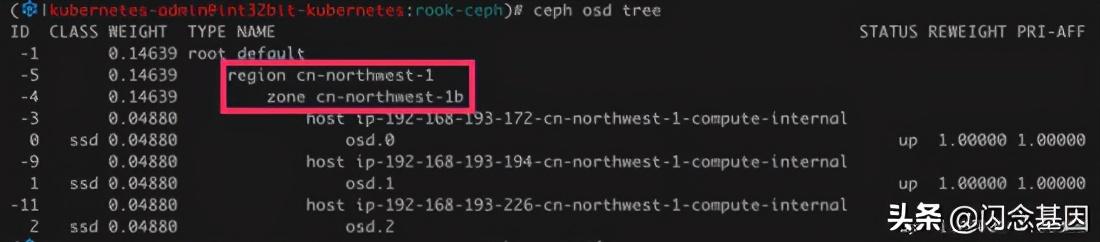 文章插图
文章插图ceph osd tree
如图 , 由于我的测试集群部署在AWS上 , 并且三个节点都放在了一个AZ上 , 因此三个OSD都在 zone cn-northwest-1b 中 , 实际生产环境不推荐这么做 。
我们发现整个磁盘以及OSD初始化过程 , 无需人工干预 , 这就是所谓的 self-manage。
想想我们平时在做Ceph集群扩容 , 从准备磁盘到crushmap配置 , 没有半个小时是搞不定的 , 而通过Rook我们几乎不用操心OSD是如何加到集群的 。
Rook默认还会安装Ceph Dashboard , 可以通过Kubernetes Service rook-ceph-mgr-dashboard 进行访问 ,admin 的密码保存在secret rook-ceph-dashboard-password 中 , 可通过如下命令获取:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password \-o jsonpath="{['data']['password']}" \| base64 --decode--tt-darkmode-bgcolor: #BEBEBF;">ceph osd pool create 命令手动创建 , 但这样体现不了 self-managing, 我们应该屏蔽Ceph集群接口 , 直接使用Kubernetes CRD进行声明:
# kubectl apply -f -apiVersion: ceph.rook.io/v1kind: CephBlockPoolmetadata:name: replicapoolnamespace: rook-cephspec:failureDomain: hostreplicated:size: 3通过如上方式 , 我们基本不需要使用 ceph 命令 , 即创建了一个3副本的rbd pool 。
可以通过 kubectl get cephblockpools 查看pool列表:
# kubectl get cephblockpoolsNAMEAGEreplicapool107s创建一个Pod使用 CephBlockPool 新建Volume:
# kubectl apply -f ----apiVersion: v1kind: PersistentVolumeClaimmetadata:name: test-ceph-blockstorage-pvcspec:storageClassName: rook-ceph-blockaccessModes:- ReadWriteOnceresources:requests:storage: 20Gi---apiVersion: v1kind: Podmetadata:name: test-ceph-blockstoragespec:containers:- name: test-ceph-blockstorageimage: jocatalin/kubernetes-bootcamp:v1volumeMounts:- name: volvmountPath: /datavolumes:- name: volvpersistentVolumeClaim:claimName: test-ceph-blockstorage-pvc
- Kubernetes 运维小记:node 为系统保留最低资源
- 在kubernetes中部署企业级ELK并使用其APM
- Kubernetes上对应用程序进行故障排除的技巧
- 代表|以Kubernetes为代表的容器技术,已成为云计算的新界面
- 微信|万字长文:谈谈我对视频号的思考
- Kubernetes核心原理和搭建
- 管理20+Kubernetes集群、400台机器,秘诀在于?
- 中文|万字长文:谷歌进入到退出中国市场的前因后果
- 万字长文,ConcurrentSkipListMap源码详解
- 用Ansible的Kubernetes模块实现容器编排自动化