万字长文,ConcurrentSkipListMap源码详解
ConcurrentSkipListMap 文章插图
文章插图
思维导图
简介可伸缩地并发ConcurrentNavigableMa实现 。
根据可比较的自然顺序或根据在创建 map 时提供的Comparator对 map 进行排序 , 具体取决于所使用的构造函数 。
入门例子ConcurrentSkipListMap map = new ConcurrentSkipListMap();map.put("one", 1);map.put("two", 2);for (String key : map.keySet()) {System.out.print("[" + key + "," + map.get(key) + "] ");}System.out.println("\n\n开始删除元素 1");map.remove("one");for (String key : map.keySet()) {System.out.print("[" + key + "," + map.get(key) + "] ");}日志如下:
[one,1] [two,2] 开始删除元素 1[two,2] 我们可以将其当做普通的 map 使用 , 不过是线程安全的 , 而且查询性能非常优秀 。
源码解析下面让我们一起学习下 ConcurrentSkipListMap 的源码实现 。
温馨提示:建议首先学习一下 skiplist 相关知识 , 参见 java 实现跳表(skiplist)及论文解读
本节内容较多 , 建议先收藏 , 再细细品味 。
jdk 版本java version "1.8.0_192"Java(TM) SE Runtime Environment (build 1.8.0_192-b12)Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mode)类定义public class ConcurrentSkipListMap延迟队列继承自 AbstractMap 类 , 并且实现了 ConcurrentNavigableMap 接口 。
- ConcurrentNavigableMap.java
public interface ConcurrentNavigableMapextends ConcurrentMap, NavigableMap{} ConcurrentMap 接口我们在 ConcurrentHashMap 中已经提到过 。NavigableMap 这个接口倒是挺新奇的 , 以前没怎么接触过 。
public interface NavigableMap extends SortedMap {} 这个继承自 SortedMap , 我们可以预见到实现过程中肯定会有 Comparator 相关实现 。算法笔记李大狗总是喜欢把算法笔记写在源码里 , 但是却不出现在文档里 。
这部分正是精髓所在 , 让我们一起学习一下 。
此类实现了树状二维链接的跳过列表 , 其中索引级别在于保存数据的基本节点不同的节点中表示 。
采用此方法而不是通常的基于数组的结构有两个原因:
1)基于数组的实现似乎遇到更多的复杂性和开销
2)对于遍历索引列表 , 我们可以使用比基础列表便宜的算法 。
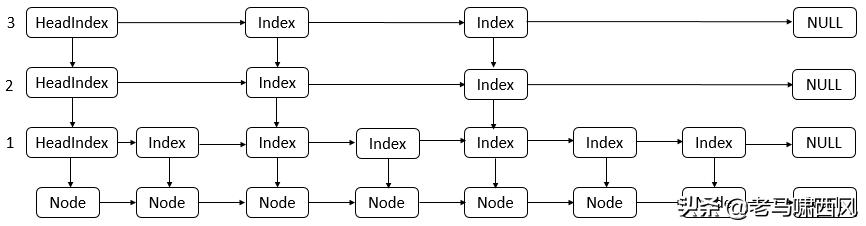
这是一张具有2级索引的可能列表的一些基础知识:
Head nodesIndex nodes+-+right+-++-+|2|---------------->| |--------------------->| |->null+-++-++-+ | down|| vvv+-++-++-++-++-++-+|1|----------->| |->| |------>| |----------->| |------>| |->null+-++-++-++-++-++-+ v|||||Nodesnextvvvvv+-++-++-++-++-++-++-++-++-++-++-++-+| |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null+-++-++-++-++-++-++-++-++-++-++-++-+基本列表使用HM链接有序集算法的变体 。这张图其实和我原来说的 skiplist 就是类似的 , 为了防止有些同学看得不习惯 , 我们补一张常规结构图:
 文章插图
文章插图数据结构
请参见蒂姆·哈里斯(Tim Harris) , “非阻塞链表的实用实现” , http://www.cl.cam.ac.uk/~tlh20/publications.html和Maged Michael“高性能动态无锁哈希表和基于列表的集”。
这些列表中的基本思想是在删除时标记已删除节点的“下一个”指针 , 以避免与并发插入发生冲突 , 并且在遍历以跟踪三元组(前驱 , 节点 , 后继)时进行标记 , 以检测何时以及如何取消链接这些已删除的节点 。
节点不使用标记位来标记列表删除(使用AtomicMarkedReference可能会很慢并且占用大量空间) , 而是使用直接CAS'able的下一个指针 。
在删除时 , 它们没有标记指针 , 而是拼接在另一个节点中 , 该节点可以被认为代表标记的指针(通过使用否则为不可能的字段值来指示) 。
使用普通节点的行为大致类似于标记指针的“盒装”实现 , 但是仅在删除节点时才使用新节点 , 而不是对每个链接都使用 。
这需要更少的空间并支持更快的遍历 。
即使JVM更好地支持带标记的引用 , 使用此技术的遍历仍可能会更快 , 因为任何搜索只需要比其他要求(检查尾随标记)提前读取一个节点 , 而不是在每次读取时都对标记位或其他内容进行屏蔽 。
这种方法保留了更改删除节点的下一个指针的HM算法所需的基本属性 , 以使它的任何其他CAS都将失败 , 但是通过更改指针以指向另一个节点而不是通过标记来实现该思想 。
- 微信|万字长文:谈谈我对视频号的思考
- 中文|万字长文:谷歌进入到退出中国市场的前因后果
- 万字详文:微软 VSCode IDE 源码分析揭秘
- 降噪耳机大PK:Sony、Bose、Skullcandy谁更强(万字干货)
- 万字详文干货:从无盘启动volumio看Linux启动原理
- 万字详文:深入理解 Lua 虚拟机
- 万字长文把 VSCode 打造成 C++ 开发利器,解决你的多重开发需求
- 谈论|B站百万粉丝up主发长文,谈论视频限流问题,B站审核过于严苛?
- Redmi Note系列全球销量破1.4亿 卢伟冰发长文总结成功原因
- Note|Redmi Note系列全球销量破1.4亿 卢伟冰发长文总结成功原因