k8s怎么了?为什么容器内存占用居高不下,频频 OOM?
最近我在回顾思考(写 PPT) , 整理了现状 , 发现了这个问题存在多时 , 经过一番波折 , 最终确定了元凶和相对可行的解决方案 , 因此分享一下排查历程 , 希望能够给大家一些借鉴的经验 。
时间线:
- 在上 Kubernetes 的前半年 , 只是用 Kubernetes , 开发没有权限 , 业务服务极少 , 忙着写新业务 , 风平浪静 。
- 在上 Kubernetes 的后半年 , 业务服务较少 , 偶尔会阶段性被运维唤醒 , 随之 “为什么你们的服务内存占用这么高 , 赶紧查” 。 此时大家还在为新业务冲刺 , 猜测也许是业务代码问题 , 但没有调整代码去尝试解决 。
- 在上 Kubernetes 的第二年 , 业务服务逐渐增多 , 普遍增加了容器限额 Limits , 出现了好几个业务服务是内存小怪兽 , 因此如果不限制的话 , 服务过度占用会导致驱逐 , 因此反馈语也就变成了:“为什么你们的服务内存占用这么高 , 老被 OOM Kill , 赶紧查” 。 据闻也有几个业务大佬有去排查(因为 OOM 反馈) , 似乎没得出最终解决方案 。
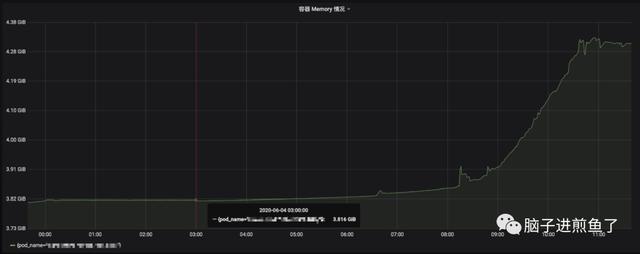
现象内存居高不下发现个别业务服务内存占用挺高 , 触发告警 , 且通过 Grafana 发现在凌晨(没有什么流量)的情况下 , 内存占用量依然拉平 , 没有打算下降的样子 , 高峰更是不得了 , 像是个内存炸弹:
 文章插图
文章插图并且我所观测的这个服务 , 早年还只是 100MB 。 现在随着业务迭代和上升 , 目前已经稳步 4GB , 容器限额 Limits 纷纷给它开道 , 但我想总不能是无休止地增加资源吧 , 这是一个大问题 。
进入重启怪圈有的业务服务 , 业务量小 , 自然也就没有调整容器限额 , 因此得不到内存资源 , 又超过额度 , 就会进入疯狂的重启怪圈:
 文章插图
文章插图重启将近 300 次 , 非常不正常了 , 更不用提所接受到的告警通知 。
排查猜想一:频繁申请重复对象出现问题的个别业务服务都有几个特点 , 那就是基本为图片处理类的功能 , 例如:图片解压缩、批量生成二维码、PDF 生成等 。
因此就怀疑是否在量大时频繁申请重复对象 , 而 Go 本身又没有及时释放内存 , 因此导致持续占用 。
sync.Pool基本上想解决 “频繁申请重复对象” , 我们大多会采用多级内存池的方式 , 也可以用最常见的 sync.Pool , 这里可参考全成所借述的《Go 夜读》上关于 sync.Pool 的分享 , 关于这类情况的场景:
当多个 goroutine 都需要创建同?个对象的时候 , 如果 goroutine 数过多 , 导致对象的创建数?剧增 , 进?导致 GC 压?增大 。
形成 “并发?-占?内存?-GC 缓慢-处理并发能?降低-并发更?”这样的恶性循环 。
验证场景在描述中关注到几个关键字 , 分别是并发大 , Goroutine 数过多 , GC 压力增大 , GC 缓慢 。 也就是需要满足上述几个硬性条件 , 才可以认为是符合猜想的 。
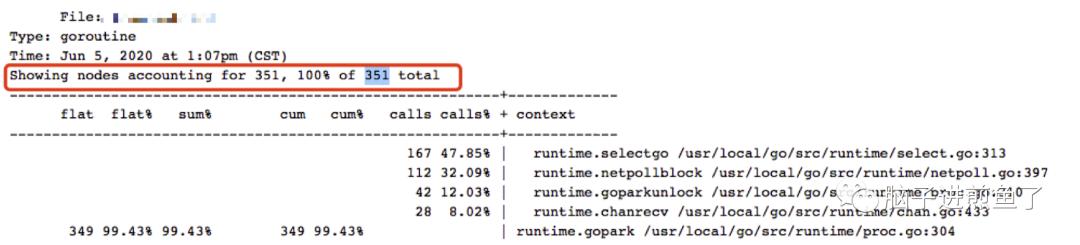
通过拉取 PProf goroutine , 可得知 Goroutine 数并不高:
 文章插图
文章插图另外在凌晨长达 6 小时 , 没有什么流量的情况下 , 也不符合并发大 , Goroutine 数过多的情况 , 若要更进一步确认 , 可通过 Grafana 落实其量的高低 。
从结论上来讲 , 我认为与其没有特别直接的关系 , 但猜想其所对应的业务功能到导致的间接关系应当存在(出问题的业务服务都是类似的功能) 。
猜想二:不知名内存泄露内存居高不下 , 其中一个反应就是猜测是否存在泄露 , 而我们的容器中目前只跑着一个 Go 进程 , 因此首要看看该 Go 应用是否有问题 。 这时候可以借助 PProf heap(可以使用 base -diff):
 文章插图
文章插图显然其提示的内存使用不高 , 那会不会是 PProf 出现了 BUG 呢 。 接下通过命令也可确定 Go 进程的 RSS 并不高 。
但 VSZ 却相对 “高” 的惊人 , 从结论上来讲 , 也不像 Go 进程内存泄露的问题 , 因此也将其排除 。
猜想三:madvise 策略变更
- 在 Go1.12 以前 , Go Runtime 在 Linux 上使用的是 MADV_DONTNEED 策略 , 可以让 RSS 下降的比较快 , 就是效率差点 。
- 在 Go1.12 及以后 , Go Runtime 专门针对其进行了优化 , 使用了更为高效的 MADV_FREE 策略 。 但这样子所带来的副作用就是 RSS 不会立刻下降 , 要等到系统有内存压力了才会释放占用 , RSS 才会下降 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?
- 团队|为什么项目管理非常重要?
- 猫腻|为什么拼多多上商品价格那么便宜还包邮?有什么猫腻?看完明白了
- 刷机|前几年满大街的“刷机”服务去哪里了,为什么大家都不爱刷机了?
- 手机|便宜没好货!为什么二手iPhone很便宜,这些手机都来自哪儿?
- 中国|相对论Vol.48丨一个“歪果仁”,为什么要在海外电商平台直播带中国货