「专利解密」西井科技 通用AI引擎架构
【嘉德点评】西井科技发明的AI芯片结构 , 利用同一种卷积引擎硬件结构来适配多种神经网络结构 , 从而有效的提高了乘法器资源的利用率以及实现了数据的动态分布 。
集微网消息 , 西井科技成立于2015年 , 从研发类脑芯片起步 , 专注于AI芯片和算法的研发落地 。 2016年 , 通过将技术和产品相结合方式服务于智慧港口 , 利用人工智能技术来完成各种复杂任务 , 提高港口自动化程度 。
而其解决港口客户对码头的智能化升级需求 , 并服务于集装箱数据智能识别、无人驾驶等项目 , 重点依靠的技术就是其自主研发的AI芯片 。 AI芯片主要应用于人工智能领域 , 其主要使用的算法就是神经网络算法 。
卷积神经网络是一种前馈神经网络 , 它的人工神经元可以响应一部分覆盖范围内的周围单元 , 对于大型图像处理有出色表现 。 它主要包括卷积层和池化层 , 目前 , 卷积神经网络已广泛应用于图像分类、物体识别、目标追踪 。
【「专利解密」西井科技 通用AI引擎架构】但是对于卷积神经网络的处理芯片 , 还存在着一系列的问题需要研究人员们去解决 , 例如如何通过乘法器和加法器的排布、设计提高乘法器资源的利用率 , 且根据不同的卷积核的尺寸实现不同的乘法器资源分配 , 以实现数据的动态分布 。
为此 , 西井科技在2020年6月24日申请了一项名为“芯片结构及其乘加计算引擎”的发明专利(申请号:202010587029.X) , 申请人为上海西井信息科技有限公司 。
根据该专利目前公开的资料 , 让我们一起来看看这项AI芯片技术吧 。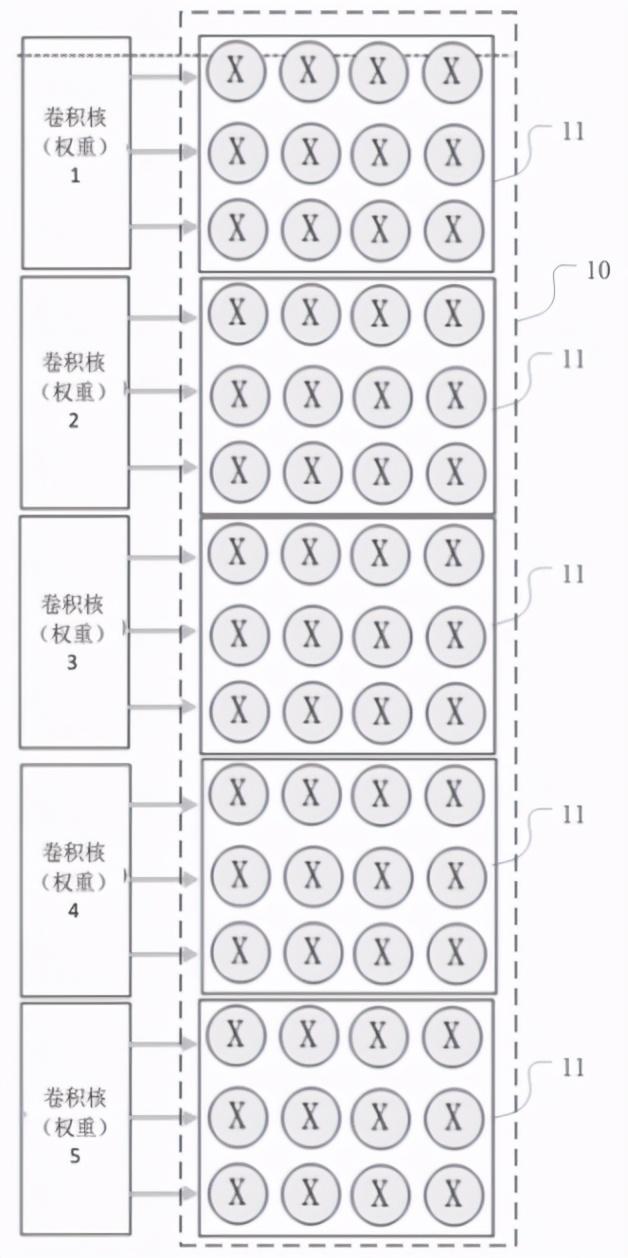 文章插图
文章插图
由于乘加计算引擎中包括多个卷积引擎 , 而卷积引擎又包括多个乘法器和加法器 , 如上图 , 为卷积引擎应用于尺寸为3*3的卷积核的示意图 。 3*3的卷积大小是目前主流神经网络模型中经常使用的 , 每个卷积引擎包括15*M*4个乘法器 , 每个卷积组11包括3行4列乘法器且对应一个卷积核计算 , 因此5组卷积组同时可以支持5个不同的卷积核并行计算 。
而上图只是一个以3*3卷积核为例的示例 , 在神经网络的实际应用中 , 还有5*5、7*7等常用卷积核 , 因此该专利对于其大小并没有进行限制 , 每个卷积引擎在应用于卷积核时 , 可以按照卷积核的尺寸划分为多个卷积组 , 每个卷积组的乘法器的行数与卷积核的行数一致 , 每个卷积组的乘法器的列数为N , 这样就可以根据不同的卷积核的尺寸实现不同的乘法器资源分配 , 进一步实现数据的动态分布 。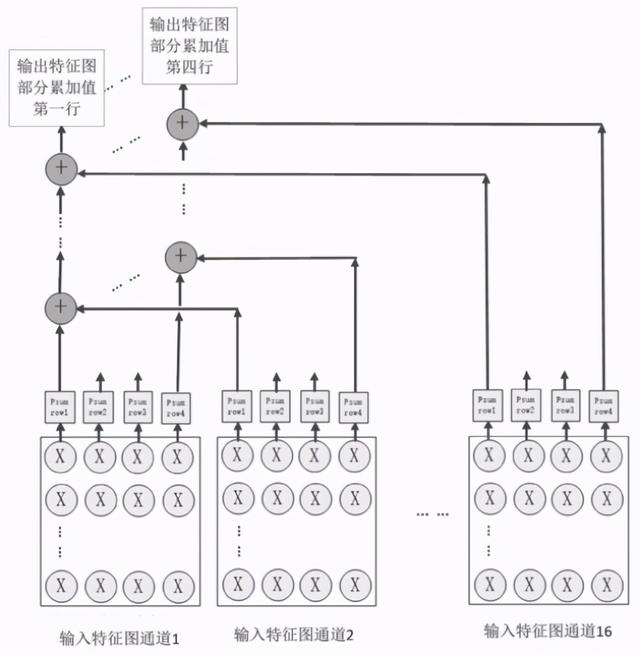 文章插图
文章插图
如上图 , 为这种卷积引擎的示意图 , 可以看到其具有多个输入特征图通道 , 这是为了当输入的特征图具有较高维度时可以进行并行加速 。 此外 , 这种卷积引擎还可以进行M倍于输入特征通道的并行加速 , 每个卷积组输出的N行部分累加值可以叠加到下一层的输入中 , 这与神经网络算法的设计也是相一致的 。
考虑到常用的主流卷积神经网络模型 , 输入特征通道的数量通常以偶数出现 , 一般是2的n次方的形式 。 由此 , 可以利用16个卷积组 , 用于支持16个不同的输入特征图的通道进行计算 。
图中所展示的16个不同的输入特征图 , 以一个输入像素点为例 , 一个输入像素点要进行16个通道的数据乘加 , 也就是16个乘法和M/2个加法 , 而在硬件的角度进行实现时 , 需要设计硬件加速方案 , 这种硬件加速方案由卷积引擎组成多级联结构 , 每组级联结构包括M/2个级联的处理单元 , 如下图所示 。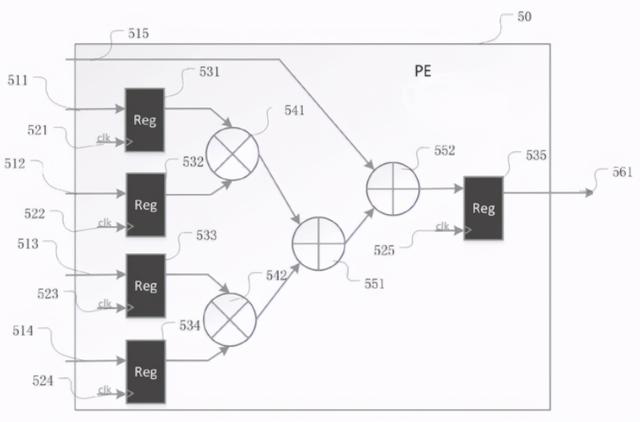 文章插图
文章插图
如图 , 为处理单元的示意图 , 每个处理单元50包括第一输入接口511至第五输入接口515、第一触发器531至第五触发器535、两个乘法器(541和542)以及两个加法器(551和552) , 此外 , 该结构还具有输出接口、时钟信号和触发器等部件 。
第一输入接口至第四输入接口分别与第一至第四触发器相连 , 时钟信号也与触发器相连 , 用于开启触发器 , 从而控制处理器进行乘加运算 。
而在16个输入特征通道的例子中 , 可以使用8个级联的方式来完成一个像素点在16个通道内的乘加运算 , 具体的连接方式如下入所示: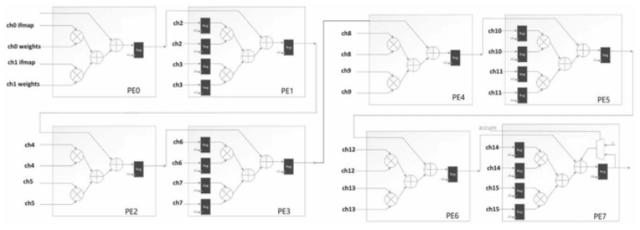 文章插图
文章插图
可以看到级联的处理单元的输出结果为一个输入特征图像素点的16通道乘累加结果 , 在这个架构下 , 以3*3的卷积核为例 , 9个输入像素点的16个输入特征通道值进行相加 , 在6个时钟周期下生成最终的卷积操作的运算结果 。
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 摄像头|摄像头造型别出心裁 realme全新手机设计专利曝光
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- mini|电影、mini 与「当日完稿」工作流
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 公司|英联股份:“一种全自动易开盖冲压卷边注胶生产线”获发明专利证书
- P50|全新液体镜头专利:华为P50系列首发人眼级对焦速度
- iPhone12|iPhone12「超大杯」拍照解禁:与Pro拉不开差距
- 供应链|一座快手「重镇」的货端升级