按关键词阅读:
该理论不仅可以解释为什么神经网络在某些函数上可以很好地泛化,而且还可以预测出给定的网络架构适合哪些函数,让我们可以从第一性原理出发为给定的问题挑选最合适的架构。
为此,本文作者进行了一系列近似,他们首先将真实的网络近似为理想化的宽度无限的网络,这与核回归是等价的。接着,作者针对核回归的泛化推导出了新的近似结果。这些近似的方程能够准确预测出原始网络的泛化性能。
本文的研究建立在无限宽网络理论的基础之上。该理论表明,随着网络宽度趋于无穷大,根据类似于中心极限定理的结果,常用的神经网络会有非常简单的解析形式。特别是,采用均方误差(MSE)损失的梯度下降训练的足够宽的网络等价于 NTK 核回归模型。利用这一结论,研究者们研究者们通过对核回归的泛化性能分析将相同的结论推广至了有限宽的网络。
Bordelon 等人于 2020 年发表的 ICML 论文「Spectrum dependent learning curves in kernel regression and wide neural networks」指出,当使用 NTK 作为核时,其表达式可以精准地预测学习任意函数的神经网络的 MSE。我们可以认为,当样本被添加到训练集中时,网络会在越来越大的输入空间中泛化得很好。这个可学习函数的子空间的自然基即为 NTK 的特征基,我们根据其特征值的降序来学习特征函数。
具体而言,本文作者首先形式化定义了目标函数的可学习性,该指标具备 MSE 所不具备的一些理想特性。接着,作者使用可学习性来证明了一个加强版的「没有免费午餐定理」,该定理描述了核对正交基下所有函数的归纳偏置的折中。该定理表明,较高的 NTK 本征模更容易学习,且这些本征模之间在给定的训练集大小下的学习能力存在零和竞争。作者进一步证明,对于任何的核或较宽的网络,这一折中必然会使某些函数的泛化性能差于预期。

文章插图

文章插图
其中,θ是一个参数向量。令训练样本为x,目标值为y,测试数据点为x',假设我们以较小的学习率η执行一步梯度下降,MSE 损失为。则参数会以如下所示的方式更新:
我们希望知道对于测试点而言,参数更新的变化有多大。为此,令θ线性变化,我们得到:

文章插图
其中,我们将神经正切核 K 定义为:
值得注意的是,随着网络宽度区域无穷大,修正项可以忽略不计,且在任意的随机初始化后,在训练的任何时刻都是相同的,这极大简化了对网络训练的分析。可以证明,在对任意数据集上利用 MSE 损失进行无限时长的训练后,网络学习到的函数可以归纳如下:
直观地说,核是一个相似函数,我们可以将它的高特征值特征函数解释为「相似」点到相似值的映射。在这里,我们的分析重点在于对泛化性的度量,我们将其称之为「可学习性」,它量化了标函数和预测函数的对齐程度:
我们将初始化的神经网络f和学习目标函数f^分别用特征向量展开:
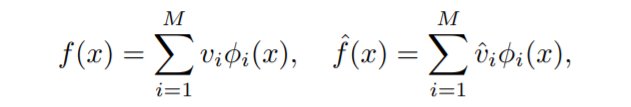
文章插图
![]()
稿源:(雷锋网)
【傻大方】网址:http://www.shadafang.com/c/1115960cH021.html
标题:伯克利|UC伯克利发现「没有免费午餐定理」加强版:每个神经网络,都是一个高维向量( 二 )