从零到千万用户,我是如何一步步优化MySQL数据库的?( 二 )
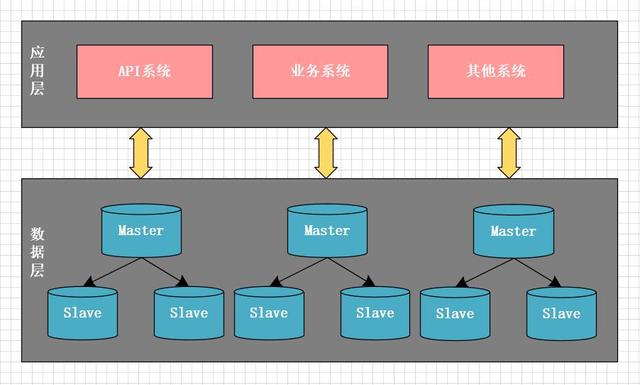
另一方面 , 业务越来越复杂 , 多个应用系统使用同一个数据库 , 其中一个很小的非核心功能出现延迟 , 常常影响主库上的其它核心业务功能 。 这时 , 主库成为了性能瓶颈 , 我们意识到 , 必须得再一次做架构升级 , 将主库做拆分 , 一方面以提升性能 , 另一方面减少系统间的相互影响 , 以提升系统稳定性 。 这一次 , 我们将系统按业务进行了垂直拆分 。 如下图所示 , 将最初庞大的数据库按业务拆分成不同的业务数据库 , 每个系统仅访问对应业务的数据库 , 尽量避免或减少跨库访问 。
 文章插图
文章插图垂直分库过程 , 我们也遇到不少挑战 , 最大的挑战是:不能跨库join , 同时需要对现有代码重构 。 单库时 , 可以简单的使用join关联表查询;拆库后 , 拆分后的数据库在不同的实例上 , 就不能跨库使用join了 。
例如 , 通过商家名查询某个商家的所有订单 , 在垂直分库前 , 可以join商家和订单表做查询 , 也可以直接使用子查询 , 如下如示:
select * from tb_order where supplier_id in (select id from supplier where name=’商家名称’);分库后 , 则要重构代码 , 先通过商家名查询商家id , 再通过商家id查询订单表 , 如下所示:select id from supplier where name=’商家名称’select * from tb_order where supplier_id in (supplier_ids )垂直分库过程中的经验教训 , 使我们制定了SQL最佳实践 , 其中一条便是程序中禁用或少用join , 而应该在程序中组装数据 , 让SQL更简单 。 一方面为以后进一步垂直拆分业务做准备 , 另一方面也避免了MySQL中join的性能低下的问题 。经过近十天加班加点的底层架构调整 , 以及业务代码重构 , 终于完成了数据库的垂直拆分 。 拆分之后 , 每个应用程序只访问对应的数据库 , 一方面将单点数据库拆分成了多个 , 分摊了主库写压力;另一方面 , 拆分后的数据库各自独立 , 实现了业务隔离 , 不再互相影响 。
水平分库读写分离 , 通过从库水平扩展 , 解决了读压力;垂直分库通过按业务拆分主库 , 缓存了写压力 , 但系统依然存在以下隐患:
- 单表数据量越来越大 。 如订单表 , 单表记录数很快就过亿 , 超出MySQL的极限 , 影响读写性能 。
- 核心业务库的写压力越来越大 , 已不能再进一次垂直拆分 , 此时的系统架构中 , MySQL 主库不具备水平扩展的能力 。
 文章插图
文章插图水平分库面临的第一个问题是 , 按什么逻辑进行拆分 。 一种方案是按城市拆分 , 一个城市的所有数据在一个数据库中;另一种方案是按订单ID平均拆分数据 。 按城市拆分的优点是数据聚合度比较高 , 做聚合查询比较简单 , 实现也相对简单 , 缺点是数据分布不均匀 , 某些城市的数据量极大 , 产生热点 , 而这些热点以后可能还要被迫再次拆分 。 按订单ID拆分则正相反 , 优点是数据分布均匀 , 不会出现一个数据库数据极大或极小的情况 , 缺点是数据太分散 , 不利于做聚合查询 。 比如 , 按订单ID拆分后 , 一个商家的订单可能分布在不同的数据库中 , 查询一个商家的所有订单 , 可能需要查询多个数据库 。 针对这种情况 , 一种解决方案是将需要聚合查询的数据做冗余表 , 冗余的表不做拆分 , 同时在业务开发过程中 , 减少聚合查询 。
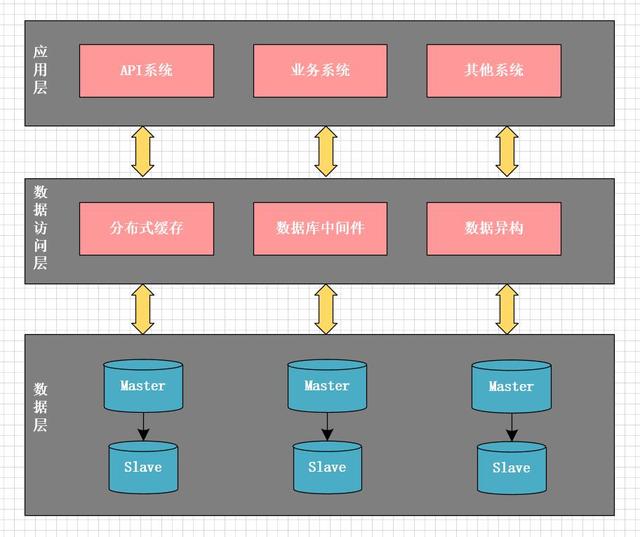
经过反复思考 , 我们最后决定按订单ID做水平分库 。 从架构上 , 将系统分为三层:
- 应用层:即各类业务应用系统
- 数据访问层:统一的数据访问接口 , 对上层应用层屏蔽读写分库、分表、缓存等技术细节 。
- 数据层:对DB数据进行分片 , 并可动态的添加shard分片 。
- 分布式缓存
- 数据库中间件
- 数据异构中间件
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 手机|这个超强App,让手机快3倍,流畅到起飞
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些