从零到千万用户,我是如何一步步优化MySQL数据库的?
业务背景我之前呆过一家创业工作 , 是做商城业务地 , 商城这种业务 , 表面上看起来涉及的业务简单 , 包括:用户、商品、库存、订单、购物车、支付、物流等业务 。 但是 , 细分下来 , 还是比较复杂的 。 这其中往往会牵扯到很多提升用户体验的潜在需求 。 例如:为用户推荐商品 , 这就涉及到用户的行为分析和大数据的精准推荐 。 如果说具体的技术的话 , 那肯定就包含了:用户行为日志埋点、采集、上报 , 大数据实时统计分析 , 用户画像 , 商品推荐等大数据技术 。
公司的业务增长迅速 , 仅仅2年半不到的时间用户就从零积累到千万级别 , 每天的访问量几亿次 , 高峰QPS高达上万次每秒 。 数据的写压力来源于用户下单 , 支付等操作 , 尤其是赶上双十一大促期间 , 系统的写压力会成倍增长 。 然而 , 读业务的压力会远远大于写压力 , 据不完全统计 , 读业务的请求量是写业务的请求量的50倍左右 。
接下来 , 我们就一起来看看数据库是如何升级的 。
最初的技术选型作为创业公司 , 最重要的一点是敏捷 , 快速实现产品 , 对外提供服务 , 于是我们选择了公有云服务 , 保证快速实施和可扩展性 , 节省了自建机房等时间 。 整体后台采用的是Java语言进行开发 , 数据库使用的MySQL 。 整体如下图所示 。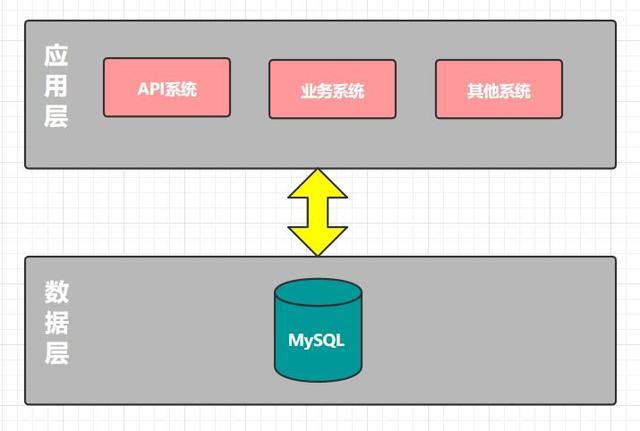 文章插图
文章插图
读写分离随着业务的发展 , 访问量的极速增长 , 上述的方案很快不能满足性能需求 。 每次请求的响应时间越来越长 , 比如用户在H5页面上不断刷新商品 , 响应时间从最初的500毫秒增加到了2秒以上 。 业务高峰期 , 系统甚至出现过宕机 。 在这生死存亡的关键时刻 , 通过监控 , 我们发现高期峰MySQL CPU使用率已接近80% , 磁盘IO使用率接近90% , slow query(慢查询)从每天1百条上升到1万条 , 而且一天比一天严重 。 数据库俨然已成为瓶颈 , 我们必须得快速做架构升级 。
当Web应用服务出现性能瓶颈的时候 , 由于服务本身无状态 , 我们可以通过加机器的水平扩展方式来解决 。而数据库显然无法通过简单的添加机器来实现扩展 , 因此我们采取了MySQL主从同步和应用服务端读写分离的方案 。
MySQL支持主从同步 , 实时将主库的数据增量复制到从库 , 而且一个主库可以连接多个从库同步 。 利用此特性 , 我们在应用服务端对每次请求做读写判断 , 若是写请求 , 则把这次请求内的所有DB操作发向主库;若是读请求 , 则把这次请求内的所有DB操作发向从库 , 如下图所示 。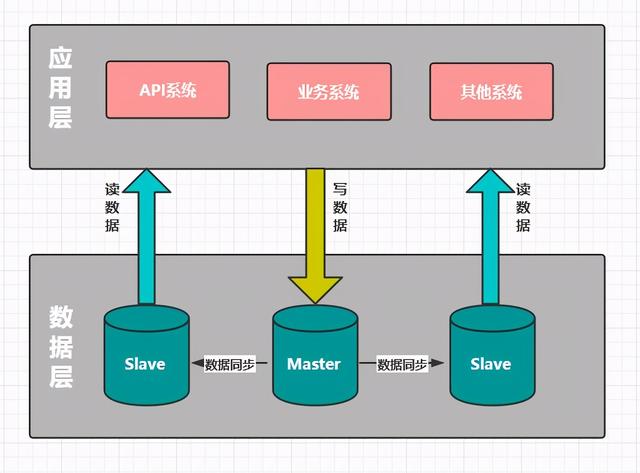 文章插图
文章插图
实现读写分离后 , 数据库的压力减少了许多 , CPU使用率和IO使用率都降到了5%以内 , Slow Query(慢查询)也趋近于0 。 主从同步、读写分离给我们主要带来如下两个好处:
- 减轻了主库(写)压力:商城业务主要来源于读操作 , 做读写分离后 , 读压力转移到了从库 , 主库的压力减小了数十倍 。
- 从库(读)可水平扩展(加从库机器):因系统压力主要是读请求 , 而从库又可水平扩展 , 当从库压力大时 , 可直接添加从库机器 , 缓解读请求压力 。
那如何监控主从同步状态?在从库机器上 , 执行show slave status , 查看Seconds_Behind_Master值 , 代表主从同步从库落后主库的时间 , 单位为秒 , 若主从同步无延迟 , 这个值为0 。 MySQL主从延迟一个重要的原因之一是主从复制是单线程串行执行(高版本MySQL支持并行复制) 。
那如何避免或解决主从延迟?我们做了如下一些优化:
- 优化MySQL参数 , 比如增大innodb_buffer_pool_size , 让更多操作在MySQL内存中完成 , 减少磁盘操作 。
- 使用高性能CPU主机 。
- 数据库使用物理主机 , 避免使用虚拟云主机 , 提升IO性能 。
- 使用SSD磁盘 , 提升IO性能 。 SSD的随机IO性能约是SATA硬盘的10倍甚至更高 。
- 业务代码优化 , 将实时性要求高的某些操作 , 强制使用主库做读操作 。
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 手机|这个超强App,让手机快3倍,流畅到起飞
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些