算法|如何将RTC中基于AI的音频算法有效的产品化( 二 )
总结上面提到的两点,我认为AI的效果,它的优势其实已经被证实了,但由于算力和数据等各方面的问题以及AI模型本身的一些问题,它现在还达不到完全替换传统信号处理方法的阶段。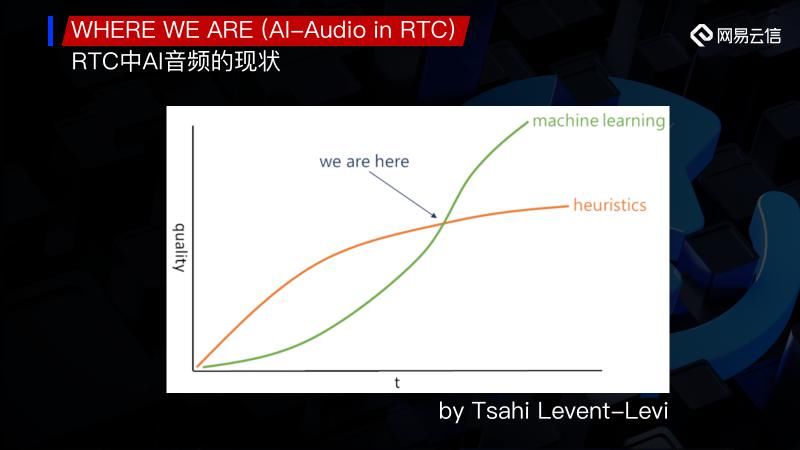
文章插图
RTC领域的Tsahi专门就这一问题做了很多的评估,这里我们引用了Tsahi的一张图,根据他的分析目前我们的位置刚好是处于一个临界点。也就是从现在向后走,当我们的算力得到进一步提升,或者是我们在数学或各个基础学科上有所突破,可能会迎来整个AI的一个大爆发,但就目前看来看我们正处于一个临界的位置。所以今天我想和大家一起探讨的是如何在临界位置去扬长避短,如何应用AI的优势,然后将它有机的结合在我们的RTC里面。
“模块化”
TITTLES
文章插图
“模块化”就是其中的一个有效途径,模块化对应的主要是:例如我们有一个端到端的长链路,有一个降噪的算法。长链路就是说从数据的输入一直到数据的输出,如果我们直接将其当成黑盒来训练,这就是一个非常长的端到端的算法。那对应的模块化就是我们“能不能将这个长链路分解成一些小的模块”,其中一些小的模块是很适合用AI去做的,我们用小的模块去做,既节省了开销,也能够解决很多之前我们提到的问题,就像是让专业的人去做对应专业的事情。
示例一:音频降噪中的AI算法
文章插图
举个例子,这里是一个比较通用的端到端的AI降噪算法。我们来看如图下方所示的训练的过程,首先将输入的信号放到频域STFT,然后就直接拿它的Magnitude,先不用相位,直接把它的一些频点拿去,将它的一些Feature提取出来做Training,这是一个非常直观的训练过程。
训练完成后直接放在我们的实时的系统里面,在实时系统里进行同样的操作。然后我们将相位拿出来,先放在这里不做任何操作。接着我们可以通过做一个Noisy Floor 或者是简单的VAD判断一下,然后同样进行特征提取,放到预先训练并Frozen好的降噪的模块里进行处理,最后和我们的Phase结合,得到我们的输出。
其实很多的AI算法如果从宏观的角度来考虑,只需要有一个输入,有一个输出,其它的就都可以全部交给机器,让它自己去训练。但这就会遇到我们刚才提的三个问题:计算复杂度,泛化能力和鲁棒性,也许我们可以简单的做一些权衡,比如牺牲一些计算时间去换取更高鲁棒性,但其实整体上还是很难突破这个瓶颈。
文章插图
那么,怎么有效的解决这个问题呢?这里我们看一个传统信号处理中的降噪算法,跟刚才介绍到的方法比较像,唯一不同的地方是它分别添加了一个Speech Estimation的模型和Noise Estimation模型,这里面会有比如说类似于先验概率(Prior-SNR)这样的计算,再通过后面的结合就会有类似于对于每个频点有一个gain计算出来,结合起来后处理然后再输出。
那我们看一下,这里的Noise Estimation模块,其实是比较适合拿出来单独做深度学习训练的小模块,特别是假设噪声是一个Stationary Noise的稳态噪声,是更适合的。在这里,我们可以不用端到端的去训练整个AI的模型,而是把这个noise estimation训练成一个噪声估计模型。后面我们在实时系统里面,每次遇到Noise Estimation,我们就不再是一个传统的Noise Estimation,我们就会用这个训练好的Model 去把我们想要的一些参数和feature都计算出来。
还有一个就是VAD模块,这里的VAD不是时域上的VAD,而是对于每个频点有一个判断。这种Classification的问题是很适合通过AI 的Model 来做的,这也是可以单独拿出来做训练的模块。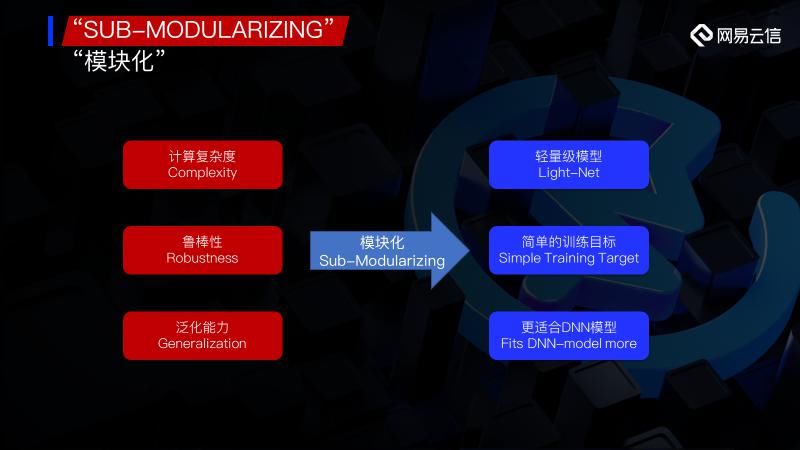
文章插图
我们再回顾一下这三个问题:计算复杂度、鲁棒性和泛化能力,通过模块化,计算复杂度的问题我们可以用一个轻量级的网络来解决。刚才我们看了端到端的NS图,我们要解决这个问题,一般会用到层数稍微偏多的网络,因为我们要解决的问题是比较复杂的,需要从噪声和语音叠加的信号里面,将噪声给抑制掉。但是如果我们换作只对Noise 去进行一个Estimation,那本身的问题就会比较简单,也就是我们提到的一个简单的训练目标。对于这种训练目标,这些问题本身也会更适合DNN的Model 去学习。
示例二:声音场景检测
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 荣耀V30|麒麟990+40W快充,昔日猛将彻底沦为清仓价?网友:太遗憾
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?