算法|如何将RTC中基于AI的音频算法有效的产品化
正文字数:4854阅读时长:7分钟
将AI算法任务模块化是一种解决AI音频处理算法应用效果不够好、通用/扩展性差、计算开销大等问题的有效方法。网易云信 资深音频算法工程师 郝一亚在LiveVideoStackCon 2020北京站的演讲中就“模块化”是怎样解决上述问题的,“模块化”工程实现的可行性等问题进行详细解析,并举例介绍了目前市场中的几个“模块化”的成功案例。
文 / 郝一亚
整理 / LiveVideoStack
文章插图
大家好,我是郝一亚,来自网易云信,目前主要负责网易云信在RTC领域的音频算法的研发。本次我想要分享的题目是如何将AI音频算法应用、结合到RTC中,我会结合自己在国外的一些研究和开发的经验,包括网易云信在AI音频算法应用实战当中的一些经验总结,和大家一起聊一聊如何将AI音频算法与RTC有机结合。
RTC中AI音频的现状
TITTLES
文章插图
首先,第一个问题是RTC中AI音频到底是处于一个什么阶段?可能大家会接收到比较极端的两种不同信息:第一种就是目前AI算法如Deep Learning等在各行业都开始广泛应用,效果也比较好;另外一种就是大家在实际的工作当中,可能会感受到AI在某些情况下,比如说在训练集和一些特定Case下的感觉还不错,但很难落地、上线到实际的产品当中,存在着各种各样的问题和困难。那么首先我们来简单分析下目前AI音频到底是处于一个怎样的阶段。
1.1 音频处理中AI的力量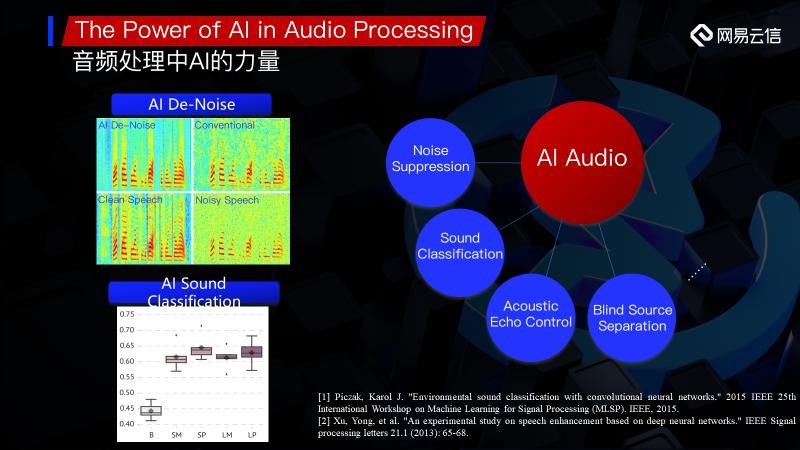
文章插图
先来介绍一些好的方面,例如结合CNN的降噪,最早是因为AI在Computer vision领域成功的应用,我们就可以把这种语谱图(如图所示)作为一个图像的概念。这样的方式为CNN和降噪模块的有机结合提供了一个契机。
图中展示的就是一个CNN的降噪,我们可以看到,如左上角图所示,右边是传统的降噪方法,Noisy Speech相对于原始信号,它的信噪比已经很低了。而左边是一个MMSE的算法,相比于传统方法是有一定提升的,特别是非语音段。但我们可以从中看到特别是高频的部分,还是存在很多的残留。从横向对比来看,AI算法在基于传统的方法之上,可以让我们在非语音段有对噪声有一个非常好的抑制,其结果对比原始信号,可以看到其实相似度非常高,肉眼基本很难区别。
下面的例子是一个场景的分类,说到有关分类的问题,其实我个人觉得这是AI比较擅长的一个方向。我们可以看到Noise Suppression、Sound Classification、Acoustic Echo Control,Blind Source Separation这四种方式其实都是结合神经网络的方式。如图左下角所示的AI Sound Classification是一个基于简单的模型的方式,是不涉及任何神经网络的。我们可以看到尽管因为任务的难度较大,所能达到的只有百分之六十左右的准确率,但和传统方法相比还是有很大程度的提升。
之所以列举出这两个例子,是希望让大家知道其实我们在音频上有很多的模块已经可以用AI来解决,包括这两个例子在内,以及之前提到过的AEC,还有NLP(非线性处理)模块其实现在也有很多研究是在结合AI来做,除此之外还包括BSS (盲源分离),目前我知道有些落地的项目也是基于AI的。所以总得来说AI在音频算法中的应用是多种多样的,是多点开花的。
1.2 音频处理中AI的挑战与局限
文章插图
接下来介绍AI音频的一些局限,在这里我主要总结了三点:第一点我们能想到的就是AI的计算量和计算复杂度的问题。通常来说AI的模型,特别是现在神经网络的模型,它的计算量平均来说会比传统算法更大一些。对于大部分终端设备来说,其算力是有限的,PC设备相对还好一些,但是我们还需要保证实时性,因此将AI的模型全部附加在终端设备上,对于设备的硬件来说还是有比较大的压力的。第二点是泛化能力。在数据驱动的方向上,泛化能力有限一直是一个问题。比如说我们有自己的数据集,那么我们该怎么用有限的数据来cover更多的结果,特别是由于RTC覆盖的业务场景会非常多,比如教育领域、泛娱乐领域,每个领域的场景都会有所不同,AI算法要cover所有场景更是难上加难;最后一点是鲁棒性,和泛化性略有相似,但更多的是指一些突发情况,比如在某些场景中突发的噪声、时间上的跳变、参考时间的不齐等等。在这些情况的影响下,系统够不够稳定?系统会不会犯错?犯的错会不会是一个大错?这其实很考验AI的算法,就相当于我们把所有的东西丢到一个黑盒子里面,看它是否能够全部的、真正的运行正常。
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 荣耀V30|麒麟990+40W快充,昔日猛将彻底沦为清仓价?网友:太遗憾
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?