阿里|阿里/网易/汽车之家画像标签体系
编辑导语:上一篇《阿里/网易/美团/58用户画像中的ID体系建设》,笔者进行了画像体系中的地基建设,ID-Mapping体系的打通;接下来一起探究阿里、网易、汽车之家标签体系搭建方法,我们一起来看一下。
文章插图
一、阿里为打破数据孤岛,创造更大的数据价值,阿里设计了OneEntity来提供全域数据与服务;OneEntity体系主要包含统一实体、全域标签、全域关系、全域行为4大类。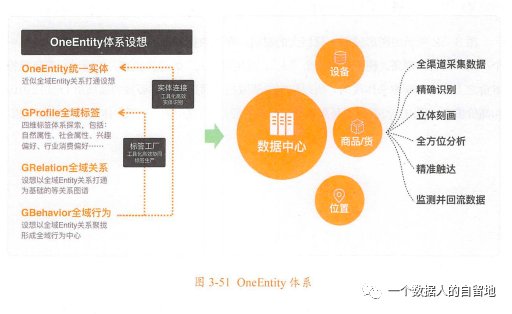
文章插图
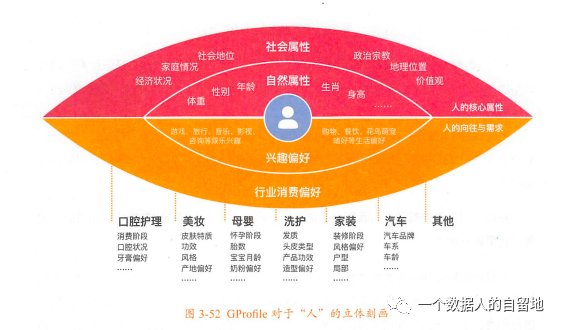
1. 标签分类其中GProfile全域标签的分类,将“人”的立体刻画划分为“人的核心属性”和“人的向往与需求”2大部分,具体包含4大类:
人的核心属性,可分为自然属性、社会属性:
- 自然属性:是指人的肉体存在及其特征,是人自出生后自然存在的,一般不会因人为因素发生较大的改变;例如“性别”“生肖”“年龄”“身高”“体重”等。
- 社会属性:指人在实践活动基础上产生的一切社会关系的总和。人一旦进入社会就会产生社会属性;例如经济状况、家庭状况、社会地位、政治宗教、地理位置、价值观等。
- 兴趣偏好:是人堆非物化对象的内在心理向往与外在行为表达,是一种法子内心的本能喜好,与物质无必然关系;例如渴望爱情、需要安全感、讨厌脏乱环境等。
- 行为消费偏好:是人对物化对象的需求与外在行为表达,涉及各行业,与物质世界存在千丝万缕的联系;例如母婴行业偏好、美妆行业偏好、洗护行业偏好、家装行业偏好等。
文章插图
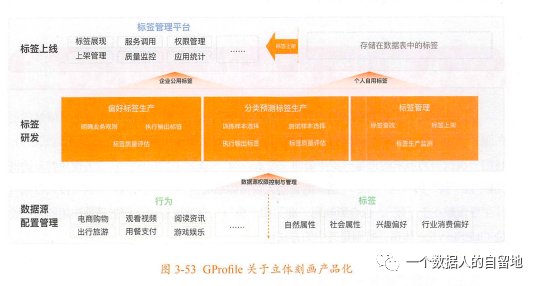
2. 标签萃取标签的萃取工作包含:数据采集、清洗,去噪声并统一、反复试用并确定最佳算法及模型、为模型选择计算因子并对模型中的每一个计算因子调配权重、产出标签质量评估报告以辅助验收。
我们随机抽查了若干个在用的标签,预估工作量和工作周期,一个有价值的标签的萃取,平均耗时2周。
【 阿里|阿里/网易/汽车之家画像标签体系】慢的主要原因:
- 由于萃取流程复杂,每个标签萃取都依赖底层的基础数据,而较少依赖上一层汇总的数据中间层数据;
- 大量重复的人力,对应的标签萃取逻辑时可以复用的,包含算法的选择、模型训练和计算因子的加权等;但由于不同人来做,造成了很多重复工作。
文章插图
- 首先,数据源层面:建设一套完整的数据源,以OneEntity体系为核心,将OneEntity相关实体及其行为全部串联起来,与存量的标签一起作为数据源。
- 其次,标签计算层面:将标签萃取逻辑沉淀为2种,分别对应到偏好类标签和分类预测类标签的工具型产品的生产过程中,包含计算因子、权重等业务规则、数据样本选择、模型与算法选择等。
- 最后,标签监测层面:沉淀质量评估报告和生产监测、上线等管理流程。
在这个过程中,参与的角色也发生了变化,从原本的以数据产品经理、数仓工程师、数据科学家为主导;转变为对业务更为熟悉的业务人员、数据分析师为主导。
GRelation全域关系、GBehavior全域行为在此不再赘述。
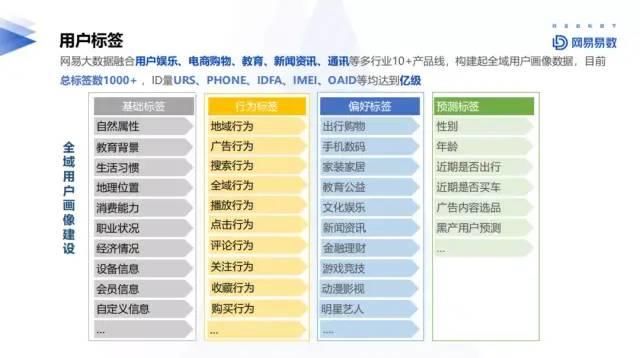
二、网易网易大数据融合用户娱乐、电商购物、教育、新闻资讯、通讯等多行业10+产品线,构建起全域用户画像数据,目前总标签1000+,ID量URS、phone、idfa、IMEI、oaid等均达到忆级。
1. 标签分类1)基础标签
性别、年龄、教育背景、生活习惯(早起晚起)、地理位置(POI信息)、职业状况、经济情况(有车有房)、设备信息(手机、运营商等)、会员信息(会员等级)、衍生信息。
其中衍生标签,如评估是否已婚,在原由标签体系下没有此类标签;但可通过多个标签进行组合生成新的标签,包含是否有小孩、30岁等条件组合。
文章插图
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 自动驾驶汽车|海外|自动驾驶无法可依?美国多个团体联合发布自动驾驶立法大纲
- 车辆|魔道之争,自主驾驶汽车会不会变成犯罪分子的工具?
- 注册|阿里申请注册“爆改吧!小店”商标,打造线下特色实体小店
- 车一族|直播|@爱车一族:60分钟穿越汽车的前世今生
- 中国汽车|2020年,我们攒了一个局,串了一条链,下了一盘棋
- 专项|青阳县交通运输局开展巡游出租汽车规范服务专项检查
- 智慧城市|被汽车物联网控制的未来,这是我们向往的新生活吗?
- 耽误|被阿里耽误的虾米的一生