【 百度|2021年中国数据标注行业竞争格局、市场份额及发展趋势分析 行业并购成为趋势】1、中国数据标注市场竞争格局:头部企业为自建数据团队,中小数据供应商占比较大
目前,我国国内数据标注市场第一梯队包括头部公司组建自己的数据标注部门,京东(京东众智)、百度(百度众测)、腾讯、阿里(阿里数据标注)都已经拥有自己的标注平台和工具。头部公司之外,国内近年兴起众多数据标注公司,如龙猫数据、Testin云测、倍赛BasicFinder、数据堂等。这些公司仅次于头部公司,都具有相当的规模,位于第二梯队。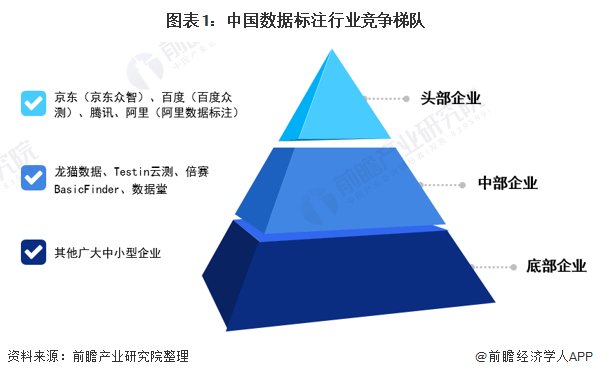
文章插图
在中国数据标注行业参与主体中,按规模划分,品牌数据服务商、中小数据供应商和需求方自建基础数据团队构成市场竞争关系,为AI数据标注市场的主要供应方,在2019年AI数据标注市场份额占比分别为30.4%、47.0%和22.6%,目前中小数据供应商是市场中的主要供应力量。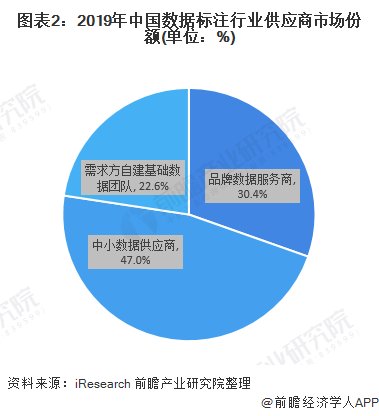
文章插图
2、中国数据标注行业按模式分为数据标注公司和众包平台,服务领域广泛
中国数据标注行业参与企业类型按参与模式主要分为众包平台和自建工厂(专业数据标注公司)两种模式。2020年数据标注公司排行榜中,Testin云测、数据堂、龙猫数据位居前三;数据标注众包平台排行榜中,京东众智、百度众测、数据堂位居前三。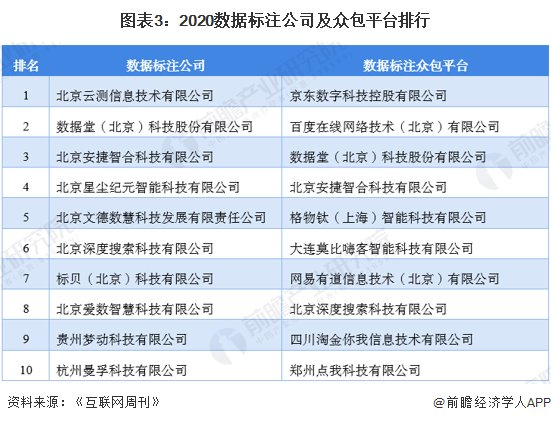
文章插图
从数据标注代表企业业务布局来看,大部分数据标注服务商提供文本、语音、图像、视频等各类型数据标注,服务应用领域涵盖安防、智能驾驶、医疗、教育、金融等多个领域,主要客户包括科技公司、人工智能企业、传统企业、政府部门、科研机构等。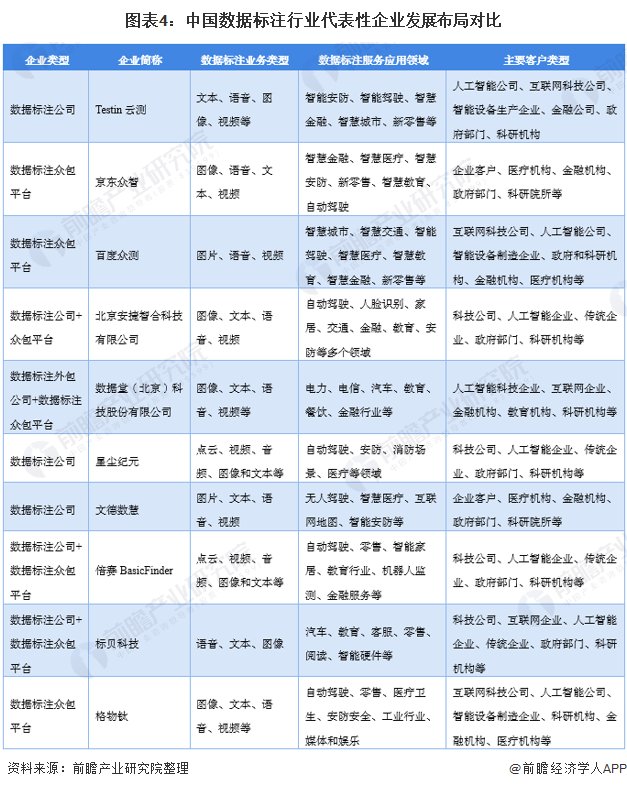
文章插图
3、业务偏重视觉类的企业多拥有自建标注基地,多分布在山西、河南等地
AI数据标注业内玩家按照业务方向和进入市场的时机可做粗略划分,包括早期进入玩家、中晚期进入玩家、偏重视觉类业务玩家、偏重语音类业务玩家等。其中,业务更偏重语音类数据的玩家,通常拥有较多的自有知识产权数据集;拥有自建标注基地或全职标注团队的则多为偏重视觉类的玩家。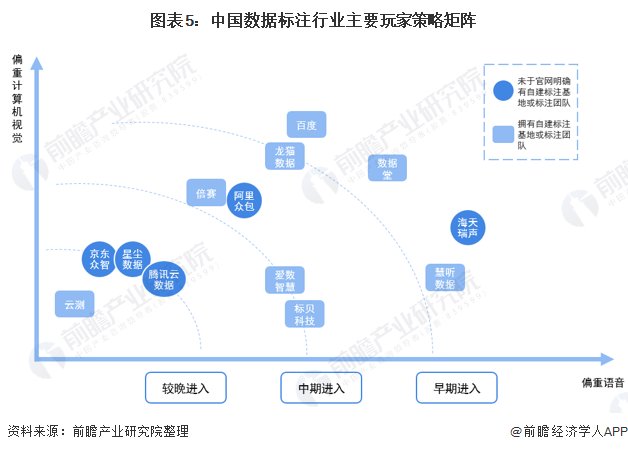
文章插图
作为人工智能产业链中必不可少的一环,发展AI数据标注服务成为了各地方推进AI建设的重要方向之一,贵州、山西、重庆等地相继出台指导意见,引入科技公司,共建数据基地、数据交易中心,打造具有地方特色的人工智能产业园。
目前,众多数据标注公司自建标注基地或团队,如百度的“百度山西的AI数据标注基地”、“百度大数据百鸟河基地”,数据堂的“数据堂保定数据加工基地”、“数据堂合肥数据基地”、“数据堂北京TTS录音中心”等,多分布在山西、河南等地。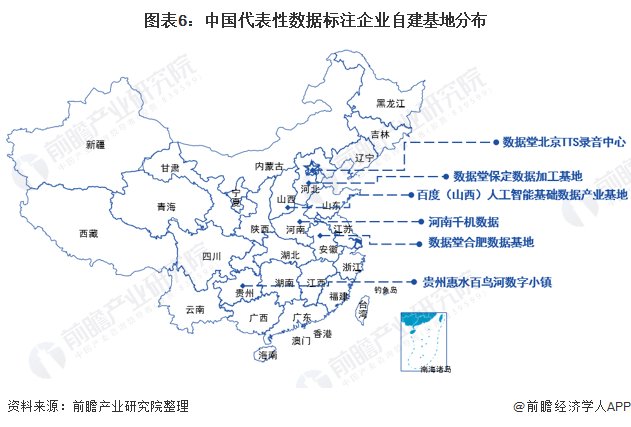
文章插图
4、北京、上海、成都为需求企业分布前三地区,杭州数量下滑
从需求企业来看,根据AI数据标注猿统计数据显示,2020年4月,国内数据标注业务相关公司数量为565家,2020年12月,数量增长至705家。从数据标注需求企业地区分布情况来看,截至2020年12月,北京、上海、成都、深圳、杭州为数据标注企业分布TOP5城市,企业数量分别达到185家、84家、68家、63家、46家;其中北京、上海、成都、深圳企业数量均较2020年4月有所上升,杭州企业数量较2020年4月有所下降。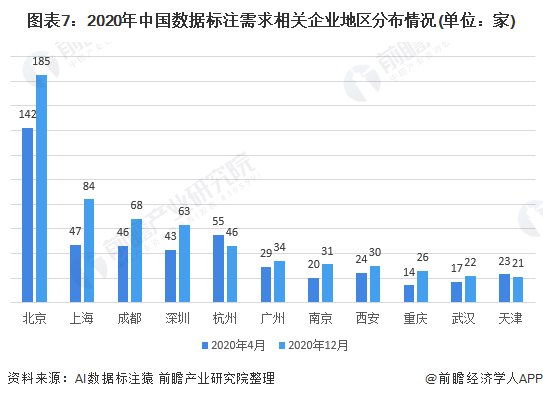
文章插图
5、中国数据标注市场集中度较低,未来将有所提升,行业并购成为趋势
2019年,AI数据标注行业CR5(前五大企业市场份额)为26.2%,处于低集中竞争阶段,行业活力充足,发展空间良好。前五大企业中,海天瑞声与百度数据众包越众而出,据了解,国内整体供应方中,以提供图像类数据采标服务的公司居多,内容涉及人像数据、OCR数据、自动驾驶数据等,业务需求较为分散,其中以百度数据众包营收份额占比最大。
相比而言,语音类数据需求较为集中,且供应门槛高于图像类数据,内容包含语音识别数据、语音合成数据等,其中以海天瑞声营收份额占比最大。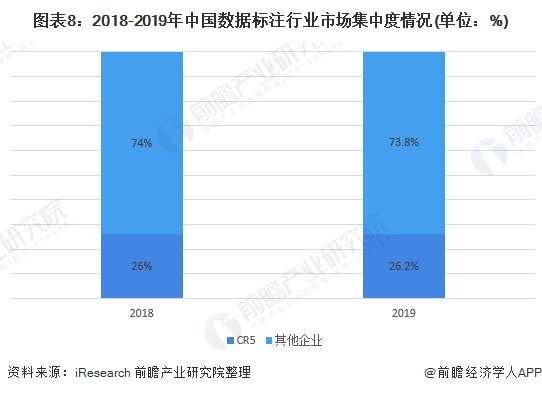
文章插图
目前人工智能数据标注行业集中度较为适中,既非寡占型市场也非充分竞争市场,这一方面是由于百度数据众包、海天瑞声、数据堂等企业进入市场较早,积累了较多客户资源,另一方面则是由于下游企业之前多采用公开数据集训练模型,对数据的高精度要求由来尚短,受生态传导效应滞后影响,市场门槛还不显著,资金与研发实力较为薄弱的中小企业还有较强的发展土壤。
- 华为鸿蒙系统|都2021年底了,为何Mate40Pro还是目前公认最好用的“安卓”手机
- 杜比|2021年度排名TOP5的网络机顶盒,买哪个最靠谱?
- 摄像头|李彦宏《智能交通》与百度Apollo,还是小瞧它的胃口了!
- 荣耀|建议收藏!2021年底盘点:这三款旗舰可以让你安逸地使用两三年
- 电池|2021年年底买千元机,这四款用三五年没问题,十二月购机必看
- 裁员|2021互联网公司裁员汇总:裁员的时候,没有一片雪花是无辜的
- realme|盘点2021年最受好评的四款智能手表,双十二这样买不会出错
- 出行服务|百度Apollo自动驾驶出行服务平台“萝卜快跑”将落地重庆永川
- OPPO|2021骁龙技术峰会上OPPO高管爆猛料 Find X系列新品明年一季度见
- 国企网|迈竞科技荣获百度电商店铺分销商资质,助力企业打开电商营销新局面