编辑导语:LTV,即用户生命周期总价值,是运营人员在业务过程中常接触的指标,通过对LTV的预估,运营人员可以为后续决策做好准备。本篇文章里,作者便针对LTV预估、留存函数拟合等问题进行了解读,一起来看一下。
文章插图
一、从LTV预估开始说起LTV的预估,是许多业务UE模型和增长模型的起点:
其中,用户生命周期又可以用累加的留存率来计算:
不过,这里面使用的留存率却未必是实际发生的历史数据。
因为我们做决策时往往等不了那么长的时间,所以我们一般使用的是根据前面一小段时间的数据拟合出来的留存函数R(t)。
那留存函数应该怎样拟合呢?
二、留存函数拟合许多文章或资料会推荐这么一个方法:
- 把过去的次日、3日、7日、14日、30日等留存率记录在Excel中,画出来一个散点图;
- 然后点击图上的数据点,右键选择“添加趋势线”,这时右方就会出现可以拟合的曲线类型(指数、线性、对数、多项式、乘幂、移动平均);
- 打开显示公式和R平方项,在这些曲线类型和公式中,选择R方最接近1的那个(一般是指数或乘幂),即为最终拟合得到的留存函数R(t)。
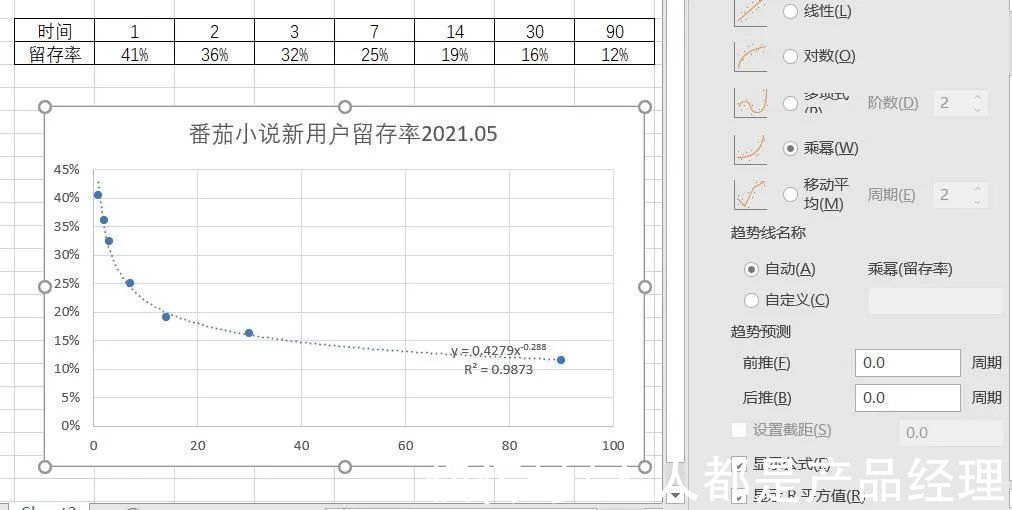
文章插图
番茄小说2021.05新用户留存率,QuestMobile
选择R方最接近1,意味着找到了拟合程度最高的函数作为留存函数R(t),接下来就可以回到LTV预估的主线去了。
不过这里有个小问题,却似乎鲜有人讨论过:为什么是指数或乘幂这两个函数?如果拟合的结果是这两个函数中的一个,意味着什么?它俩最核心的差异和联系在哪?
三、两个函数的差异这两个函数有什么差异呢?如果光从函数本身看,指数函数和幂函数的核心差异在于衰减的速度。指数函数的表达式为:
幂函数的表达式为:
根据表达式我们可以推导出,如果以3天为一个周期,对于指数函数来说,留存率每三天会以同样的速度衰减:
而对于幂函数来说,留存率衰减的速度会逐渐放缓,下一个同比例衰减周期会拉长到6天,即上一个周期的两倍:
我们总是希望留存率的衰减能够慢一些,所以相比之下,拟合成幂函数是更希望看到的结果。
四、艾宾浩斯遗忘曲线那这两个函数有什么联系呢?1885年,德国心理学家艾宾浩斯(H.Ebbinghaus)首次对人类的记忆进行了定量研究,他用无意义的音节作为记忆的材料,通过记录一段时间后被试人员对这些音节材料的记忆留存率,绘制出了这样一个曲线:
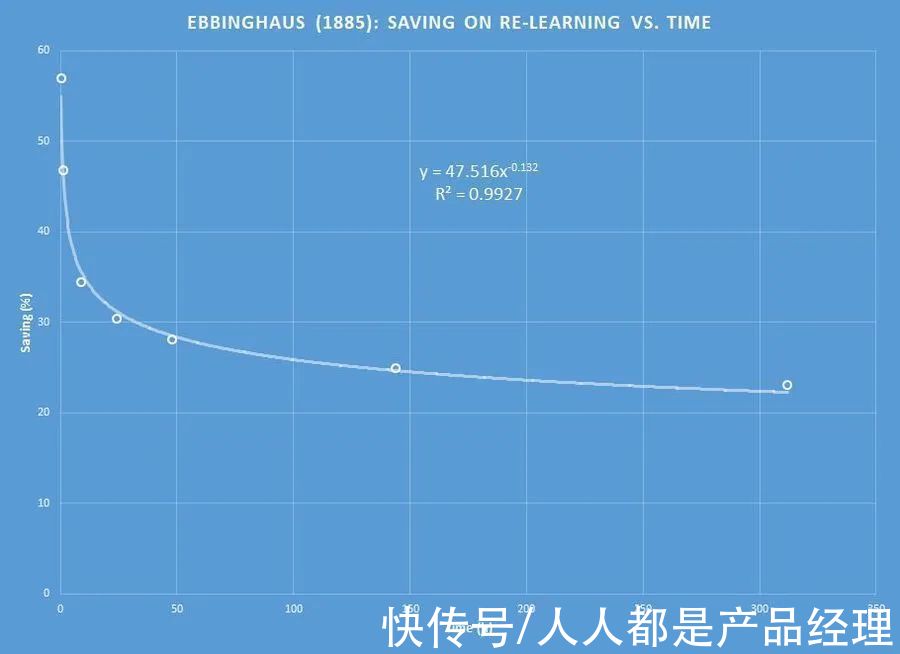
文章插图
这个曲线也被称为艾宾浩斯遗忘曲线(或记忆曲线),可以看到通过对这个曲线进行拟合,得到的拟合度最高的是一个幂函数。
不过后续人们的研究表明,单一的遗忘曲线实际上应该是更接近指数函数的,结合前面提到的指数函数的性质,说明人类会以一个固定的周期等概率地遗忘大脑中的信息,是一个很符合大自然规律的现象。
而艾宾浩斯之所以拟合得到了幂函数,是由于最初的记忆实验,混杂了不同难度的记忆材料,这种混杂改变了遗忘曲线的指数性质。
下面的这个例子,可以解释这一现象:
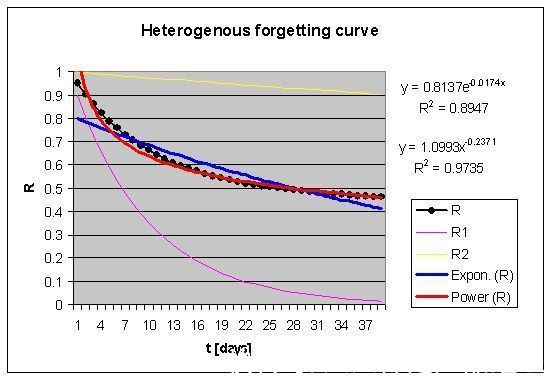
文章插图
图中黄色和紫色曲线,分别代表两种难度记忆材料的遗忘曲线,它们都是指数函数y=e^(-kt),其中k的大小不同,代表难度不同;
而黑色的散点,则为两个函数的平均值(或可泛化为线性组合),通过对这些散点进行拟合,会发现一个有趣的事实:
某些情况下,对两个指数函数线性组合后的曲线,拟合度更高的(即R方更大的),却不再是指数函数了,而是幂函数!
这个有意思的现象,各位有兴趣的话,可以自行验证一下。
五、遗忘曲线与留存曲线关于遗忘曲线的结论,对我们理解留存曲线有什么帮助吗?
事实上我们早就发现,这两个曲线惊人地一致。
如果把拉新激活的动作视为最初始的记忆训练,那么在后续的时间里,如果没有再次激活,用户就会以一定的概率,自然而然地遗忘我们的App,表现就和遗忘曲线是一样的。
为了让用户回到我们的App,提升用户留存率,我们通过各种push召回它们,这也和关于记忆的研究中,定期复习的方法如出一辙。
同时,和混杂材料带来的遗忘曲线类似,绝大多数功能丰富的成熟应用,留存曲线都应该是衰减程度更慢的幂函数。
- 刷单|预估销量30万,“双11”后零订单?
- 函数|Bengio 终于换演讲题目了!生成式主动学习如何让科学实验从寻找“一个分子”变为寻找“一类分子”?
- Windows|为什么设计一个单独的GetSystemDirectory函数?
- 芯片|中电信启动服务器集采:规模预估20万台 国产芯片占比超25%
- atom|说说RegisterClass这个函数返回值的作用
- 3g|这6个多条件函数都不掌握,还敢称Excel达人?
- 一加科技|为什么设计一个单独的GetSystemDirectory函数?
- excel|这10个Excel函数公式,职场必备,办公不求人
- 渠道|产品经理怎么分析用户生命周期价值(LTV)
- 课程|得到APP上线元宇宙课程,预估收入已达百万