
文章图片

文章图片

文章图片
文章图片
今天我们介绍了如何使用pipeline在 Apache Beam 中的文件中读取、写入数据 , 其中“Employees.csv”文件被读取/过滤/写入新文件 。
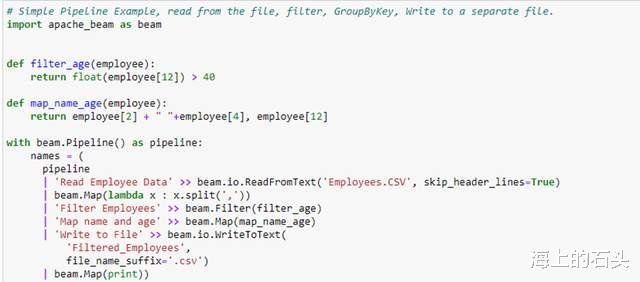
介绍【apache|Apache Beam 处理文件】本文通过适当的pipeline示例解释了如何在Apache Beam中读取和写入文件中的数据 。 从文件中读取数据是通过“ReadFromText”转换完成的 , 写入新文件是通过“WriteToText”转换完成的 。 开始我们解释了如何从文件中读取数据以及如何写入文件 , 在、后半部通过创建一个pipeline , 其中读取“Employees.csv”文件 , 根据年龄过滤 , 提取员工的名字 , 姓氏和年龄pipeline入新文件 。 总体而言 , pipeline如下所示:
从文件中读取在本文中 , 我们使用来自数据源的文件 , 我们下载了一个 100 条记录文件并将其命名为“Employees.csv” , 通过“ReadFromText”将从磁盘读取文件 。 下面的代码展示了相同的内容:
输出
写入文件“WriteToText”转换用于将数据写入文件 , 下面的程序从文件中读取数据并写入“out.csv”文件 。
输出
pipelinepipeline代码包含两个函数 , 一个用于过滤员工年龄大于 40 的行 , 第二个用于仅映射员工的名字、姓氏和年龄 。
在这两个函数中 , 我们都基于索引访问记录 。 完整的流程代码如下:
生成文件的内容
概括在文章中 , 我们探讨了如何从文件中读取、写入数据 , 我们还解释了执行过滤、映射数据并将其写入新文件的完整pipeline代码 。
- apache|OPPO新机将于3月发布:天玑8100+150W快充,性价比给力!
- 喜马拉雅|喜马拉雅 Apache RocketMQ 消息治理实践
- 反差萌|推力反差萌?!专推大耳的小尾巴Audirect Beam 3Pro
- 侯震宇|百度:Apache Doris 1.0版本发布在即 致力打造全球顶级开源数据仓库
- 耳机|500块搞定难推耳机:真平衡小尾巴BEAM 3S评测
- 再曝3个高危漏洞!Apache Log4j 漏洞1个月回顾:警惕关键信息基础设施安全
- apache|tomcat 与 nginx,apache的区别是什么?
- luniy无人愿意开发,Hadoop 管理工具 Apache Ambari 顶级项目即将退役
- apache|性能不强配色来凑,微软推出哑黑版Surface Go 3
- 小米科技|Apache Flink不止于计算,数仓架构或兴起新一轮变革