
文章图片
文章图片

文章图片

大数据文摘出品
作者:蔡芳芳
采访嘉宾:王峰(莫问)
2021 年初 , 在 InfoQ 编辑部策划的全年技术趋势展望中 , 我们提到大数据领域将加速拥抱“融合”(或“一体化”)演进的新方向 。 本质是为了降低大数据分析的技术复杂度和成本 , 同时满足对性能和易用性的更高要求 。 如今 , 我们看到流行的流处理引擎 Apache Flink(下称 Flink)沿着这个趋势又迈出了新的一步 。
维基百科的“Apache Flink”词条下 , 有这么一句描述:“Flink 并不提供自己的数据存储系统 , 但为 Amazon Kinesis、Apache Kafka、Alluxio、HDFS、Apache Cassandra 和 Elasticsearch 等系统提供了数据源和接收器” , 很快 , 这句话的前半句或许将不再适用 。
1 月 8 日上午 , Flink Forward Asia 2021 以线上会议的形式拉开帷幕 。 今年是 Flink Forward Asia(下文简称 FFA)落地中国的第四个年头 , 也是 Flink 成为 Apache 软件基金会顶级项目的第七年 。 伴随着实时化浪潮的发展和深化 , Flink 已逐步演进为流处理的领军角色和事实标准 。
回顾其演进历程 , Flink 一方面持续优化其流计算核心能力 , 不断提高整个行业的流计算处理标准 , 另一方面沿着流批一体的思路逐步推进架构改造和应用场景落地 。 但在这些之外 , Flink 长期发展还需要一个新的突破口 。
在 Flink Forward Asia 2021 的主题演讲中 , Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(花名莫问)重点介绍了 Flink 在流批一体架构演进和落地方面的最新进展 , 并提出了 Flink 下一步的发展方向——流式数仓(Streaming Warehouse , 简称 Streamhouse) 。 正如主题演讲标题“Flink Next Beyond Stream Processing”所言 , Flink 要从 Stream Processing 走向 Streaming Warehouse 去覆盖更大的场景 , 帮助开发者解决更多问题 。 而要实现流式数仓的目标 , 就意味着 Flink 社区要拓展适合流批一体的数据存储 , 这是 Flink 今年在技术方面的一个创新 , 社区相关工作已经在 10 月份启动 , 接下来这会作为 Flink 社区未来一年的一个重点方向来推进 。
那么 , 如何理解流式数仓?它想解决现有数据架构的哪些问题?为什么 Flink 要选择这个方向?流式数仓的实现路径会是怎样的?带着这些问题 , InfoQ 独家专访了莫问 , 进一步了解流式数仓背后的思考路径 。
Flink 这几年一直在反复强调流批一体 , 即:使用同一套 API、同一套开发范式来实现大数据的流计算和批计算 , 进而保证处理过程与结果的一致性 。 莫问表示 , 流批一体更多是一种技术理念和能力 , 它本身不解决用户的任何问题 , 只有当它真正落到实际业务场景中 , 才能够体现出开发效率和运行效率上的价值 。 而流式数仓可以理解为流批一体大方向下对落地解决方案的思考 。
流批一体的两个应用场景
在去年的 FFA 上 , 我们已经看到 Flink 流批一体在天猫双十一的落地应用 , 那是阿里首次在核心数据业务上真正规模化落地流批一体 。 如今一年过去了 , Flink 流批一体在技术架构演进和落地应用两方面都有了新进展 。 技术演进层面 , Flink 流批一体 API 和架构改造已经完成 , 在原先的流批一体 SQL 基础上 , 进一步整合了 DataStream 和 DataSet 两套 API , 实现了完整的 Java 语义层面的流批一体 API , 架构上做到了一套代码可同时承接流存储与批存储 。
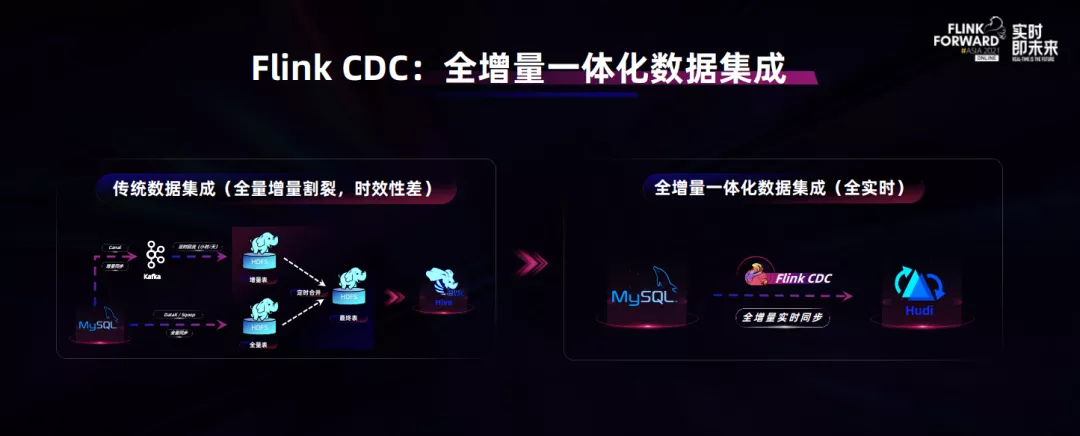
在今年 10 月发布的Flink 1.14版本中 , 已经可以支持在同一个应用中混合使用有界流和无界流:Flink 现在支持对部分运行、部分结束的应用(部分算子已处理到有界输入数据流的末端)做 Checkpoint 。 此外 , Flink 在处理到有界数据流末端时会触发最终 Checkpoint , 以确保所有计算结果顺利提交到 Sink 。 而批执行模式现在支持在同一应用中混合使用 DataStream API 和 SQL/Table API(此前仅支持单独使用 DataStream API 或 SQL/Table API) 。 此外 , Flink 更新了统一的 Source 和 Sink API , 开始围绕统一的 API 整合连接器生态 。 新增的混合 Source 可在多个存储系统间过渡 , 实现诸如先从 Amazon S3 中读取旧的数据再无缝切换到 Apache Kafka 这样的操作 。 在落地应用层面 , 也出现了两个比较重要的应用场景 。 第一个是基于 Flink CDC 的全增量一体化数据集成 。
- 小米科技|小米MIX5一马当前,微挖孔回归,200W快充是重点
- 小米科技|家电升级计划:幸福感+N,盘点近期入手的家电好物
- 快科技|云鲸用创新技术强势出圈,市场发展潜力巨大
- 机箱|小米4nm新机上线,12+256G大存储四千出头,还是雷军靠谱
- 飞利浦·斯塔克|「手慢无」高刷2.5K屏 小米平板5Pro促销送快充
- 小米科技|小米12系列或有mini版本,看齐iPhone SE,定位2K价位段
- 红米手机|1999元起!Redmi K50全系售价曝光,干翻小米12
- 一加科技|一加OxygenOS 13官宣:将与OPPO ColorOS合并
- 小米科技|网上买的流量卡都是骗人的,用不到两个月,商家就跑路了
- 中国科学网|圆心科技贡献保险智慧与力量,驱动普惠健康险实现强保障、优服务