① 基于对象的场景分类
这种分类方法以对象为识别单位,根据场景中出现的特定对象来区分不同的场景;基于视觉的场景分类方法大部分都是以对象为单位的,也就是说,通过识别一些有代表性的对象来确定自然界的位置。
典型的基于对象的场景分类方法有以下的中间步骤:特征提取、重组和对象识别。
缺点:底层的错误会随着处理的深入而被放大。例如,上位层中小对象的识别往往会受到下属层相机传感器的原始噪声或者光照变化条件的影响。尤其是在宽敞的环境下,目标往往会非常分散,这种方法的应用也受到了限制。
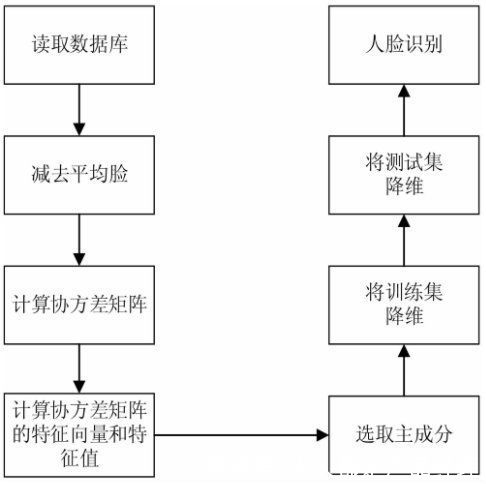
需要指出的是,该方法需要选择特定环境中的一些固定对象,一般使用深度网络提取对象特征,并进行分类。例如PCA算法实现识别人脸降维原理,排除冗余和噪音的干扰,试验步骤如下:
文章插图
② 基于区域的场景分类
首先通过目标候选候选区域选择算法,生成一系列候选目标区域,然后通过深度神经网络提取候选目标区域特征,并用这些特征进行分类。
例如K-means算法,它把N个对象根据属性分为K个类别,使得结果满足:同一类中的对象相似度较高,不同的对象相似度较小,定义损失函数如下:
其中Xn为待分类的数据点,μk为第k个类别的中心,Rnk∈{0,1}来表示数据点Xn对于k的归属(其中n=1,。。。,N;k=1,。。。,k)
如果数据点Xn属于第k类,则Rnm=1,否则为0。
K-means通过迭代求解,得到使得损失函数J最小的所有数据点的归属值{Rnk}和聚类中心{μk}。
③ 基于上下文的场景分类
这类方法不同于前面两种算法,而将场景图像看作全局对象而非图像中的某一对象或细节,这样可以降低局部噪声对场景分类的影响。将输入图片作为一个特征,并提取可以概括图像统计或语义的低维特征。
该类方法的目的即为提高场景分类的鲁棒性。因为自然图片中很容易掺杂一些随机噪声,这类噪声会对局部处理造成灾难性的影响,而对于全局图像却可以通过平均数来降低这种影响。
基于上下文的方法,通过识别全局对象,而非场景中的小对象集合或者准确的区域边界,因此不需要处理小的孤立区域的噪声和低级图片的变化,其解决了分割和目标识别分类方法遇到的问题。
四、图像识别过程图像识别技术归纳起来,主要包括4个步骤:
1)首先是获取信息,主要是指将各类信息通过传感器向电信号转换,也就是对识别对象的基本信息进行获取,并通过“聚类”的方式,将其向计算机可识别的信息转换。
2)然后是信息预处理,主要是指采用去噪、变换及平滑等操作对图像进行处理,基于此使图像的重要特点提高。
3)其次是抽取及选择特征,主要是指在模式识别中,抽取及选择图像特征,概括而言就是识别图像具有种类多样的特点,如采用一定方式分离,就要识别图像的特征,获取特征也被称为特征抽取。
【 擎天柱|业务进阶:AI图像识别】4)最后是设计分类器及分类决策,其中设计分类器就是根据训练对识别规则进行制定,基于此识别规则能够得到特征的主要种类,进而使图像识别的不断提高辨识率,此后再通过识别特殊特征,最终实现对图像的评价和确认。
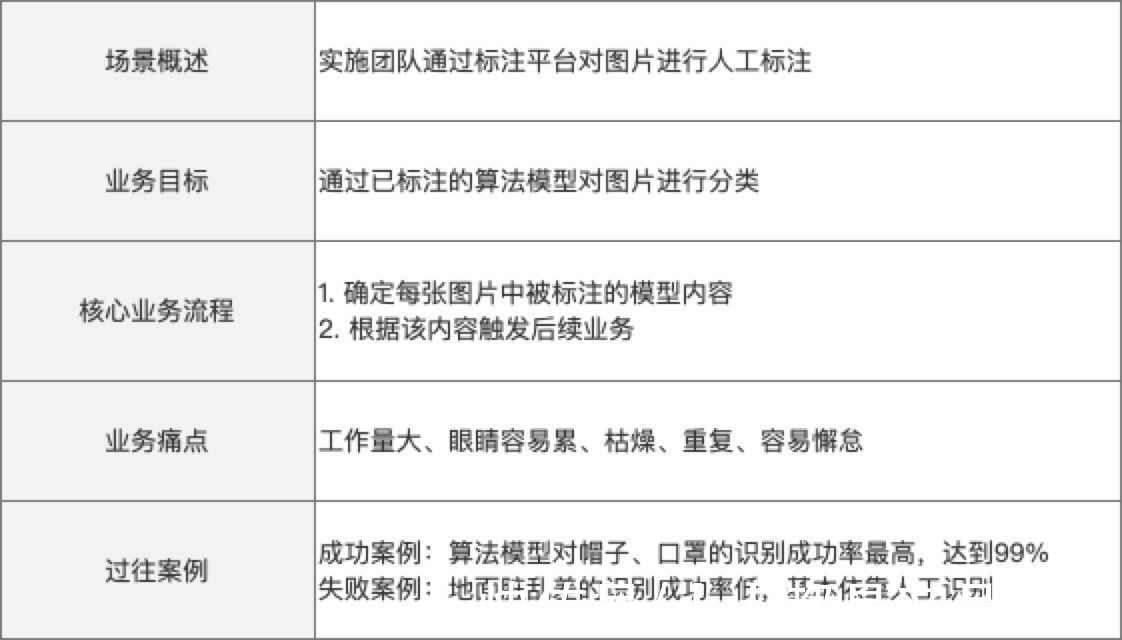
五、工作应用作为PM\PO\TPM来说,给到技术大佬们的策略是要清晰完整的,举例:要识别图片中的人是否带帽子,那么这时我们就要描述清楚帽子的颜色、种类和所在位置等维度信息。
最好用爬虫的方式爬取大量帽子,然后判断帽子是否在人的脑袋上。在语音识别中,需要建立字符库,完善优化字符库的内容。
文章插图
通过收集和整理,我们对要产品需求会有一个直观的认知,但随着调研的继续,我们还可能会发现其他问题。为了避免有价值的信息遗漏,这个阶段我们收集的案例,应该具有更多的发散性。
六、用户感知提升对于用户来说,能够让用户感知到的是产品的拟人度。但AI的输出是否合理,这个取决于人的主观评判。这也是数据标注工作所做的意义所在——尽可能通过标注让模型更像真实的人。比如在情景对话中,虽然有些回答听起来很搞笑,但只要输出的结果让人觉得合理,就依然会被人接受。
- 老巫婆:你说这个世界上最美丽的人是谁?
- AI:是白雪公主!
- gmv|美欧同意禁止俄罗斯使用SWIFT系统;滴滴称不会关闭俄罗斯业务;微信微博抖音处理涉俄乌局势不当言论丨邦早报
- 进阶|?红米系列手机,质量还是相当可靠,操作系统也很好用
- Python|华为:将与俄罗斯共度难关,滴滴:停止在俄罗斯的业务
- 小红书|狐讯|百度回应多条业务线裁员 ;《艾尔登法环》正式开售
- 手机业务|李斌要在雷军地盘上“踩一脚”
- yy|百度多个业务线人员精简,涉及核心技术部门
- 车源|透过汽车之家二手车业务,看二手车市场的模式终局
- 百度多个业务线人员精简,涉及核心技术部门|36氪独家 | 业务线
- 汽车融资租赁|汽车融资租赁(一)市场、用户及业务流程
- x5|进阶LTPO2.0!Find X5 Pro实现省电与流畅兼得