文章图片

前言 KubeDL 是阿里开源的基于 Kubernetes 的 AI 工作负载管理框架 , 取自\"Kubernetes-Deep-Learning\"的缩写 , 希望能够依托阿里巴巴的场景 , 将大规模机器学习作业调度与管理的经验反哺社区 。 目前 KubeDL 已经进入 CNCF Sandbox 项目孵化 , 我们会不断探索云原生 AI 场景中的最佳实践 , 助力算法科学家们简单高效地实现创新落地 。
KubeDL 为分布式训练作业带来了 HostNetwork 网络模式 , 支持计算节点之间通过宿主机网络相互通信以提升网络性能 , 同时适应 RDMA/SCC 等新型高性能数据中心架构的网络环境 , 此外 , KubeDL 针对 HostNetwork 模式带来的 FailOver 后新端口互相感知等问题也带来了新的解决思路 。
Github 地址:https://github.com/kubedl-io/kubedl
网站:https://kubedl.io/model/intro/
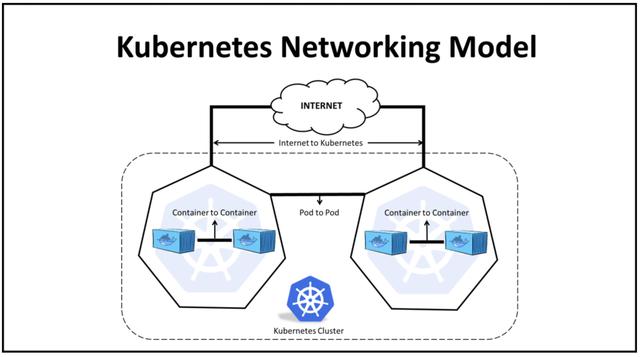
Overlay 不是银弹 Kubernetes 原生的容器网络模型定义了一系列不依赖 NAT 的\"Pod-Pod\"间通信规约 , 基于 VxLAN 组建的 Overlay 网络很好地实现了这一模型(如经典的 Flannel)并解决了诸多大规模容器编排系统中的网络管理的痛点:
Pod 的无感迁移:Overlay 网络是基于物理网络构建的虚拟二层网络 , Pod IP 并不与任何节点绑定 , 当节点宕机或发生其他硬件异常时 , 对应的服务 Pod 可以通过相同的 IP 在其他节点上重新启动 , 只要底层的物理网络连通不中断就不影响服务的可用性 。 在大规模的分布式机器学习训练中 。 KubeDL 也是基于“Pod 可能漂移 , 但 Service 是固定的”这一前提实现的计算节点故障转移(FailOver); 网络节点的规模:经典的 NAT 地址解析通常通过 ARP 广播协议来自动学习邻接节点 IP 与 MAC 地址的映射 , 但当节点规模庞大时 , 一次广播很容易造成 ARP 风暴并引起网络拥塞 , 而基于隧道穿越的 Overlay 网络只需知道少数的 VTEP 节点的 MAC 地址即能实现数据包的转发 , 极大的降低了网络的压力; 租户网络隔离:Kubernetes 强大的网络插件扩展性配合 VxLAN 的协议设计 , 很容易实现虚拟网络的再划分从而实现租户之间的网络隔离; 【spec|KubeDL HostNetwork:加速分布式训练通信效率】这些都是虚拟容器网络带来的好处 , 但虚拟化的代价是网络性能的损耗:Pod 与主机网络通过一对 Veth 虚拟网桥设备连接来实现网络 namespace 的互相隔离 , 每一次\"Pod-Pod\"间通信的数据包都需要经过”封包-路由-以太网-路由-拆包“等流程才能到达对端的 Pod , 拖慢网络性能的同时还会增加宿主机内核网络栈的处理压力从而提升负载 。
随着多模态模型训练、大规模稠密参数模型训练等分布式训练模式的兴起 , 以及数据集规模、特征参数的爆炸 , 网络通信已然成为分布式训练效率的一个“水桶短板” 。 最直接的优化网络性能的方法即使用主机网络(HostNetwork)通信 , 免去容器网络虚拟化的开销 。 同时随着 RDMA(RoCE) , Nvidia GPU Direct 等技术的成熟 , 这些新型的高性能网络技术逐渐被应用于大规模的商业生产环境来大幅提升模型训练的效率 , 通过旁路内核网络栈的开销和零拷贝直读数据等技术充分利用网络带宽 , Efficiency Is Money!这些原生的高性能网络通信库原语(如 RDMA_CM)也同样依赖主机网络实现 , 无法直接基于 Pod 虚拟网络通信 。
KubeDL 在支持分布式训练基于标准容器网络通信的基础上扩展了主机网络的通信模型 , 同时解决了端口冲突和 FailOver 后新端口互相感知等分布式训练中的常见问题 , 实现高性能网络的轻松使能 。
使能 Host 高性能网络 标准容器网络拓扑
在标准的容器网络通信模型中 , Master/Worker/PS 等不同 Workload 角色之间通过 Headless Service 实现服务发现 , Pod 之间通过恒定的域名相互通信 , 由 CoreDNS 实现域名到 Pod IP 的解析 , 由于 Pod 是可以漂移的但 Service 及其附属的域名是恒定的 , 即使部分 Pod 运行时异常了也能很好地实现 FailOver , 在异常 Pod 重新拉起之后与其他 Pod 重连接 。
apiVersion: training.kubedl.io/v1alpha1kind: \"TFJob\"metadata: name: \"mnist\" namespace: kubedlspec: cleanPodPolicy: None tfReplicaSpecs: PS: replicas: 2 restartPolicy: Never template: spec: containers: - name: tensorflow image: kubedl/tf-mnist-with-summaries:1.0 command: - \"python\" - \"/var/tf_mnist/mnist_with_summaries.py\" - \"--log_dir=/train/logs\" - \"--learning_rate=0.01\" - \"--batch_size=150\" volumeMounts: - mountPath: \"/train\" name: \"training\" resources: limits: cpu: 2048m memory: 2Gi requests: cpu: 1024m memory: 1Gi volumes: - name: \"training\" hostPath: path: /tmp/data type: DirectoryOrCreate Worker: replicas: 3 restartPolicy: ExitCode template: spec: containers: - name: tensorflow image: kubedl/tf-mnist-with-summaries:1.0 command: - \"python\" - \"/var/tf_mnist/mnist_with_summaries.py\" - \"--log_dir=/train/logs\" - \"--learning_rate=0.01\" - \"--batch_size=150\" volumeMounts: - mountPath: \"/train\" name: \"training\" resources: limits: cpu: 2048m memory: 2Gi requests: cpu: 1024m memory: 1Gi volumes: - name: \"training\" hostPath: path: /tmp/data type: DirectoryOrCreate 以一个经典 PS-Worker 架构的 Tensorflow 分布式训练作业为例 , Worker 负责计算参数的梯度 , 由 PS 负责聚合、更新并广播参数 , 因此每个 PS 都可能和所有 Worker 建立连接并通信 , 反之亦是 。
- 默多克|IEEE Spectrum调查:AI 的 6 种最坏情况
- 惠普|惠普Spectre x360 14测评:搭载3: 2长宽比屏幕
- 惠普|轻薄本进化有点快 这款惠普 Spectre x360值得入
- 浪潮企业级解决方案|4679分!全球第一!浪潮云海虚拟化InCloud Sphere 破SPECvirt世界纪录!
- 安晟培半导体宣布收购AI技术初创公司OnSpecta
- 全球财经网|银河麒麟V10+ZStack+鲲鹏拿下SPEC Cloud测试全球最高分!
- 惠普|惠普Spectre x360评测:最好的2合1电脑,完美无缺
- RGB灯效:威刚发布XPG Spectrix S20G系列M.2 2280固态硬盘
- 中科创达、施耐德电气联合发布基于AWS的融合智能工业视觉平台TurboX Inspection
- 解决|中科创达推TurboX Inspection平台:为智慧工业领域降本增效,解决行业智能化问题