标准化|云天励飞王孝宇:AI 研发和应用,数据的重要性远高于模型( 三 )
标注之后怎么办?这是学术界和工业界很火的大模型和无监督学习。
为什么我们在这里面放了大模型和无监督学习?刚才我们讲到,一开始我们想做井盖被人拿走的事实检测,我们一开始可能没有这么多标注好的数据,可能只有100个,但数据标注的效率可能是万分之一。
如果你想标1万个这样的数据,需要标1亿个data,这个量非常大。怎么办?
先标100个,为什么要用大模型和无监督学习配合这个数据去跑模型?就是为了让你初始模型的精度达到最高。
无监督和大模型最好的方式,本来100个数据训练出来的精度只有30%,用大模型和无监督学习的方法训练之后,精度可以达到80%,那挖掘数据的效率可以提高10倍,也就是说我少标了10倍的数据,一切都是为了后面数据迭代的效率来做的。
为什么大模型和无监督学习可以提高这个性能?虽然它自己没有标注数据,但它是被千亿、百亿级的数据训练出来的,知道井盖是什么样的,这种特征的编辑其实已经实现了,再配合少量数据的标注,就可以得到一个还不错的初始模型。
为什么要得到还不错的初始模型?因为数据迭代的效率会更高,首先是为了第一步方便。
第二步,我们不说模型迭代,而是数据迭代,因为我们认为模型的训练已经被标准化了,在平台上,点个按钮它就训练好了,不需要有模型训练的知识,我们专家的系统已经把它做好了。
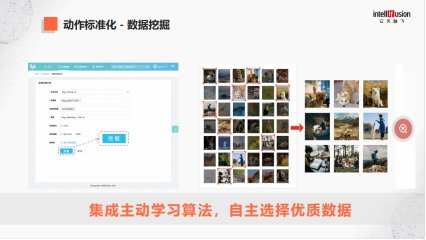
所谓的数据迭代,就是在海量还没有标注好的数据中,找到能够提高模型性能的数据,进行主动学习。
传统模型研发的范式是缺数据再去标,但发现标过来的数据跟以前的分布是一样的,对模型的分布没有太大用处。所以需要用技术、算法找到对自己真正有用的数据,右边我们从海量数据中找出了9张有用的数据。
模型挖掘怎么做?在左边平台界面,点一个按钮,选一个数据集,可以自动在这里面挖掘,从几亿的数据里找到几张跟井盖相关的数据做训练,我们是用主动学习算法做数据择优的。
文章插图
数据迭代之后,要做模型训练,在这个平台上用一键化的方式去做,这就是我们花几百万招过来的博士应该干的事情,他们不应该天天调参数、挖数据,这些事情应该让平台去干。
这一步,只要你点训练,它可以自动训练,背后怎么训练?是由开发者去开发的。但是在整个平台上去进行操作的人,不需要知道大规模模型训练,这降低了训练模型人员的从业要求,只要他知道这是怎么回事,把数据拿进去就可以训练,无代码一键完成模型开发。
做这种平台研发环境的好处是什么?数据沉淀在平台上,动作可复用,流程可追溯。这里面有几个界面:数据集管理、模型管理、任务管理。
数据集管理,就是一些标注好的数据集,以及挖掘、生成的数据集;模型管理,就是训练好的模型;任务管理,可以是标注任务,也可以是挖掘任务,也可以是训练任务,所有研发的轨迹全部停留在这里面。
为什么要做这个事?很简单,因为人力成本太高,企业无法招聘太多人从事每一个算法的研发。有了这套平台之后,我们可以实现非算法人员开发模型的方式,让算法工程师做更高级别的技术,这些平台话、流程化的事情,可交给一般的技术人员或者学生来做。
整个过程中,我们认为沉淀更多的是数据价值,这比模型的价值更大。
为什么数据的价值比模型的价值更大?
数据没有了,模型是训练不出来的,你不会再得到提高,即使得不到模型,数据在这儿,所以很容易再训练一个模型出来。
数据的重要性远远高于模型的重要性,所谓持续性的研发,沉淀出来的是有价值的数据,而不是其他。
因为模型很容易重新训练,或者用不同的数据迭代。但数据日积月累需要很长的时间。在整个平台上,通过数据不停的挖掘、训练、标注、迭代,会一轮一轮增加新的数据,为每个任务沉淀出非常优质的数据集。
也就是说,在这个平台上,数据变成了最重要的资产。
另外,所有的开发技巧也沉淀到平台上了。
如果大家搞研发管理,就会发现一个现象:部分人能做得特别好,部分人怎么都做不好。这是因为,任务、指令都是一样的,但不同的人研发经验是不一样的。
人才的素质属于不可控因素,如果把这套技术能力进行沉淀,每个模型研发过程都能实现可追踪,这样就能让做不好的人,通过学习,把事做好。
- 标准化|生鲜电商:最近处处惹人爱的生鲜电商是什么?
- 标准化|美菜断臂求生:餐饮食材B2B"冷思考"时刻
- 卡车司机|福佑卡车创始人单丹丹:产业互联网效率制胜,公路货运“标准化”演进|WISE2021新经济之王大会
- 机器人|INDEMIND: 打造标准化机器人AI方案,行业关键技术供应商价值凸显
- 人工智能|云天励飞副总裁郑文先确认出席| 第四届中国人工智能安防峰会
- 半导体|融资丨「厦门云天半导体」完成数亿元B轮融资,德联资本联合投资