面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测( 三 )
3.1 精密掩模提取为了使图片更具有真实感 , 重要的是生成的图像没有任何不切实际的边或伪影 。 因此 , 准确掌握产品的掩模信息是至关重要的 。 然而 , 自动提取精确掩模并不是一项简单的任务 。 传统的方法 , 例如使用固定颜色的背景(在大多数情况下是绿色的)无法获得精确的掩模提取 。 特别是 , 当我们试图提取其掩模的产品与背景颜色相同时 , 这种方法会失败 。 我们提出了一种比传统方法更健壮、更易于自动化的掩模提取方法 。
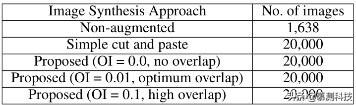
表 1 训练数据集(OI 是重叠指数)
 文章插图
文章插图
通过在多种背景色下捕捉产品图像 , 使掩模生成方法对背景色具有鲁棒性 。 为了实现这一点 , 我们建立了一个以液晶屏为放置平台的图像采集装置(图 3(b)) , 它的颜色可以改变 。 为了生成精确的掩模 , 我们将单个产品放在液晶屏上 , 并在多种背景色下捕捉 。 一旦我们有了一组具有多个背景色的产品的图像集(图 4) , 我们将获得所有背景色的像素级标准差 , 并生成一个标准偏差图像(
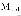 文章插图
文章插图
) , 其中 , N 是不同背景下捕获的图像数量 ,
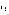 文章插图
文章插图
, p 是图像 i 中像素 p 处的图像强度 ,
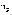 文章插图
文章插图
和
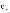 文章插图
文章插图
分别是给定产品不同颜色背景的图像在像素 p 处像素值的平均值和标准偏差 。
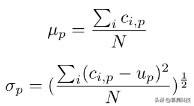 文章插图
文章插图
生成的标准偏差图像中的前景像素应该具有较低的值 , 因为改变背景颜色不会影响前景的像素值 。 因此 , 在标准偏差图像上进行阈值运算后得到的二值图像就是产品的精确掩模 , 通过合并生成逼真的训练图像需要一个精确的乘积掩模 , 这将在下一节中解释 。
3.2 合并单个产品一种简单的合并单个产品的方法是将选定的产品随机粘贴到给定的背景上 。 然而 , 在这种方法中 , 我们无法控制产品在结果图像中的排列 。 我们希望合成训练图像 , 这些图像代表了 POS 系统的自然使用所产生的产品放置 , 即以拥挤的方式放置多个产品 。 我们通过控制重叠指数来实现对结果图像的融合和接近程度的可控性 。 重叠索引是两个单独产品之间允许的最大重叠量 , 计算产品掩码之间的 IoU(intersection over union) 。 较大的重叠索引意味着生成的图像在产品之间会有更多的重叠 。 使用重叠索引合成这些图像的确切过程总结如下 。
在合成训练图像之前 , 我们首先确定重叠指数 。 接下来 , 我们从可用的培训产品库中随机抽取多个产品 。 从抽样的产品中 , 我们随机选择一个产品粘贴到一个空图像上 , 我们称之为基础图像 。 最后 , 我们使用其遮罩信息在基础图像中添加每个后续产品 。 我们在图 5 的基础上增加了一个新的重叠值 。
重叠索引对生成的图像有显著的影响 。 当我们增加重叠索引时 , 得到的图像包含许多被遮挡的实例 。 这种积极的咬合对我们的特殊情况可能不太理想 。 另一方面 , 当我们将重叠索引限制为零时 , 会导致图像没有重叠 。 然而 , 使用小重叠指数合成的图像(图 6)代表了 POS 系统自然使用中遇到的图像 , 因此将是训练目标检测器的最佳选择 。
4 实验和结果4.1 消融研究方法为了证明我们提出的真实感图像合成方法在训练生成中的有效性图像 。 我们通过与其他训练图像合成方法 , 特别是非扩增方法和简单剪切粘贴方法进行烧蚀实验 。 在非扩增方法中 , 训练数据集是通过人工捕捉不同方位下单个产品的图像来生成的 。 使用这种方法得到的训练图像具有真实感 , 但缺乏拥塞 , 如图 7(a)所示 。 在简单的剪切粘贴方法中 , 产品沿着边界框从相应的单个图像中裁剪出来 , 然后通过保持公平的近距离进行合并 。 这种方法会导致拥塞的情况 , 但由于引入了不真实的边缘 , 因此缺乏真实感 , 如图 7(b)所示 。
- Java基础知识回顾,还记得吗?
- 网络安全:如何使用MSFPC半自动化生成强大的木码?「下集」
- 报道称,华为可能很快将生产和销售汽车零部件,甚至造车
- 数据产品经理PRD—以阿里云会议产品为例(下)
- GitOps—通过CI/CD自动化构建虚拟机模版
- 人工智能如何彻底改变从IVR到销售辅导的商务电话
- 瑞萨电子推出面向物联网基础设施系统的第二代多相数字控制器和智能功率级单元模块(SPS)
- 「购买手机附送充电器」背后的经济学原理
- 特斯拉FSD升级价格降低1000美元:面向增强版Autopiolot车主
- Linux PC供应商ZaReason宣布关闭:销售Linux硬件已十多年