基于PCA和t-SNE可视化词嵌入( 四 )
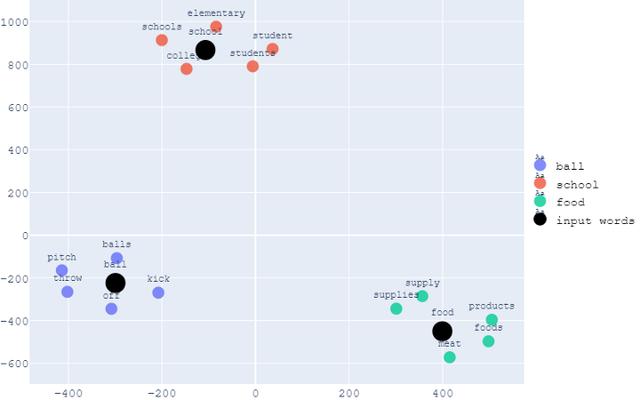
与PCA可视化中相同的示例 , 即与“ball”、“school”和“food”相关的前5个最相似的单词的可视化结果如下所示 。
 文章插图
文章插图
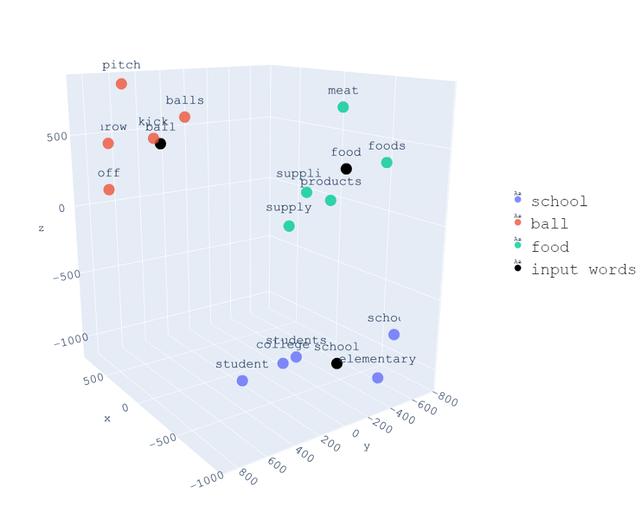
下面是同一组单词的三维可视化 。
 文章插图
文章插图
与PCA相同 , 注意具有相似上下文的单词彼此靠近 , 而具有不同上下文的单词则距离更远 。
创建一个Web应用来可视化词嵌入到目前为止 , 我们已经成功地创建了一个Python脚本 , 用PCA或t-SNE将词嵌入到2D或3D中 。 接下来 , 我们可以创建一个Python脚本来构建一个web应用程序 , 以获得更好的用户体验 。
这个web应用程序使我们能够用大量的功能和交互性来可视化词嵌入 。 例如 , 用户可以键入自己的输入词 , 也可以选择与将返回的每个输入词相关联的前n个最相似的单词 。
可以使用破折号或Streamlit创建web应用程序 。 在本文中 , 我将向你展示如何构建一个简单的交互式web应用程序 , 以可视化Streamlit的词嵌入 。
首先 , 我们将使用之前创建的所有Python代码 , 并将它们放入一个Python脚本中 。 接下来 , 我们可以开始创建几个用户输入参数 , 如下所示:
- 降维技术 , 用户可以选择使用PCA还是t-SNE 。 因为只有两个选项 , 所以我们可以使用Streamlit中的selectbox属性 。
- 可视化的维度 , 在这个维度中 , 用户可以选择将词嵌入2D还是3D显示 。 与之前一样 , 我们可以使用selectbox属性 。
- 输入单词 。 这是一个用户输入参数 , 它要求用户键入他们想要的输入词 , 例如“ball”、“school”和“food” 。 因此 , 我们可以使用text_input属性 。
- Top-n最相似的单词 , 其中用户需要指定将返回的每个输入单词关联的相似单词的数量 。 因为我们可以选择任何数字 。
因为我们使用的是Scikit learn , 所以我们可以参考文档来找出这些参数的默认值 。 perplexity 的默认值是30 , 但是我们可以在5到50之间调整该值 。 学习率的默认值是300 , 但是我们可以在10到1000之间调整该值 。 最后 , 迭代次数的默认值是1000 , 但我们可以将该值调整为250 。 我们可以使用slider属性来创建这些参数值 。
import streamlit as stdim_red = st.sidebar.selectbox( 'Select dimension reduction method', ('PCA','TSNE'))dimension = st.sidebar.selectbox("Select the dimension of the visualization",('2D', '3D'))user_input = st.sidebar.text_input("Type the word that you want to investigate. You can type more than one word by separating one word with other with comma (,)",'')top_n = st.sidebar.slider('Select the amount of words associated with the input words you want to visualize ',5, 100, (5))annotation = st.sidebar.radio("Enable or disable the annotation on the visualization",('On', 'Off'))if dim_red == 'TSNE':perplexity = st.sidebar.slider('Adjust the perplexity. The perplexity is related to the number of nearest neighbors that is used in other manifold learning algorithms. Larger datasets usually require a larger perplexity',5, 50, (30))learning_rate = st.sidebar.slider('Adjust the learning rate',10, 1000, (200))iteration = st.sidebar.slider('Adjust the number of iteration',250, 100000, (1000))
- 文件系统(02):基于SpringBoot管理Xml和CSV
- 基于本质安全的化工行业工业互联网平台“星智链”发布
- 面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测
- 基于Ansible和CodeDeploy的DevOps方案
- 内容|2020腾讯ConTech大会:基于信赖,30位嘉宾带用户打开眼界
- kubernetes-Prometheus基于邮件告警
- Nautilus:一款基于语法的反馈式模糊测试工具
- AMD欲推出基于Navi 23/24的Radeon RX 6000M移动GPU
- 基于python的opencv图像处理实现对斑马线的检测
- 如何基于Docker快速搭建Elasticsearch集群?