基于PCA和t-SNE可视化词嵌入( 二 )
举个例子 , 假设我们想找出与“school”相关联的5个最相似的单词 。 因此 , “school”将是我们的输入词 。 我们的结果是‘college’, ‘schools’, ‘elementary’, ‘students’, 和‘student’ 。
基于PCA的可视化词嵌入现在 , 我们已经有了输入词和基于它生成的相似词 。 下一步 , 是时候让我们把它们在嵌入空间中可视化了 。
通过预训练的模型 , 每个单词都可以用向量表示映射到嵌入空间中 。 然而 , 词嵌入具有很高的维数 , 这意味着无法可视化单词 。
通常采用主成分分析(PCA)等方法来降低词嵌入的维数 。 简言之 , PCA是一种特征提取技术 , 它将变量组合起来 , 然后在保留变量中有价值的部分的同时去掉最不重要的变量 。
有了PCA , 我们可以在2D或3D中可视化词嵌入 , 因此 , 让我们创建代码 , 使用我们在上面代码块中调用的模型来可视化词嵌入 。 在下面的代码中 , 只显示三维可视化 。 为了在二维可视化主成分分析 , 只应用微小的改变 。 你可以在代码的注释部分找到需要更改的部分 。
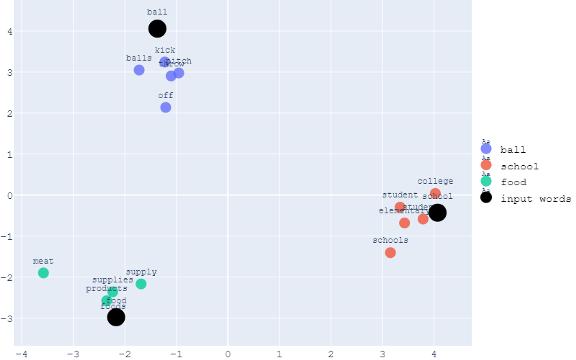
import plotlyimport numpy as npimport plotly.graph_objs as gofrom sklearn.decomposition import PCAdef display_pca_scatterplot_3D(model, user_input=None, words=None, label=None, color_map=None, topn=5, sample=10):if words == None:if sample > 0:words = np.random.choice(list(model.vocab.keys()), sample)else:words = [ word for word in model.vocab ]word_vectors = np.array([model[w] for w in words])three_dim = PCA(random_state=0).fit_transform(word_vectors)[:,:3]# 对于2D , 将three_dim变量改为two_dim , 如下所示:# two_dim = PCA(random_state=0).fit_transform(word_vectors)[:,:2]data = http://kandian.youth.cn/index/[]count = 0for i in range (len(user_input)):trace = go.Scatter3d(x = three_dim[count:count+topn,0],y = three_dim[count:count+topn,1],z = three_dim[count:count+topn,2],text = words[count:count+topn],name = user_input[i],textposition ="top center",textfont_size = 20,mode = 'markers+text',marker = {'size': 10,'opacity': 0.8,'color': 2})#对于2D , 不是使用go.Scatter3d , 我们需要用go.Scatter并删除变量z 。 另外 , 不要使用变量three_dim , 而是使用前面声明的变量(例如two_dim)data.append(trace)count = count+topntrace_input = go.Scatter3d(x = three_dim[count:,0],y = three_dim[count:,1],z = three_dim[count:,2],text = words[count:],name = 'input words',textposition = "top center",textfont_size = 20,mode = 'markers+text',marker = {'size': 10,'opacity': 1,'color': 'black'})# 对于2D , 不是使用go.Scatter3d , 我们需要用go.Scatter并删除变量z 。 另外 , 不要使用变量three_dim , 而是使用前面声明的变量(例如two_dim)data.append(trace_input)# 配置布局layout = go.Layout(margin = {'l': 0, 'r': 0, 'b': 0, 't': 0},showlegend=True,legend=dict(x=1,y=0.5,font=dict(family="Courier New",size=25,color="black")),font = dict(family = " Courier New ",size = 15),autosize = False,width = 1000,height = 1000)plot_figure = go.Figure(data = http://kandian.youth.cn/index/data, layout = layout)plot_figure.show()display_pca_scatterplot_3D(model, user_input, similar_word, labels, color_map)举个例子 , 让我们假设我们想把最相似的5个词与“ball”、“school”和“food”联系起来 。 下面是二维可视化的例子 。
 文章插图
文章插图
- 文件系统(02):基于SpringBoot管理Xml和CSV
- 基于本质安全的化工行业工业互联网平台“星智链”发布
- 面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测
- 基于Ansible和CodeDeploy的DevOps方案
- 内容|2020腾讯ConTech大会:基于信赖,30位嘉宾带用户打开眼界
- kubernetes-Prometheus基于邮件告警
- Nautilus:一款基于语法的反馈式模糊测试工具
- AMD欲推出基于Navi 23/24的Radeon RX 6000M移动GPU
- 基于python的opencv图像处理实现对斑马线的检测
- 如何基于Docker快速搭建Elasticsearch集群?