如何基于Docker快速搭建Elasticsearch集群?
Elasticsearch 作为一个搜索引擎 , 我们对它的基本要求就是存储海量数据并且可以在非常短的时间内查询到我们想要的信息 。 所以第一步我们需要保证的就是 Elasticsearch 的高可用性 , 什么是高可用性呢?它通常是指 , 通过设计减少系统不能提供服务的时间 。 假设系统一直能够提供服务 , 我们说系统的可用性是 100% 。 如果系统在某个时刻宕掉了 , 比如某个网站在某个时间挂掉了 , 那么就可以它临时是不可用的 。 所以 , 为了保证 Elasticsearch 的高可用性 , 我们就应该尽量减少 Elasticsearch 的不可用时间
针对一个索引 , Elasticsearch 中其实有专门的衡量索引健康状况的标志 , 分为三个等级:
- green , 绿色 。 这代表所有的主分片和副本分片都已分配 。 你的集群是 100% 可用的 。
- yellow , 黄色 。 所有的主分片已经分片了 , 但至少还有一个副本是缺失的 。 不会有数据丢失 , 所以搜索结果依然是完整的 。 不过 , 你的高可用性在某种程度上被弱化 。 如果更多的分片消失 , 你就会丢数据了 。 所以可把 yellow 想象成一个需要及时调查的警告 。
- red , 红色 。 至少一个主分片以及它的全部副本都在缺失中 。 这意味着你在缺少数据:搜索只能返回部分数据 , 而分配到这个分片上的写入请求会返回一个异常 。
另外 , 既然是群集 , 那么存储空间肯定也是联合起来的 , 假如一台主机的存储空间是固定的 , 那么集群它相对于单个主机也有更多的存储空间 , 可存储的数据量也更大 。
详细了解 Elasticsearch 集群接下来我们再来了解下集群的结构是怎样的 。
首先我们应该清楚多台主机构成了一个集群 , 每台主机称作一个节点(Node) 。
如图就是一个三节点的集群:
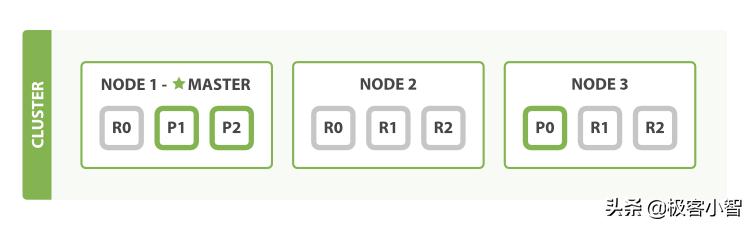 文章插图
文章插图在图中 , 每个 Node 都有三个分片 , 其中 P 开头的代表 Primary 分片 , 即主分片 , R 开头的代表 Replica 分片 , 即副本分片 。 所以图中主分片 1、2 , 副本分片 0 储存在 1 号节点 , 副本分片 0、1、2 储存在 2 号节点 , 主分片 0 和副本分片 1、2 储存在 3 号节点 , 一共是 3 个主分片和 6 个副本分片 。 同时我们还注意到 1 号节点还有个 MASTER 的标识 , 这代表它是一个主节点 , 它相比其他的节点更加特殊 , 它有权限控制整个集群 , 比如资源的分配、节点的修改等等 。
这里就引出了一个概念就是节点的类型 , 我们可以将节点分为这么四个类型:
- 主节点:即 Master 节点 。 主节点的主要职责是和集群操作相关的内容 , 如创建或删除索引 , 跟踪哪些节点是群集的一部分 , 并决定哪些分片分配给相关的节点 。 稳定的主节点对集群的健康是非常重要的 。 默认情况下任何一个集群中的节点都有可能被选为主节点 。 索引数据和搜索查询等操作会占用大量的cpu , 内存 , io资源 , 为了确保一个集群的稳定 , 分离主节点和数据节点是一个比较好的选择 。 虽然主节点也可以协调节点 , 路由搜索和从客户端新增数据到数据节点 , 但最好不要使用这些专用的主节点 。 一个重要的原则是 , 尽可能做尽量少的工作 。
- 数据节点:即 Data 节点 。 数据节点主要是存储索引数据的节点 , 主要对文档进行增删改查操作 , 聚合操作等 。 数据节点对 CPU、内存、IO 要求较高 , 在优化的时候需要监控数据节点的状态 , 当资源不够的时候 , 需要在集群中添加新的节点 。
- 负载均衡节点:也称作 Client 节点 , 也称作客户端节点 。 当一个节点既不配置为主节点 , 也不配置为数据节点时 , 该节点只能处理路由请求 , 处理搜索 , 分发索引操作等 , 从本质上来说该客户节点表现为智能负载平衡器 。 独立的客户端节点在一个比较大的集群中是非常有用的 , 他协调主节点和数据节点 , 客户端节点加入集群可以得到集群的状态 , 根据集群的状态可以直接路由请求 。
- 文件系统(02):基于SpringBoot管理Xml和CSV
- Chiplet如何开拓半导体技术的未来
- 如何编写JAVA小白第一个程序
- 如何进行不确定度估算:模型为何不确定以及如何估计不确定性水平
- 学大数据是否有前途 如何系统掌握大数据技术
- Python爬虫入门第一课:如何解析网页
- 小辣椒要移花接木,金立要借尸还魂,抄袭现象如何破
- 如何使用 lshw 查看 Linux 设备信息
- 华为科普:芯片是如何设计的
- 网络安全:如何使用MSFPC半自动化生成强大的木码?「下集」