机器翻译:谷歌翻译是如何对几乎所有语言进行翻译的?( 六 )
下一步是定义解码器 。 解码器将有两个输入:编码器的隐藏状态和单元状态 , 它们实际上是开头添加了令牌后的输出语句 。
decoder_inputs =Input(shape=(max_out_len,))decoder_embedding =Embedding(num_words_output,LSTM_NODES)decoder_inputs_x =decoder_embedding(decoder_inputs)decoder_lstm =LSTM(LSTM_NODES,return_sequences=True, return_state=True)decoder_outputs, _, _ =decoder_lstm(decoder_inputs_x,initial_state=encoder_states)#Finally, theoutput from the decoder LSTM is passed through a dense layer to predict decoderoutputs.decoder_dense =Dense(num_words_output,activation='softmax')decoder_outputs =decoder_dense(decoder_outputs)训练模型
编译定义了优化器和交叉熵损失的模型 。
#Compilemodel =Model([encoder_inputs,decoder_inputs],decoder_outputs)model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])model.summary()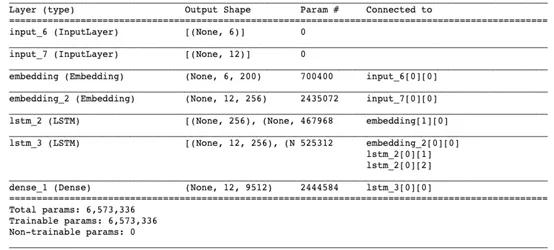 文章插图
文章插图结果在意料之中 。 编码器lstm_2接受来自嵌入层的输入 , 而解码器lstm_3使用编码器的内部状态及嵌入层 。 该模型总共有大约650万个参数!训练模型时 , 笔者建议指定EarlyStopping()的参数 , 以避免出现计算资源的浪费和过拟合 。
es =EarlyStopping(monitor='val_loss', mode='min', verbose=1)history = model.fit([encoder_input_sequences,decoder_input_sequences], decoder_targets_one_hot,batch_size=BATCH_SIZE,epochs=20,callbacks=[es],validation_split=0.1,)保存模型权重 。model.save('seq2seq_eng-fra.h5')绘制训练和测试数据的精度曲线 。#Accuracyplt.title('model accuracy')plt.plot(history.history['accuracy'])plt.plot(history.history['val_accuracy'])plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'test'], loc='upper left')plt.show()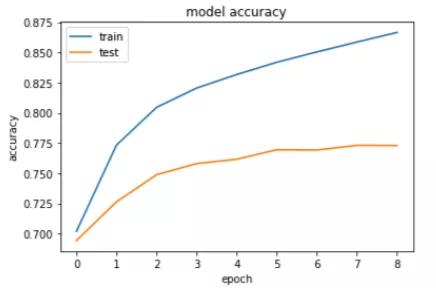 文章插图
文章插图如大家所见 , 该模型达到了约87%的训练精度和约77%的测试精度 , 这表示该模型出现了过拟合 。 我们只用20000条记录进行了训练 , 所以大家可以添加更多记录 , 还可以添加一个dropout层来减少过拟合 。
测试机器翻译模型
加载模型权重并测试模型 。
encoder_model = Model(encoder_inputs, encoder_states)model.compile(optimizer='rmsprop', loss='categorical_crossentropy')model.load_weights('seq2seq_eng-fra.h5')【机器翻译:谷歌翻译是如何对几乎所有语言进行翻译的?】设置好权重之后 , 是时候通过翻译几个句子来测试机器翻译模型了 。 推理模式的工作原理与训练过程略有不同 , 其过程可分为以下4步:· 编码输入序列 , 返回其内部状态 。
· 仅使用start-of-sequence字符作为输入 , 并使用编码器内部状态作为解码器的初始状态来运行解码器 。
· 将解码器预测的字符(在查找令牌之后)添加到解码序列中 。
· 将先前预测的字符令牌作为输入 , 重复该过程 , 更新内部状态 。
由于只需要编码器来编码输入序列 , 因此我们将编码器和解码器分成两个独立的模型 。
decoder_state_input_h =Input(shape=(LSTM_NODES,))decoder_state_input_c=Input(shape=(LSTM_NODES,))decoder_states_inputs=[decoder_state_input_h, decoder_state_input_c]decoder_inputs_single=Input(shape=(1,))decoder_inputs_single_x=decoder_embedding(decoder_inputs_single)decoder_outputs,h, c =decoder_lstm(decoder_inputs_single_x, initial_state=decoder_states_inputs)decoder_states = [h, c]decoder_outputs =decoder_dense(decoder_outputs)decoder_model =Model([decoder_inputs_single] +decoder_states_inputs,[decoder_outputs] + decoder_states
- 高通和联发科慌了?谷歌将推出自研手机和电脑芯片
- SOTA论文也未必能被接收,谷歌科学家谈顶会审稿标准
- 谷歌发布新工具帮助城市“降温”
- 谷歌推AI工具Verse by Verse:能写出知名诗人风格的诗歌
- 超越谷歌,半导体双量子比特保真度达99.99%
- 「翻译」虚拟内存介绍
- Python爬取有道翻译(破解加密--js加密)
- 谷歌完成Chimera Painter开发工作:使用GAN来生成噩梦生物的网页工具
- Waymo与谷歌提出TNT模型,实现自动驾驶多轨迹行为预测
- 海外|英媒:继谷歌之后,美国政府计划下周对脸书提起诉讼