机器翻译:谷歌翻译是如何对几乎所有语言进行翻译的?( 二 )
通过为输入和输出语言创建词汇表 , 人们可以将该技术应用于任何语言中的任何句子 , 从而将语料库中所有已翻译的句子彻底转换为适用于机器翻译任务的格式 。
现在来一起感受一下编码器-解码器算法背后的魔力 。 在最基本的层次上 , 模型的编码器部分选择输入语言中的某个句子 , 并从该句中创建一个语义向量(thought vector) 。 该语义向量存储句子的含义 , 然后将其传递给解码器 , 解码器将句子译为输出语言 。
 文章插图
文章插图
编码器-解码器结构将英文句子“Iam astudent”译为德语
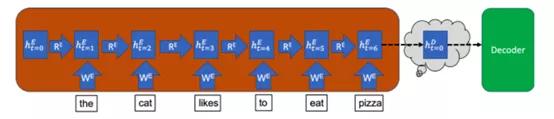
就编码器来说 , 输入句子的每个单词会以多个连续的时间步分别输入模型 。 在每个时间步(t)中 , 模型都会使用该时间步输入到模型单词中的信息来更新隐藏向量(h) 。
该隐藏向量用来存储输入句子的信息 。 这样 , 因为在时间步t=0时尚未有任何单词输入编码器 , 所以编码器在该时间步的隐藏状态从空向量开始 。 下图以蓝色框表示隐藏状态 , 其中下标t=0表示时间步 , 上标E表示它是编码器(Encoder)的隐藏状态[D则用来表示解码器(Decoder)的隐藏状态] 。
 文章插图
文章插图
在每个时间步中 , 该隐藏向量都会从该时间步的输入单词中获取信息 , 同时保留从先前时间步中存储的信息 。 因此 , 在最后一个时间步中 , 整个输入句子的含义都会储存在隐藏向量中 。 最后一个时间步中的隐藏向量就是上文中提到的语义向量 , 它之后会被输入解码器 。
另外 , 请注意编码器中的最终隐藏向量如何成为语义向量并在t=0时用上标D重新标记 。 这是因为编码器的最终隐藏向量变成了解码器的初始隐藏向量 。 通过这种方式 , 句子的编码含义就传递给了解码器 , 从而将其翻译成输出语言 。 但是 , 与编码器不同 , 解码器需要输出长度可变的译文 。 因此 , 解码器将在每个时间步中输出一个预测词 , 直到输出一个完整的句子 。
开始翻译之前 , 需要输入标签作为解码器第一个时间步的输入 。 与编码器一样 , 解码器将在时间步t=1处使用输入来更新其隐藏状态 。 但是 , 解码器不仅会继续进行到下一个时间步 , 它还将使用附加权重矩阵为输出词汇表中的所有单词创建概率 。 这样 , 输出词汇表中概率最高的单词将成为预测输出句子中的第一个单词 。
解码器必须输出长度可变的预测语句 , 它将以该方式继续预测单词 , 直到其预测语句中的下一个单词为
通过Keras和Python实现神经网络机器翻译
了解了编码器-解码器架构之后 , 创建一个模型 , 该模型将通过Keras和python把英语句子翻译成法语 。 第一步 , 导入需要的库 , 为将在代码中使用的不同参数配置值 。
#Import Librariesimport os, sysfrom keras.models importModelfrom keras.layers importInput, LSTM, GRU, Dense, Embeddingfromkeras.preprocessing.text importTokenizerfromkeras.preprocessing.sequence import pad_sequencesfrom keras.utils import to_categoricalimport numpy as npimport pandas as pdimport pickleimportmatplotlib.pyplot as plt#Values fordifferent parameters:BATCH_SIZE=64EPOCHS=20LSTM_NODES=256NUM_SENTENCES=20000MAX_SENTENCE_LENGTH=50MAX_NUM_WORDS=20000EMBEDDING_SIZE=200数据集
我们需要一个包含英语句子及其法语译文的数据集 , 下载fra-eng.zip文件并将其解压 。 每一行的文本文件都包含一个英语句子及其法语译文 , 通过制表符分隔 。 继续将每一行分为输入文本和目标文本 。
- 高通和联发科慌了?谷歌将推出自研手机和电脑芯片
- SOTA论文也未必能被接收,谷歌科学家谈顶会审稿标准
- 谷歌发布新工具帮助城市“降温”
- 谷歌推AI工具Verse by Verse:能写出知名诗人风格的诗歌
- 超越谷歌,半导体双量子比特保真度达99.99%
- 「翻译」虚拟内存介绍
- Python爬取有道翻译(破解加密--js加密)
- 谷歌完成Chimera Painter开发工作:使用GAN来生成噩梦生物的网页工具
- Waymo与谷歌提出TNT模型,实现自动驾驶多轨迹行为预测
- 海外|英媒:继谷歌之后,美国政府计划下周对脸书提起诉讼