机器翻译:谷歌翻译是如何对几乎所有语言进行翻译的?( 三 )
input_sentences = []output_sentences = []output_sentences_inputs = []count =0for line inopen('./drive/MyDrive/fra.txt', encoding="utf-8"):count +=1if count >NUM_SENTENCES:breakif'\t'notin line:continueinput_sentence = line.rstrip().split('\t')[0]output = line.rstrip().split('\t')[1]output_sentence = output +' Output:Number of sample input: 20000Number of sample output: 20000Number of sample output input: 20000在上面的脚本中创建input_sentences[]、output_sentences[]和output_sentences_inputs[]这三个列表 。 接下来 , 在for循环中 , 逐个读取每行fra.txt文件 。 每一行都在制表符出现的位置被分为两个子字符串 。 左边的子字符串(英语句子)插入到input_sentences[]列表中 。 制表符右边的子字符串是相应的法语译文 。
此处表示句子结束的
print("English sentence: ",input_sentences[180])print("French translation: ",output_sentences[180])Output:English sentence:Join us.French translation:Joignez-vous à nous.标记和填充
下一步是标记原句和译文 , 并填充长度大于或小于某一特定长度的句子 。 对于输入而言 , 该长度将是输入句子的最大长度 。 对于输出而言 , 它也是输出句子的最大长度 。 在此之前 , 先设想一下句子的长度 。 将分别在两个单独的英语和法语列表中获取所有句子的长度 。
eng_len = []fren_len = []# populate thelists with sentence lengthsfor i ininput_sentences:eng_len.append(len(i.split()))for i inoutput_sentences:fren_len.append(len(i.split()))length_df = pd.DataFrame({'english':eng_len, 'french':fren_len})length_df.hist(bins =20)plt.show()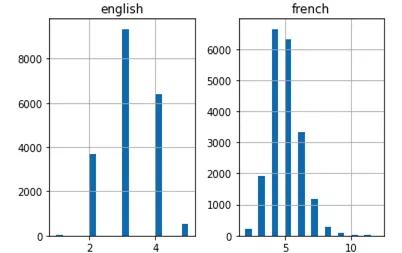 文章插图
文章插图
上面的直方图显示 , 法语句子的最大长度为12 , 英语句子的最大长度为6 。
接下来 , 用Keras的Tokenizer()类矢量化文本数据 。 句子将因此变为整数序列 。 然后 , 用零填充这些序列 , 使它们长度相等 。
标记器类的word_index属性返回一个单词索引词典 , 其中键表示单词 , 值表示对应的整数 。 最后 , 上述脚本打印出词典中唯一单词的数量和输入的最长英文句子的长度 。
#tokenize the input sentences(inputlanguage)input_tokenizer =Tokenizer(num_words=MAX_NUM_WORDS)input_tokenizer.fit_on_texts(input_sentences)input_integer_seq = input_tokenizer.texts_to_sequences(input_sentences)print(input_integer_seq)word2idx_inputs =input_tokenizer.word_indexprint('Total uniquewords in the input: %s'%len(word2idx_inputs))max_input_len =max(len(sen) for sen in input_integer_seq)print("Length oflongest sentence in input: %g"% max_input_len)Output:Total unique words in the input: 3501Length of longest sentence in input: 6同样 , 输出语句也可以用相同的方式标记:
- 高通和联发科慌了?谷歌将推出自研手机和电脑芯片
- SOTA论文也未必能被接收,谷歌科学家谈顶会审稿标准
- 谷歌发布新工具帮助城市“降温”
- 谷歌推AI工具Verse by Verse:能写出知名诗人风格的诗歌
- 超越谷歌,半导体双量子比特保真度达99.99%
- 「翻译」虚拟内存介绍
- Python爬取有道翻译(破解加密--js加密)
- 谷歌完成Chimera Painter开发工作:使用GAN来生成噩梦生物的网页工具
- Waymo与谷歌提出TNT模型,实现自动驾驶多轨迹行为预测
- 海外|英媒:继谷歌之后,美国政府计划下周对脸书提起诉讼