浅谈 MaxCompute 资源规划管理及评估( 五 )
第1条方法:每个MaxCompute project 对应1个独立的quota group子资源组;
第2条方法:每个quota group子资源组的min 资源量不小于 “默认预付费Quota”的5% , 建议也不大于“默认预付费Quota”的20% 。 具体原因:如果将子资源组的min资源量设置太大 , 比如超过20% , 那么各个资源组的min资源量之和就会接近或者超过“默认预付费Quota” , 那么划分子资源组将会失去意义 , 最终造成资源大量浪费 。
第3条方法:每个quota group子资源组的max 资源量不小于“默认预付费Quota”的40% , 当然最大可以设置到“默认预付费Quota” 。 如果子资源组的max 资源量设太小 , 在集群运行任务空闲的时候 , 资源会造成极大浪费 。
除了上述三条基本方法之外 , 还有几个比较实用的方法:
第4条方法:对于企业客户划分的多个MaxCompute project , 需要统计每个project 的cost_cpu消耗量“cpu核数 *小时” , 并按照消耗量进行排序 。 消耗量最大的MaxCompute project对应的子资源组的max资源量可以设置为“默认预付费Quota”的80%以上 , 其他project对应的子资源组按照排序 , 设置的max资源量以此减少 , 直到最后的子资源组的max资源量不小于“默认预付费Quota”的40% 。
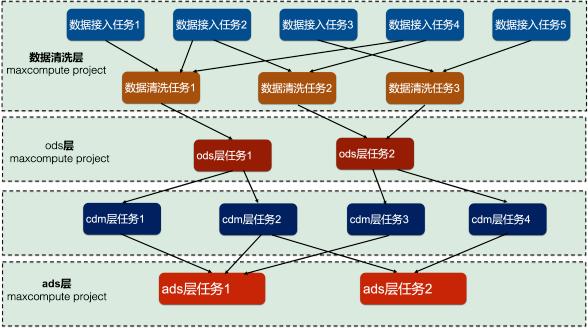
第5条方法:考虑任务调度与依赖关系对于很多企业客户 , 使用DataWorks/Dataphin需要做任务调度 。 任务调度就必然有父子任务关系 。 比如笔者在本文列举的实际案例 , 对于数据中台项目 , 划分了8个MaxCompute project , 分别是:数据清洗的两个project、ods贴源层的两个project、cdm公共层的两个project、ads应用层的两个project 。 每个project分配一个独立的quota group子资源组 。 数据分层有严格的先后顺序:数据清洗的任务是ods层任务的父任务;ods层任务是cdm层任务的父任务;cdm层任务是ads层任务的父任务 , 他们之间的任务调度关系如下所示:
 文章插图
文章插图
对于这类常见的不同MaxCompute project的任务之间有严格的调度依赖关系 , 不能简单的按照上述的方法设置资源组的min资源量和max资源量 。 因为上一个层次有几百个任务需要运行、下一个层次也有几百个任务需要运行 , 而且这些任务之间是混合运行的 。 比如:某个工作流的几十个ods层任务运行完成 , 那么接下来将会运行对应的几十个cdm层任务;与此同时 , 数据清洗层和ods层还会运行新的任务;cdm层和ads层也会运行所有上游都运行完成的任务 。 这些任务之间混合在一起运行 , 为资源组划分资源量添加了很多变数 。 此时需要根据实际项目经验 , 为这些资源组分配min资源量和max资源量 。
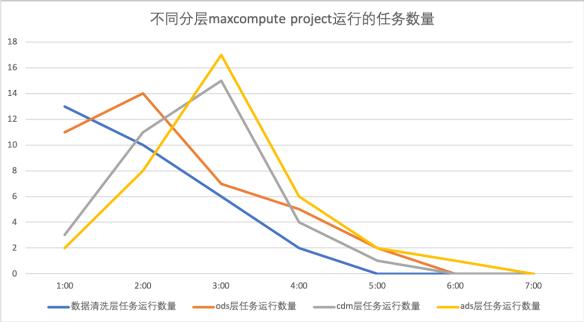
比如笔者这边的项目情况如下:数据清洗层因为涉及很多业务系统原始数据表的join操作 , 非常消耗CU资源;ods层经常是导入清洗之后的数据即可 , 不需要消耗太多资源;cdm层规范建模 , 任务运行方法比较固定 , 因为我们在数据清洗层已经将数据做规范化处理 , 因此cdm层消耗的CU资源也很少;最后 , 将cdm的派生指标融合进ads层 , 需要做很多复杂的join操作 , 因此消耗的CU资源非常多 。 并且 , 从晚上1点到凌晨7点之间 , 这四个层次对应的项目运行消耗的资源量呈现“错峰”情况 。 下图是我们在进行测试环节统计的情况:
 文章插图
文章插图
可以明显看出来 , 四个层次运行任务的数量呈现“错峰”情况 , 每个层次出现的任务高峰会以此延后一段时间 , 该层次MaxCompute project消耗的资源量也是呈现错峰 。 鉴于上述场景分析 , 我们考虑在第4条方法的基础上 , 将不同层次“错峰”高峰运行的因素也考虑在内 。 尽可能让消耗资源多的项目分配的max资源量更大 , 但是因为“错峰”运行因素 , 消耗资源少的项目分配的max资源量也不能太小 , 尽可能分配大一些 , 让资源得到合理应用 。 笔者为该项目设计4个quota 资源组:
- 浅谈如何开好一家手机维修店(三):指南舟手机维修培训学校
- 「攻防论道」浅谈聚铭网络iNFA系统隐蔽通道检测
- 浅谈音响音源输入的选择问题
- pyecharts 生成网页后,资源加载缓慢,你知道怎么解决吗?
- 浅谈如何开好一家手机维修店(五):指南舟手机维修培训学校
- 终于有资源了!ACR13.0独立安装包 WIN/MAC双版本
- 连锁美业+互联网,四种可以资源整合又能拆分运营的变现法则
- 通过Serverless技术降低微服务应用资源成本
- 新快珠中江|中山东区人力资源服务产业园揭牌
- 质量山西新闻|助力“汾老大”复兴,破亿!汾酒电商“抢占”消费者心智资源