浅谈 MaxCompute 资源规划管理及评估( 四 )
Step4:得到MaxCompute计算资源CU数量:202 CPU核数 *小时 / 5小时 = 40.2 cores核数 , 也就是至少需要41 CU 。 因此建议客户购买计算资源CU量为 41*2 = 82 CU数量 。
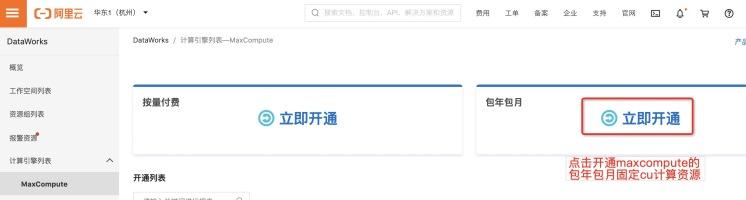
根据预估计算结果 , 我们为客户推荐购买的包年包月固定CU量为82个 。 先开通MaxCompute 计算资源quota group 资源组的包年包月固定CU资源:
 文章插图
文章插图
然后配置总CU量为82个 。
四、浅谈MaxCompute group quota 资源划分方法笔者在第3章节详细介绍如何根据最近一段时间的CU消耗情况 , 预估得到MaxCompute 计算资源CU数量 。 购买的MaxCompute quota group资源属于“默认预付费Quota” , 类似于开源hadoop yarn的root资源队列 。 在实际项目开发过程中 , 还需要将“默认预付费Quota”再细分为若干个“子quota group资源组” 。 当然 , 一般情况下建议1个MaxCompute project 划分1个子quota group资源组 。 如何将“默认预付费Quota”划分为若干个子quota group资源组?这是本章节需要详细介绍的内容 。
4.1 fuxi伏羲资源调度系统原理简介
为了便于读者理fuxi调度系统关于资源组的资源分配和资源抢占机制 , 本文以开源hadoop yarn资源队列进行类比 。 MaxCompute的“默认预付费Quota”类似于yarn的root资源队列 , 这部分计算资源属于“总计算资源组” , 需要将总资源组进行细分 。
假设我们购买的“默认预付费Quota”包含Dt个CU资源 , 然后“默认预付费Quota”被划分了n个子资源组D1、D2 …… Dn。 这n个资源组必须设置两个重要参数:资源组的“预留CU最小配额”minD1、minD2……minDn , 以及“预留CU最大配额” maxD1、maxD2……maxDn 。 这n个资源组必须满足以下条件:
- minD1 + minD2 + …… + minDn = Dt
- 对于任意的子资源组的maxDi , maxDi <= Dt
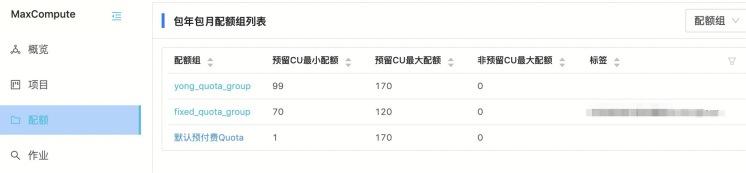
如下图所示 , 170个CU资源量的“默认预付费Quota”划分了两个子资源组:
 文章插图
文章插图从上图我们看到 , 划分的两个子资源组yong_quota_group 和 fixed_quota_group设置的最小CU配额、最大CU配额 , 满足上述两个条件 。
4.2 MaxCompute计算资源抢占机制
按照4.1介绍的内容 , 若干个子资源组的max最大CU配额都可以设置为“默认预付费Quota” , 那么一旦所有资源组对应的MaxCompute project都疯狂地运行任务 , 那么必然存在资源抢占的问题 。 按照默认规则 , MaxCompute资源组的资源抢占按照“fair scheduling”公平调度机制 , 先提交的任务优先获取CU资源 。 那么 , 如果某个MaxCompute project提交超大型任务 , 必然将会把CU资源消耗殆尽 。 此时 , 其他资源组对应的MaxCompute project提交的任务将会因为无法获取到CU资源而被阻塞 。
如何更加完美地划分quota group资源组 , 并且为每个资源组分配最合理的 min资源配额、max资源配额? 如何结合实际项目需求 , 合理安排任务运行的先后顺序、以及任务运行调度的依赖关系?这是划分子quota group资源组需要考虑的重点因素 。
4.3 quota group资源组划分
在第3章节详细介绍如何预估计算企业客户需要购买的包年包月预留CU量 , 也就是 “默认预付费Quota” , 比如3.3.3章节的实际案例里面介绍的170个CU 。 下一步就是创建子quota group资源组 , 并为每个quota group分配 min、max资源量 。 笔者结合多年hadoop yarn资源分配经验 , 以及使用MaxCompute的一些经验 , 总结了一些实际的经验 。
- 浅谈如何开好一家手机维修店(三):指南舟手机维修培训学校
- 「攻防论道」浅谈聚铭网络iNFA系统隐蔽通道检测
- 浅谈音响音源输入的选择问题
- pyecharts 生成网页后,资源加载缓慢,你知道怎么解决吗?
- 浅谈如何开好一家手机维修店(五):指南舟手机维修培训学校
- 终于有资源了!ACR13.0独立安装包 WIN/MAC双版本
- 连锁美业+互联网,四种可以资源整合又能拆分运营的变现法则
- 通过Serverless技术降低微服务应用资源成本
- 新快珠中江|中山东区人力资源服务产业园揭牌
- 质量山西新闻|助力“汾老大”复兴,破亿!汾酒电商“抢占”消费者心智资源