搭载于云燧i20的新一代“邃思”采用12nm工艺、第二代高性能计算核心和数据引擎,通过升级其自研架构GCU-CARA(通用计算单元和全域计算架构),大大提高了单位面积的晶体管效率,实现堪与当前业内7nm GPU匹敌的计算能力。

文章插图
得益于12nm成熟工艺带来的成本优势,云燧i20在相同性能表现下更具性价比优势,且供应链体系更加稳定成熟,能及时满足客户的业务需求。
从算力规格来看,其目标实现得相当不错:
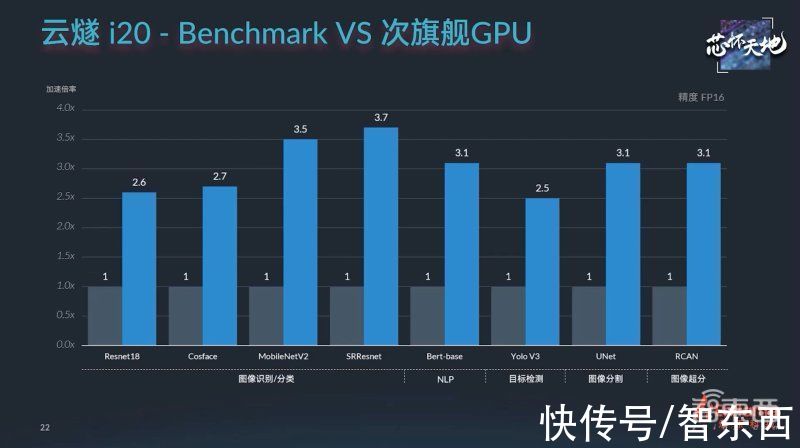
文章插图
计算方面,云燧i20全面支持从FP32、TF32、FP16、BF16到INT8的计算精度,并在兼顾全精度算力的同时,大幅提高了整型运算。
其单精度FP32峰值算力达到32TFLOPS,单精度张量TF32峰值算力达到128TFLOPS,整型INT8峰值算力达到256TOPS。
通过软硬件技术多重优化,云燧i20大幅提升了推理性能,浮点算力较云燧i10提升到1.8倍,整型算力提升到3.6倍。
与主流旗舰GPU相比,云燧i20的模型性能可以对标英伟达A10,是T4的2.5~3倍,并在性能深度优化能力、成本方面更具优势。
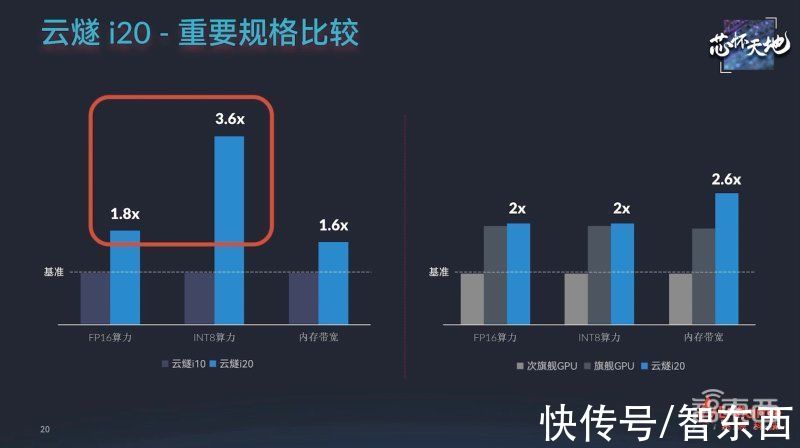
文章插图
存储方面,云燧i20拥有迄今业内最大的云端AI加速卡存储带宽。
此前燧原科技第二代云端AI训练芯片在国内率先支持HBM2E高带宽存储方案。如今云燧i20推理加速卡更进一步,基于HBM2E可提供超越同类产品水平的819GB/s超大存储带宽,为各类云端推理业务提供高吞吐、低延时的性能。
如今神经网络参数越来越多,无论是语音识别、图片识别、视频内容分析等感知类应用,还是内容推荐、欺诈交易拦截等决策类AI应用,在云端大部分都是以实时在线的方式提供服务,对数据带宽的需求不断上涨。而速度更快、密度更高的内存,有助于高端处理器兼顾高带宽和低延迟,保障AI相关服务准确、平稳、高效的运行。
软件方面,根据客户反馈的需求,燧原将其推理软件栈驭算进一步升级,使其在性能、开发效率和模型覆盖面上得到大幅提升。

文章插图
驭算引入了通用高层图优化和大规模算子融合技术,充分释放了大容量片内存储和高带宽存储的利用率,将模型平均性能提升3.5倍,硬件算力利用率平均提升2倍。
为了更加匹配客户开发习惯,驭算通过升级的编程模型以及算子自动分片、自动生成技术,使得自定义算子开发效率翻倍,大大降低模型迁移成本。驭算还增强了对动态性的支持,使云燧i20在检测、语音识别、语义理解等场景更具竞争力。
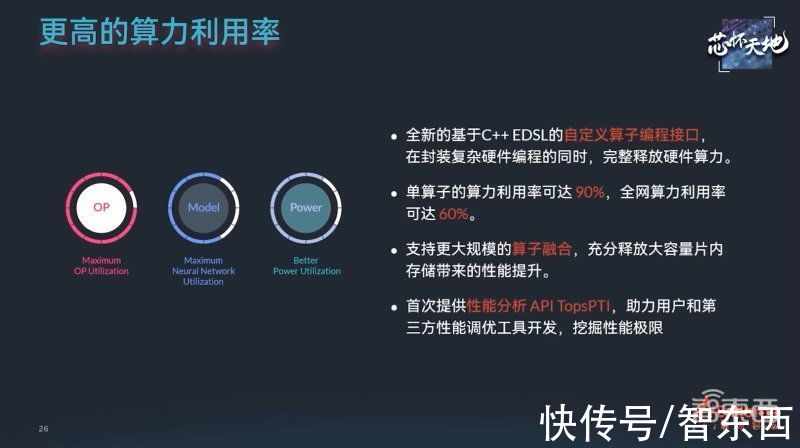
文章插图
在经济效益和部署灵活性层面,基于虚拟化和多实例加速技术,云燧i20能够实现单卡多用户,同时支持6个业务互不干扰、安全隔离运行。这让更多云端推理应用同时享受专有的算力加速,为客户业务架构带来轻耦合、灵活可靠的实现方式,显著提升资源利用率与投入产出比。
作为一家数据中心基础设施提供商,燧原科技已经能提供包括算力、数据、存储、互联在内的一系列系统化解决方案。

文章插图
三、一代落地、二代量产、三代设计,高效滚动式研发背后的三大核心竞争力对于创业公司来说,云端AI芯片是难攻的高地。
一方面,芯片研发有高壁垒、高成本、低容错率等特征,任何一个环节出现差池,此前投入的数千万资金就可能通通打水漂。另一方面,NVIDIA独霸云端AI训练市场,英特尔不断强化CPU的AI推理性能,其技术和生态壁垒均十分深厚。
面对残酷的市场环境,燧原科技一路高举高打,快速迭代研发落地,第一代产品还未量产,第二代产品已经开始滚动式研发。
是怎样的底气,让燧原无惧风险,制定如此紧密的产品迭代周期?张亚林将燧原科技的核心竞争力归纳为三点:迭代快、系统化、成熟配置。
首先,天下武功,唯快不破。
云端AI产品具有共享的、多用户等特征,每个客户有差异化的场景及业务模型,与对AI芯片架构的通用性提出了更高要求。相比芯片采用几纳米工艺、什么技术,云端AI客户更关注迁移成本、降本增效和性价比是否能达到自身应用的要求。
“当我们开始工程化AI产品的时候,一定要把客户的终极诉求和用户使用习惯带进去,而不是一味地讲纸面参数。”张亚林认为,只有进入客户整个业务系统,才能够真正理解其需求。
- 数据库|国产厂商自研芯片,算力“媲美”苹果A15,首发机皇即将登场!
- 英伟达|RTX 4080性能出炉:算力恐怖达90T,比两块RTX 3090Ti还强
- 合并|比特大陆支持的数字资产云算力服务提供商BitFuFu通过Arisz SPAC上市
- 算力|Meta首台AI超算出炉!1.6万块英伟达GPU加持,算力暴涨20倍
- 显卡|老黄出手控制显卡加价了!RTX 3050算力被阉割,矿工彻底绝望
- 智算中心|商汤智算中心即将建成投产 未来将提供大规模弹性算力
- 飞利浦·斯塔克|RTX3050这价格还有这挖矿算力,1899元香不香?
- 天玑9000|独立AI+高算力ISP旗舰影像必备,联发科方向对了!天玑9000拍照技术拉满
- 自动驾驶|焦点分析|从全球霸主到算力掉队,这家芯片公司决定撕掉“封闭”标签
- 哈萨克斯坦|哈萨克斯坦断网,比特币全球算力消失12%