按关键词阅读: 设备 检测 半导体 印芯半导体

文章插图
我采用这种方法的动机之一,是在因果发现的背景下发现良好的因果模型和对观察的良好解释。在这些环境中,我们拥有一个 oracle,或一个黑匣子,或现实世界,或一个实验装置,我们可以对它进行查询,进行试验,或者可以尝试输入 x 的一些配置。
这些输入是查询 x,它们进入这个黑匣子,然后我们得到一个输出 f(x)。f 是一个标量,是我们选择的 x 的好坏指标。例如,一种分子的某个性质有多好?答案一般通过实验分析得到。我们不知道 f 里面发生了什么,但我们想找到 f 的高值。也就是说,我们想找到使得 f 很大的 x。更一般地说,我们希望获得大量好的解决方案。
这里还涉及到一个“多样性”的概念,以及一个“探索”的概念,因为我们将能够通过许多路由多次查询该 oracle。
最初,当我们不太了解 f 时,我们更多处于探索模式。我们将尝试不同的 x 值,并让学习器对 f 内部发生的事情有所了解。在这些过程即将结束时,从而获得有限信息时,我们可能更多处于强化学习的“利用”模式
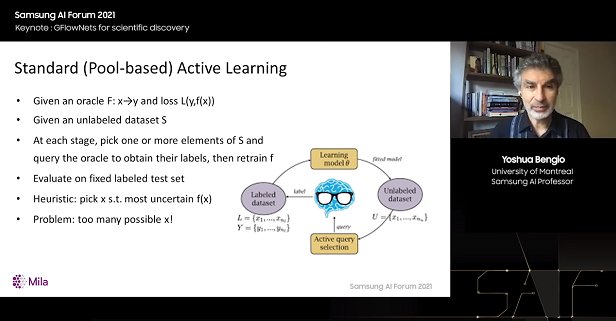
基于池的主动学习
因此,这种方法与强化学习之间存在联系,但也存在差异,并与主动学习有关。经典的主动学习,也称为基于池的主动学习(Pool-based Active Learning),就是这样工作的。我们有一个像上述一样的 oracle,它是一个从输入 x 到某个标量的函数。我们也有一个例子池 s,我们不知道答案,并希望调用 oracle 来找出答案。
文章插图
所以在主动学习的每个阶段,学习器都会主动提出问题。而在传统的机器学习中,我们只是观察一组例子,然后从中学习。
在这里,除了已有的例子,我们还可以提出问题。例如,“对于一张图片,正确的标签是什么?”这就是主动学习。
这种方法的问题在于,在许多情况下,我们并没有一组固定的x配置。相反,我们希望能够在高维空间中提出任何问题,但这又可能遭遇指数爆炸。
我们从主动学习文献中学到的重要教训是如何选择这些查询,这里的基本思想是:我们想要估计预测变量f的不确定性。换句话说,对于要估计的函数,我们希望选择能够提供尽可能多信息的问题。
正如我所说,基于池的主动学习的问题是无法穷举,例如,无法穷举所有的分子,然后只需查询那些具有高不确定性的分子。我们需要以某种方式处理数量呈指数级增长的可能问题。
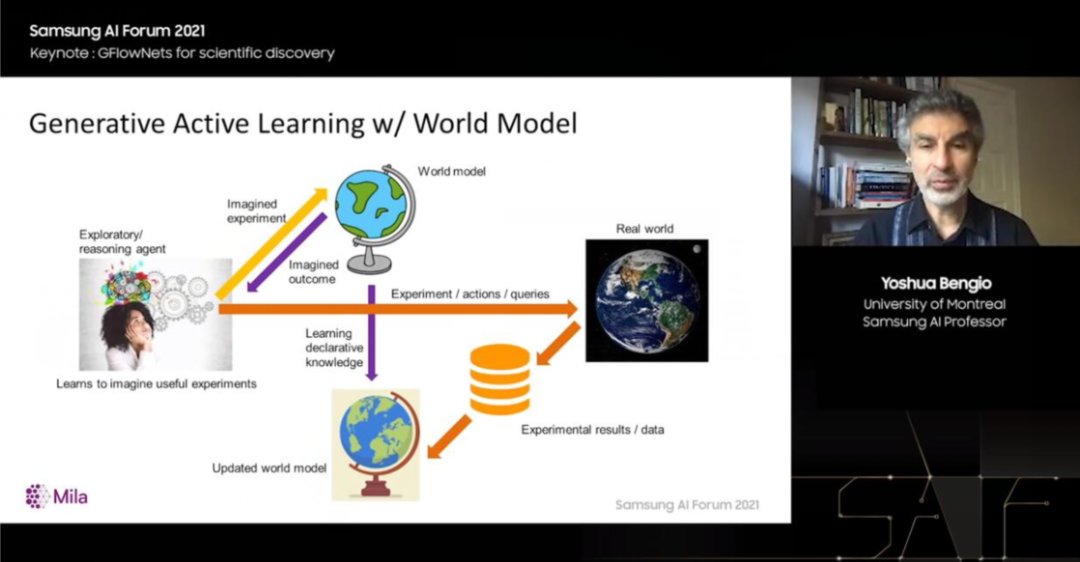
生成式主动学习
所以,我提议遵循的原则是生成式主动学习(Generative Active Learning),这是本次演讲最重要的内容,当学习器可以选择其希望现实世界提供答案的问题时,应该进行哪些实验?
文章插图
在高维空间中,一个不错的方案是:训练一个生成模型,该模型将对好问题进行采样。
要怎么训练这个模型呢?首先,我们观察现实世界,然后提出一些问题,接下来进行一些实验,将这些实验结果加载到一个数据集中。
因此,有了该数据集,我们就可以进行传统的机器学习方法。我们可以学习一个模型,比如给定 x 预测 y,我们也可以使用该模型来筛选潜在问题。
根据该模型,如果我们发现一个问题得分很高,比如很高的不确定性,那么这可能是一个好问题。
正如我所说,困难在于潜在的问题太多了。因此,仅凭预测候选实验的好坏程度是不够的,所以我们要训练这个生成模型。不过,我们将以一种与通常的生成模型不太相同的方式来训练它。
通常的训练生成模型的方式是利用一组固定的例子。但在这里,我们有一个由世界模型计算的函数,它会告诉我们特定的实验有多大用处。我们将采用这种特殊的方式来训练生成模型,寻找生成具有高f值的配置。
可能有很多方法可以做到这一点,但如果目标不仅仅是优化,而是找到不同的好的解决方案,那么合理的做法就是将分数换算。接下来,我们将基于世界模型获得一种奖励函数,使得生成模型不是最大化奖励,而是获得具有高回报的样本问题。![]()
稿源:(雷峰网)
【傻大方】网址:/c/1202b20K2021.html
标题:函数|Bengio 终于换演讲题目了!生成式主动学习如何让科学实验从寻找“一个分子”变为寻找“一类分子”?( 三 )