Pandas教程
 文章插图
文章插图
作为每个数据科学家都非常熟悉和使用的最受欢迎和使用的工具之一 , Pandas库在数据操作、分析和可视化方面非常出色
为了帮助你完成这项任务并对Python编码更加自信 , 我用Pandas上一些最常用的函数和方法创建了本教程 。 我真心希望这对你有用 。
目录
- 导入库
- 导入/导出数据
- 显示数据
- 基本信息:快速查看数据
- 基本统计
- 调整数据
- 布尔索引:loc
- 布尔索引:iloc
- 基本处理数据
泰坦尼克号的数据集可以在这里下载:
导入库为了我们的目的 , “Pandas”库是必须导入的
import pandas as pd导入/导出数据“泰坦尼克号数据集”指定为“data” 。a) 使用read_csv将csv文件导入 。 你应该在文件中添加数据的分隔符 。
data = http://kandian.youth.cn/index/pd.read_csv("file_name.csv", sep=';')b) 使用read_excel从excel文件读取数据 。data = http://kandian.youth.cn/index/pd.read_excel('file_name.xls')c) 将数据帧导出到csv文件 , 使用to_csvdata.to_csv("file_name.csv", sep=';', index=False)d) 使用“to_excel”将数据框导出到excel文件 。data.to_excel("file_name.xls′)显示数据a) 正在打印前n行 。 如果没有给定 , 则默认显示5行 。data.head() 文章插图
文章插图b) 打印最后“n”行 。 下面 , 显示最后7行 。
data.tail(7)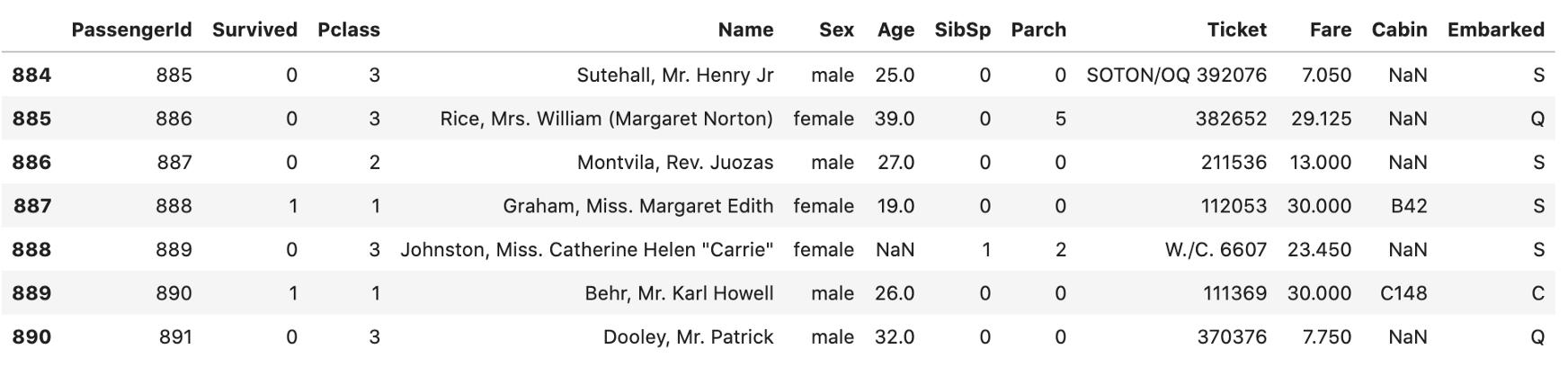 文章插图
文章插图基本信息:快速查看数据
a) 显示数据集的维度:总行数、列数 。
data.shape(891 , 12)b) 显示变量类型 。
data.dtypesPassengerIdint64Survivedint64Pclassint64NameobjectSexobjectAgefloat64SibSpint64Parchint64TicketobjectFarefloat64CabinobjectEmbarkedobjectdtype: objectc) 按升序值显示变量类型 。data.dtypes.sort_values(ascending=True)PassengerIdint64Survivedint64Pclassint64SibSpint64Parchint64Agefloat64Farefloat64NameobjectSexobjectTicketobjectCabinobjectEmbarkedobjectdtype: objectd) 按类型对变量计数 。data.dtypes.value_counts()object5int645float642dtype: int64e) 按升序值对每种类型计数 。data.dtypes.value_counts(ascending=True)float642int645object5dtype: int64f) 以绝对值检查生存者与非生存者的数量 。data.Survived.value_counts()05491342Name: Survived, dtype: int64g) 检查特征的比例 , 以百分比表示 。data.Survived.value_counts() / data.Survived.value_counts().sum()与以下相同:data.Survived.value_counts(normalize=True)00.61616210.383838Name: Survived, dtype: float64h) 检查特征的比例 , 以百分比表示 , 四舍五入 。data.Survived.value_counts(normalize=True).round(decimals=4) * 100061.62138.38Name: Survived, dtype: float64i) 评估数据集中是否存在缺失值 。data.isnull().values.any()Truej) 使用isnull()得到缺失值的数目 。data.isnull().sum()PassengerId0Survived0Pclass0Name0Sex0Age177SibSp0Parch0Ticket0Fare0Cabin687Embarked2dtype: int64k) 使用notnull()得到现有值的数目 。data.notnull().sum()PassengerId891Survived891Pclass891Name891Sex891Age714SibSp891Parch891Ticket891Fare891Cabin204Embarked889dtype: int64l) 按变量列出的缺失值的百分比(%) 。【Pandas教程】
data.isnull().sum() / data.isnull().shape[0] * 100等同于data.isnull().mean() * 100PassengerId0.000000Survived0.000000Pclass0.000000Name0.000000Sex0.000000Age19.865320SibSp0.000000Parch0.000000Ticket0.000000Fare0.000000Cabin77.104377Embarked0.224467dtype: float64m) 四舍五入(在示例中为2) 。(data.isnull().sum() / data.isnull().shape[0] * 100).round(decimals=2)等同于(data.isnull().mean() * 100).round(decimals=2)PassengerId0.00Survived0.00Pclass0.00Name0.00Sex0.00Age19.87SibSp0.00Parch0.00Ticket0.00Fare0.00Cabin77.10Embarked0.22dtype: float64n) 另外:用组合文本打印结果 。
- 占营收|华为值多少钱
- 商品|问道自有品牌,山姆多方博弈
- 公式|?有人把 5G 讲得这么简单明了
- 责令|1336款APP被责令整改,三大问题突出
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- 长庚君|向小米公司致歉
- “天河优创”放榜
- 广东移动OTN精智专网,助力千行百业数字化转型
- 快的秒回,慢的等了近一天
- 制药领域|为什么AI制药这么火,为什么是现在?