redis 数据类型详解 以及 redis适用场景场合( 二 )
获取字符串长度
往字符串append内容
设置和获取字符串的某一段内容
设置及获取字符串的某一位(bit)
批量设置一系列字符串的内容
【redis 数据类型详解 以及 redis适用场景场合】实现方式:String在redis内部存储默认就是一个字符串 , 被redisObject所引用 , 当遇到incr,decr等操作时会转成数值型进行计算 , 此时redisObject的encoding字段为int 。
Hash
常用命令:hget,hset,hgetall 等 。 应用场景:在Memcached中 , 我们经常将一些结构化的信息打包成HashMap , 在客户端序列化后存储为一个字符串的值 , 比如用户的昵称、年龄、性别、积分等 , 这时候在需要修改其中某一项时 , 通常需要将所有值取出反序列化后 , 修改某一项的值 , 再序列化存储回去 。 这样不仅增大了开销 , 也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分) 。 而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值 。 我们简单举个实例来描述下Hash的应用场景 , 比如我们要存储一个用户信息对象数据 , 包含以下信息:用户ID为查找的key , 存储的value用户对象包含姓名 , 年龄 , 生日等信息 , 如果用普通的key/value结构来存储 , 主要有以下2种存储方式: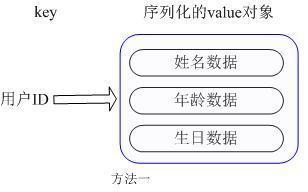 文章插图
文章插图
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储 , 这种方式的缺点是 , 增加了序列化/反序列化的开销 , 并且在需要修改其中一项信息时 , 需要把整个对象取回 , 并且修改操作需要对并发进行保护 , 引入CAS等复杂问题 。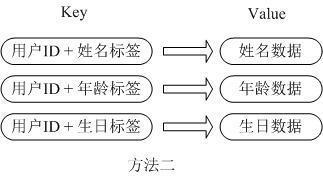 文章插图
文章插图
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对象 , 用用户ID+对应属性的名称作为唯一标识来取得对应属性的值 , 虽然省去了序列化开销和并发问题 , 但是用户ID为重复存储 , 如果存在大量这样的数据 , 内存浪费还是非常可观的 。 那么Redis提供的Hash很好的解决了这个问题 , Redis的Hash实际是内部存储的Value为一个HashMap , 并提供了直接存取这个Map成员的接口 , 如下图: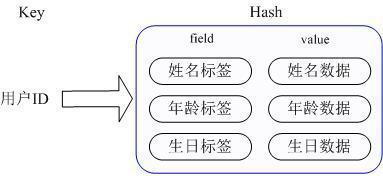 文章插图
文章插图
也就是说 , Key仍然是用户ID, value是一个Map , 这个Map的key是成员的属性名 , value是属性值 , 这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了 , 既不需要重复存储数据 , 也不会带来序列化和并发修改控制的问题 。 很好的解决了问题 。 这里同时需要注意 , Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多 , 那么涉及到遍历整个内部Map的操作 , 由于Redis单线程模型的缘故 , 这个遍历操作可能会比较耗时 , 而另其它客户端的请求完全不响应 , 这点需要格外注意 。 实现方式:上面已经说到Redis Hash对应Value内部实际就是一个HashMap , 实际这里会有2种不同实现 , 这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储 , 而不会采用真正的HashMap结构 , 对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht 。
List
常用命令:lpush,rpush,lpop,rpop,lrange等 。 应用场景:Redis list的应用场景非常多 , 也是Redis最重要的数据结构之一 , 比如twitter的关注列表 , 粉丝列表等都可以用Redis的list结构来实现 。 Lists 就是链表 , 相信略有数据结构知识的人都应该能理解其结构 。 使用Lists结构 , 我们可以轻松地实现最新消息排行等功能 。 Lists的另一个应用就是消息队列 , 可以利用Lists的PUSH操作 , 将任务存在Lists中 , 然后工作线程再用POP操作将任务取出进行执行 。 Redis还提供了操作Lists中某一段的api , 你可以直接查询 , 删除Lists中某一段的元素 。 实现方式:Redis list的实现为一个双向链表 , 即可以支持反向查找和遍历 , 更方便操作 , 不过带来了部分额外的内存开销 , Redis内部的很多实现 , 包括发送缓冲队列等也都是用的这个数据结构 。
Set
常用命令:sadd,spop,smembers,sunion 等 。 应用场景:Redis set对外提供的功能与list类似是一个列表的功能 , 特殊之处在于set是可以自动排重的 , 当你需要存储一个列表数据 , 又不希望出现重复数据时 , set是一个很好的选择 , 并且set提供了判断某个成员是否在一个set集合内的重要接口 , 这个也是list所不能提供的 。 Sets 集合的概念就是一堆不重复值的组合 。 利用Redis提供的Sets数据结构 , 可以存储一些集合性的数据 , 比如在微博应用中 , 可以将一个用户所有的关注人存在一个集合中 , 将其所有粉丝存在一个集合 。 Redis还为集合提供了求交集、并集、差集等操作 , 可以非常方便的实现如共同关注、共同喜好、二度好友等功能 , 对上面的所有集合操作 , 你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中 。 实现方式:set 的内部实现是一个 value永远为null的HashMap , 实际就是通过计算hash的方式来快速排重的 , 这也是set能提供判断一个成员是否在集合内的原因 。
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 介绍|5分钟介绍各种类型的人工智能技术
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元