点云分类的自动放大框架 PointAugment( 二 )
(2)点云数据放大
在现有的点处理网络中 , 数据放大主要包括围绕重力轴的随机旋转、随机缩放和随机抖动[23,24] 。 这些手工制定的规则在整个训练过程中都是固定的 , 因此可能无法获得最佳样本来有效地训练网络 。 到目前为止 , 还没有发现有任何研究利用三维点云来实现网络学习最大化的工作 。
(3)点云深度学习
在 PointNet 架构的基础上 , 有几篇文章[24 , 17 , 18]探索了局部结构来放大特征学习 。 另一些人通过创建局部图[36,37,29,45]或几何元素[11,22]来探索图形卷积网络 。 另一个工作流程[32 , 34 , 19]将不规则点投影到规则空间中 , 以允许传统的卷积神经网络工作 。 与上述工作不同 , 目标不是设计一个新的网络 , 而是通过有效地优化点云样本的增加来提高现有网络的分类性能 。 为此 , 设计了一个放大器来学习一个特殊的放大函数 , 并根据分类器的学习进度调整放大函数 。
3. Overview这项工作的主要贡献是 PointAugment 框架 , 该框架自动优化输入点云样本的放大 , 以便更有效地训练分类网络 。 图 2 说明了框架的设计 , 有两个深层神经网络组件:(i)一个放大器 A 和(ii)一个分类器 C 。
在阐述 PointAugment 框架之前 , 首先讨论框架背后的关键思想 。 这些都是新的想法(在以前的作品[3,14,8]中没有出现) , 使能够有效地增加训练样本 , 这些样本现在是三维点云 , 而不是二维图像 。
- 样本感知 。 目标是通过考虑样本的基本几何结构 , 为每个输入样本回归一个特定的放大函数 , 而不是为每个输入数据样本找到一套通用的放大策略或过程 。 称之为样本感知的自动放大 。
- 2D 与 3D 放大 。 与二维图像放大不同 , 三维放大涉及更广阔和不同的空间域 。 应该考虑云的两种变形点(包括点云的变换和点云的变换)的放大(包括点云的变换和点云的变换) 。
- 联合优化 。 在网络训练过程中 , 分类器将逐渐学习并变得更加强大 , 因此需要更具挑战性的放大样本 , 以便更好地训练分类器 , 因为分类器变得更强 。 因此 , 以端到端的方式设计和训练 PointAugment 框架 , 这样就可以共同优化放大器和分类器 。 为此 , 必须仔细设计损失函数 , 动态调整增加样本的难度 , 同时考虑输入样本和分类器的容量 。
4.1. Network Architecture放大器 。 不同于现有的工作[3 , 14 , 8] , 放大器是样本感知的 , 学习生成一个特定的函数来放大每个输入样本 。 从现在起 , 为了便于阅读 , 去掉了下标 i , 并将 P 表示为 A 的训练样本输入 , P′表示 A 的相应放大样本输出 。 放大器的总体架构如图 3(上图)所示 。
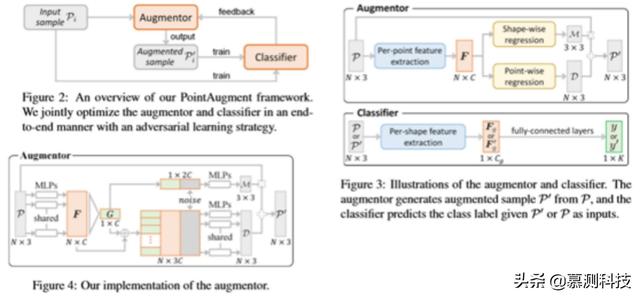 文章插图
文章插图4.2. Augmentor loss为了使网络学习最大化 , 由放大器生成的放大样本 P′应满足两个要求:(i)P′比 P 更具挑战性 , 即目标是 L(P′)≥L(P);(ii)P′不应失去形状特异性 , 这意味着应该描述一个与 P 不太远(或不同)的形状 。 为了达到要求(i) , 一个简单的方法来描述放大器(表示为 LA)的损失函数是使 P 和 P′上的交叉熵损失之差最大化 , 或者等效地最小化 。
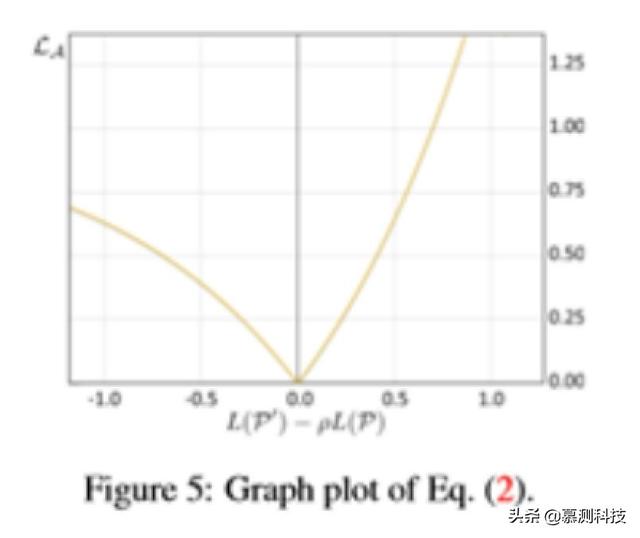 文章插图
文章插图4.3. Classi?er loss分类 C 的目标是正确预测 P 和 P′ 。 另外 , 无论输入 P 或 P′ , C 都应该具有学习稳定的每形状全局特征的能力 。
4.4. End-to-end training strategy算法 1 总结了端到端训练策略 。 总的来说 , 在训练过程中 , 该程序交替地优化和更新放大器 A 和分类器 C 中的可学习参数 , 同时调整另一个参数 。
4.5. Implementation details使用 PyTorch[21]实现 PointAugment 。 具体来说 , 将训练阶段的数量设为 S=250 , 批量大小为 B=24 。 为了训练放大器 , 采用了学习率为 0.001 的 Adam 优化器 。 为了训练分类人员 , 遵循发布的代码和文件中各自的原始配置 。 具体来说 , 对于 PointNet、PointNet++和 RSCNN , 使用的 Adam 优化器的初始学习率为 0.001 , 该值逐渐降低 , 每 20 个时期衰减率为 0.5 。
对于 DGCNN , 使用动量为 0.9、基本学习率为 0.1 的 SGD 解算器 , 该解算器使用余弦退火策略衰减[9] 。 还需要注意的是 , 为了减少模型振荡[5] , 遵循[31]使用混合训练样本来训练点放大 , 混合训练样本包含一半原始训练样本 , 另一半包含先前放大的样本 , 而不是只使用原始训练样本 。 详见[31] 。 此外 , 为了避免过度拟合 , 设置了 0.5 的脱落概率来随机丢弃或保持回归的形状方向变换和点方向位移 。 在测试阶段 , 遵循之前的网络[23 , 24] , 将输入的测试样本输入到经过训练的分类器 , 以获得预测的标签 , 而不需要任何额外的计算成本 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面