点云分类的自动放大框架 PointAugment
摘要【点云分类的自动放大框架 PointAugment】本文提出了一种新的自动放大框架 PointAugment , 在训练分类网络时 , 自动优化和放大点云样本 , 以丰富数据的多样性 。 与现有的二维图像自动放大方法不同 , PointAugment 是一种样本感知的方法 , 采用一种对抗性学习策略来联合优化放大器网络和分类器网络 , 使放大器能够学习产生最适合分类器的放大样本 。 此外 , 构造了一个带形状变换和点位移的可学习点放大函数 , 并根据分类器的学习进度 , 精心设计损失函数来采用放大样本 。 大量实验也证实了 PointAugment 的有效性和鲁棒性 , 可以改善各种网络的形状分类和检索性能 。
1.介绍近 24 年来 , 人对三维神经网络的研究兴趣与日俱增 。 可靠地训练网络通常依赖于数据的可用性和多样性 。 然而 , 与 ImageNet 和 MS-COCO 数据集等二维图像基准测试不同 , 3D 数据集的数量通常要小得多 , 标签数量相对较少 , 多样性有限 。 例如 , ModelNet40 是 3D 点云分类最常用的基准之一 , 只有 40 个类别的 12311 个模型 。 有限的数据量和多样性可能导致过拟合问题 , 进而影响网络的泛化能力 。 目前 , 数据放大(DA)是一种非常普遍的策略 , 通过人工增加训练样本的数量和多样性来避免过度拟合 , 提高网络泛化能力 。 对于三维点云 , 由于训练样本数量有限 , 且在 3D 中有巨大的放大空间 , 传统的 DA 策略[23 , 24]通常只是在一个小的、固定的预先定义的放大范围内随机扰动输入点云 , 以保持类标签 。
尽管这种传统的 DA 方法对现有的分类网络有效 , 但可能导致训练不足 , 如下所述 。 首先 , 现有的深部三维点云处理方法将网络训练和数据采集视为两个独立的阶段 , 没有联合优化 , 例如反馈训练结果以放大 DA 。 因此 , 训练后的网络可能是次优的 。 其次 , 现有方法对所有输入点云样本应用相同的固定放大过程 , 包括旋转、缩放和/或抖动 。 在放大过程中忽略了样本的形状复杂度 , 例如 , 球体无论如何旋转都保持不变 , 但复杂形状可能需要更大的旋转 。 因此 , 传统的 DA 对于增加训练样本可能是多余的或不充分的 。
为了改进点云样本的放大 , 提出了一种新的三维点云自动放大框架 PointAugment , 并展示了其放大形状分类的有效性;见图 1 。 与以前的二维图像不同 , PointAugment 学习生成特定于单个样本的放大函数 。 此外 , 可学习的放大函数同时考虑了形状变换和点方向位移 , 这与三维点云样本的特征有关 。 此外 , PointAugment 通过一种对抗性学习策略 , 将放大网络(augmentor)与分类网络(Classifier)进行端到端的训练 , 从而与网络训练共同优化放大过程 。 通过将分类损失作为反馈 , 放大器可以学习通过扩大类内数据变化来丰富输入样本 , 而分类器可以学习通过提取不敏感特征来克服这一问题 。 受益于这种对抗性学习 , 放大器可以学习生成在不同训练阶段最适合分类者的放大样本 , 从而最大限度地提高分类者的能力 。 作为探索 3D 点云自动放大的第一次尝试 , 展示了通过用 PointAugment 取代传统的 DA , 可以在四个具有代表性的网络上实现对 ModelNet40(见图 1)和 SHREC16(见第 5 节)数据集的形状分类的明显改进 , 包括 PointNet、PointNet++ , RSCNN 和 DGCNN 。 此外 , 还展示了 PointAugment 在形状检索上的有效性 , 并评估了其鲁棒性、损失配置和模块化设计 。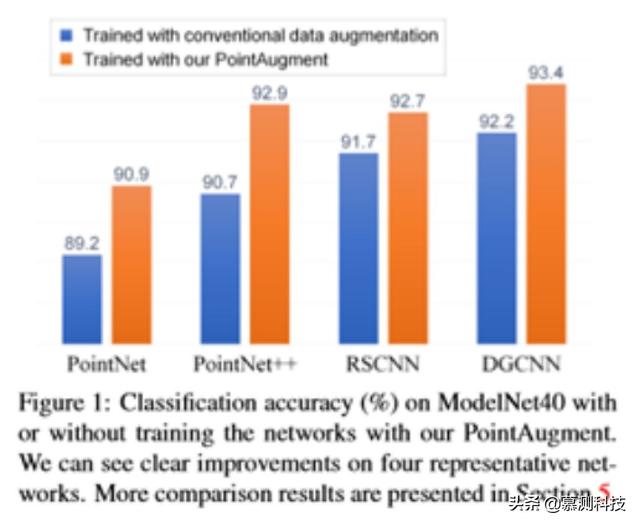 文章插图
文章插图
2.相关工作(1)图像数据放大
训练数据对深层神经网络学习执行任务起着非常重要的作用 。 然而 , 与现实世界的复杂性相比 , 训练数据的数量往往是有限的 , 因此经常需要数据放大来放大训练集 , 最大限度地利用训练数据学习到的知识 。 一些工作没有随机变换训练数据样本[42,41] , 而是尝试利用图像组合[12]、生成对抗网络[31,27]、贝叶斯优化[35]和潜在空间中的图像插值[4,16,2]从原始数据中生成放大样本 。 然而 , 这些方法可能产生与原始数据不同的不可靠样本 。 另一方面 , 一些图像 DA 技术[12,42,41]对具有规则结构的图像应用像素插值 , 但是不能处理顺序不变的点云 。 另一种方法的目的是找到一个预先定义的转换函数的最佳组合 , 以增加训练样本 , 而不是基于人工设计或完全随机性应用转换函数 。
AutoAugment 提出了一种强化学习策略 , 通过交替训练代理任务和策略控制器 , 然后将学习到的放大函数应用于输入数据 , 从而找到最佳的放大函数集 。 不久之后 , 另两项研究 , FastAugment 和 PBA 探索了先进的超参数优化方法 , 以更有效地找到放大的最佳转换 。 与这些学习为所有训练样本找到固定的放大策略的方法不同 , PointAugment 是样本感知的 , 这意味着在训练过程中根据单个训练样本的属性和网络能力动态生成转换函数 。 最近 , Tang 等人张等建议学习使用对抗策略的目标任务的放大策略 。 倾向于直接最大化增加样本的损失 , 以提高图像分类网络的泛化能力 。 与之不同的是 , PointAugment 通过一个明确设计的边界扩大了放大后的点云与原始点云之间的损失;动态地调整了放大样本的难度 , 以便放大的样本能够更好地满足不同训练阶段的分类要求 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面