输出层|PyTorch可视化理解卷积神经网络( 二 )
在计算机中 , 使用一组位于0到255范围内的像素值来解释图像 。 计算机查看这些像素值并理解它们 。 乍一看 , 它并不知道图像中有什么物体 , 也不知道其颜色 。 它只能识别出像素值 , 图像对于计算机来说就相当于一组像素值 。 之后 , 通过分析像素值 , 它会慢慢了解图像是灰度图还是彩色图 。 灰度图只有一个通道 , 因为每个像素代表一种颜色的强度 。 0表示黑色 , 255表示白色 , 二者之间的值表明其它的不同等级的灰灰色 。 彩色图像有三个通道 , 红色、绿色和蓝色 , 它们分别代表3种颜色(三维矩阵)的强度 , 当三者的值同时变化时 , 它会产生大量颜色 , 类似于一个调色板 。 之后 , 计算机识别图像中物体的曲线和轮廓 。。
【输出层|PyTorch可视化理解卷积神经网络】下面使用PyTorch加载数据集并在图像上应用过滤器:
# Load the librariesimport torchimport numpy as npfrom torchvision import datasetsimport torchvision.transforms as transforms# Set the parametersnum_workers = 0batch_size = 20# Converting the Images to tensors using Transformstransform = transforms.ToTensor()train_data = http://kandian.youth.cn/index/datasets.MNIST(root='data', train=True, download=True, transform=transform)test_data = http://kandian.youth.cn/index/datasets.MNIST(root='data', train=False, download=True, transform=transform)# Loading the Datatrain_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=num_workers)test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,num_workers=num_workers)import matplotlib.pyplot as plt%matplotlib inline dataiter = iter(train_loader)images, labels = dataiter.next()images = images.numpy()# Peeking into datasetfig = plt.figure(figsize=(25, 4))for image in np.arange(20): ax = fig.add_subplot(2, 20/2, image+1, xticks=[], yticks=[]) ax.imshow(np.squeeze(images[image]), cmap='gray') ax.set_title(str(labels[image].item())) 文章插图
文章插图
下面看看如何将单个图像输入神经网络中:
img = np.squeeze(images[7])fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111)ax.imshow(img, cmap='gray')width, height = img.shapethresh = img.max()/2.5for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]上述代码将数字'3'图像分解为像素 。 在一组手写数字中 , 随机选择“3” 。 并且将实际像素值(0-255 )标准化 , 并将它们限制在0到1的范围内 。 归一化的操作能够加快模型训练收敛速度 。
构建过滤器
过滤器 , 顾名思义 , 就是过滤信息 。 在使用CNN处理图像时 , 过滤像素信息 。 为什么需要过滤呢 , 计算机应该经历理解图像的学习过程 , 这与孩子学习过程非常相似 , 但学习时间会少的多 。 简而言之 , 它通过从头学习 , 然后从输入层传到输出层 。 因此 , 网络必须首先知道图像中的所有原始部分 , 即边缘、轮廓和其它低级特征 。 检测到这些低级特征之后 , 传递给后面更深的隐藏层 , 提取更高级、更抽象的特征 。 过滤器提供了一种提取用户需要的信息的方式 , 而不是盲目地传递数据 , 因为计算机不会理解图像的结构 。 在初始情况下 , 可以通过考虑特定过滤器来提取低级特征 , 这里的滤波器也是一组像素值 , 类似于图像 。 可以理解为连接卷积神经网络中的权重 。 这些权重或滤波器与输入相乘以得到中间图像 , 描绘了计算机对图像的部分理解 。 之后 , 这些中间层输出将与多个过滤器相乘以扩展其视图 。 然后提取到一些抽象的信息 , 比如人脸等 。
就“过滤”而言 , 我们有很多类型的过滤器 。 比如模糊滤镜、锐化滤镜、变亮、变暗、边缘检测等滤镜 。
下面用一些代码片段来理解过滤器的特征:
Import matplotlib.pyplot as pltImport matplotib.image as mpimgImport cv2Import numpy as npImage = mpimg.imread(‘dog.jpg’)Plt.imshow(image)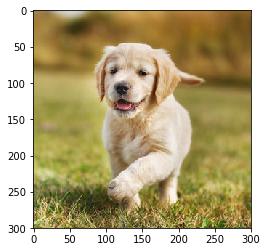 文章插图
文章插图
# 转换为灰度图gray = cv2.cvtColor(image, cv2.COLOR_RB2GRAY)# 定义sobel过滤器sobel = np.array([-1, -2, -1],[0, 0, 0],[1, 2, 1]))# 应用sobel过滤器Filtered_image = cv2.filter2D(gray, -1, sobel_y)# 画图Plt.imshow(filtered_image, cmp=’gray’)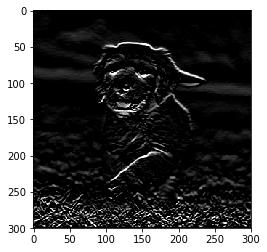 文章插图
文章插图
以上是应用sobel边缘检测滤镜后图像的样子 ,可以看到检测出轮廓信息 。
完整的CNN结构
到目前为止 , 已经看到了如何使用滤镜从图像中提取特征 。 现在要完成整个卷积神经网络 , cnn使用的层是:
- 前辈|八层板PCB展示,电脑主板PCB美图展示
- ColorOS、MIUI宿命对决:差距不只是底层,还有这方面
- 科天云远程音视频技术助企业数字化转型更上层楼
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理
- 在Linux系统中安装深度学习框架Pytorch
- 网络层(TCP/IP协议)
- 自学电脑我来教你,必修掌握的ATX电源输出原理。
- 一款强大的音源输出工具
- 从底层理解this是什么
- 基层|全省首个、全国首创!萧山区发布城市大脑数字驾驶舱3.0版!打通基层数字治理“最后一公里”